




 本文介绍在CDH集群中遇到硬盘坏道时的处理流程。包括如何检测坏道硬盘、从集群中移除故障硬盘、刷新集群配置使数据均衡、更换硬盘并重新加入集群等步骤。
本文介绍在CDH集群中遇到硬盘坏道时的处理流程。包括如何检测坏道硬盘、从集群中移除故障硬盘、刷新集群配置使数据均衡、更换硬盘并重新加入集群等步骤。
- 背景
因CDH数据交互比较频繁,硬盘的消耗较快,硬盘正常使用3年后容易出现硬盘坏道,为了避免硬盘坏道过多导致影响业务,经在测试环境中测试更换CDH集群节点硬盘后数据块未出现丢失现象。
- 实施步骤(测试环境node5节点进行测试):
- 查找异常硬盘挂载目录
目前是望京CDH平台node9的/dev/sdb1硬盘有坏道,所挂载的目录是/dfs/dn2
-
- Web操作该节点去掉对应目录
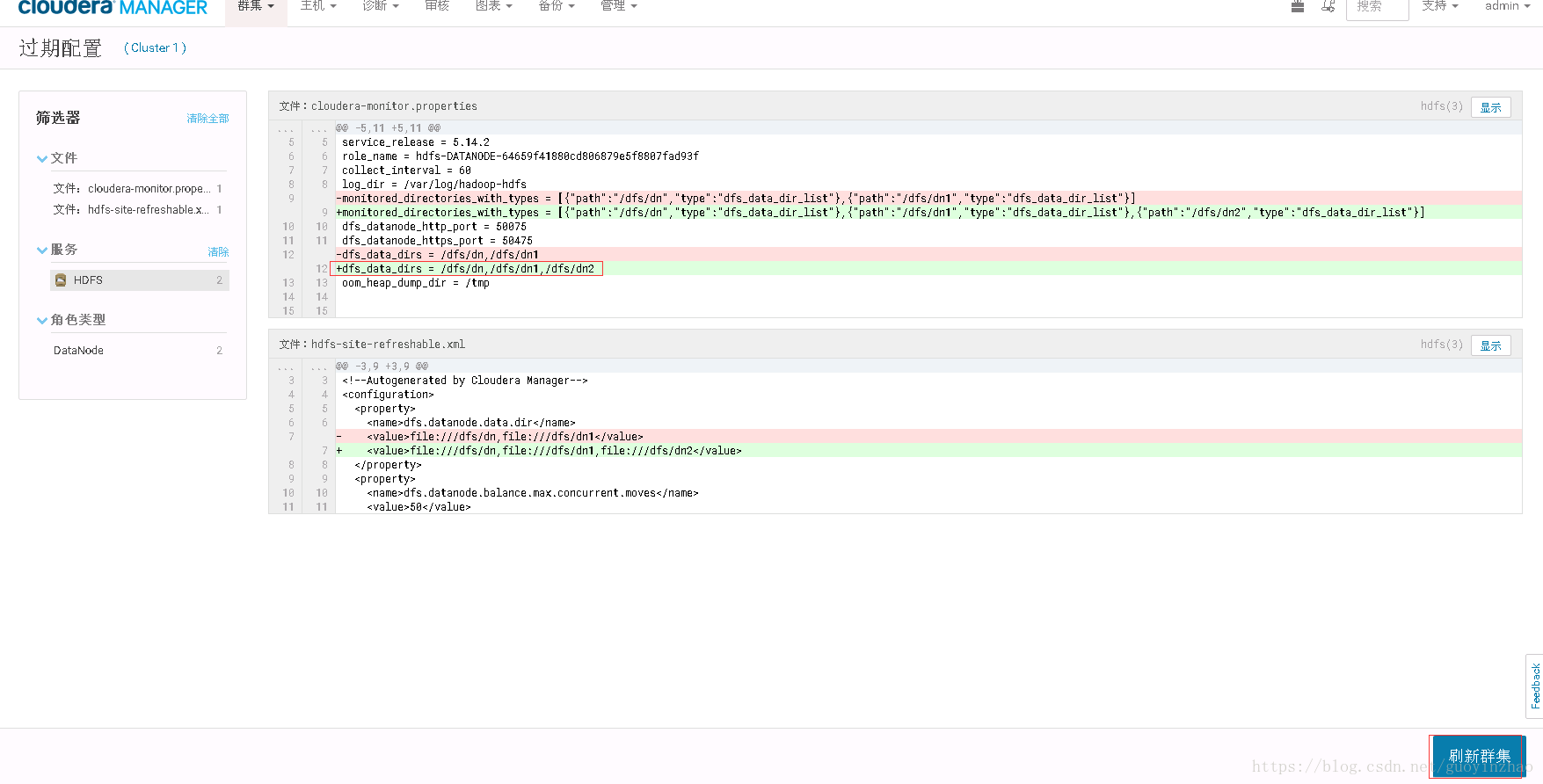
进入node9节点的DataNode服务的配置界面去掉/dfs/dn2目录
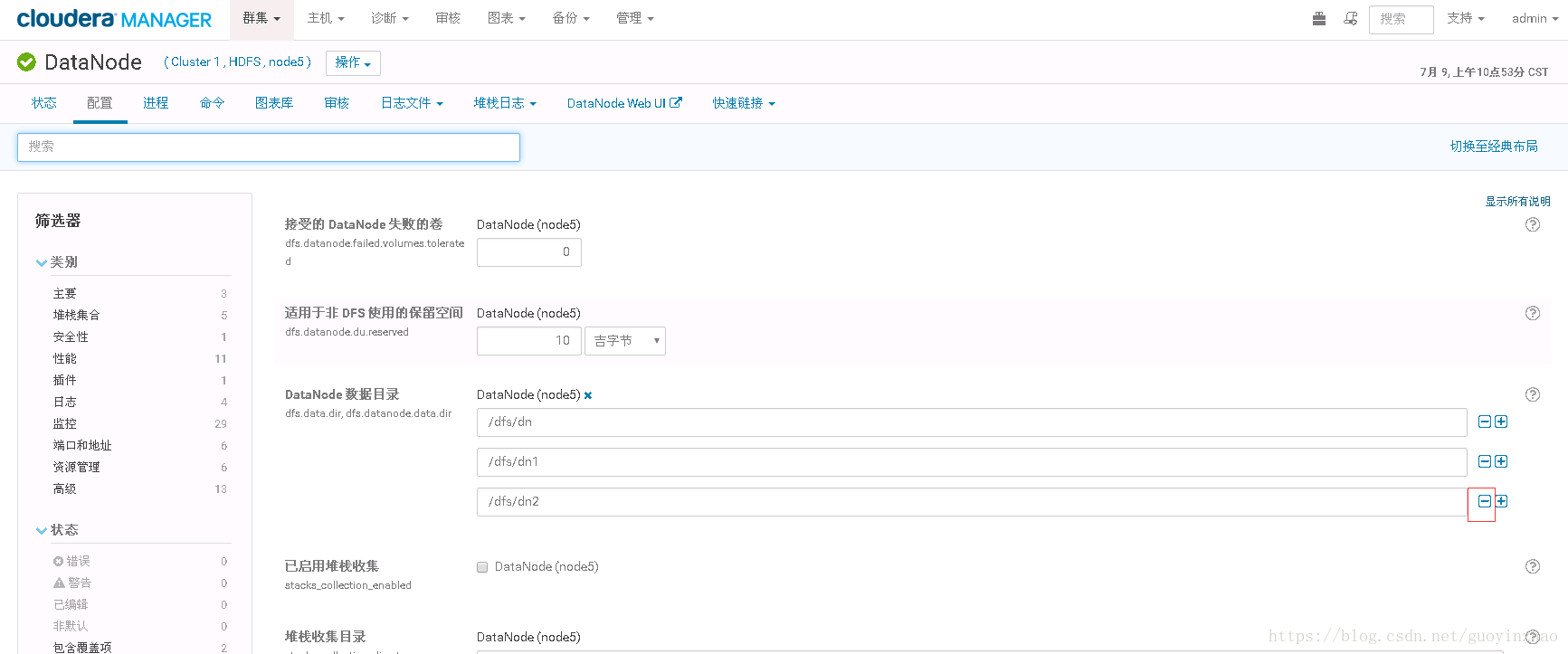
-
- 刷新集群(过期配置)
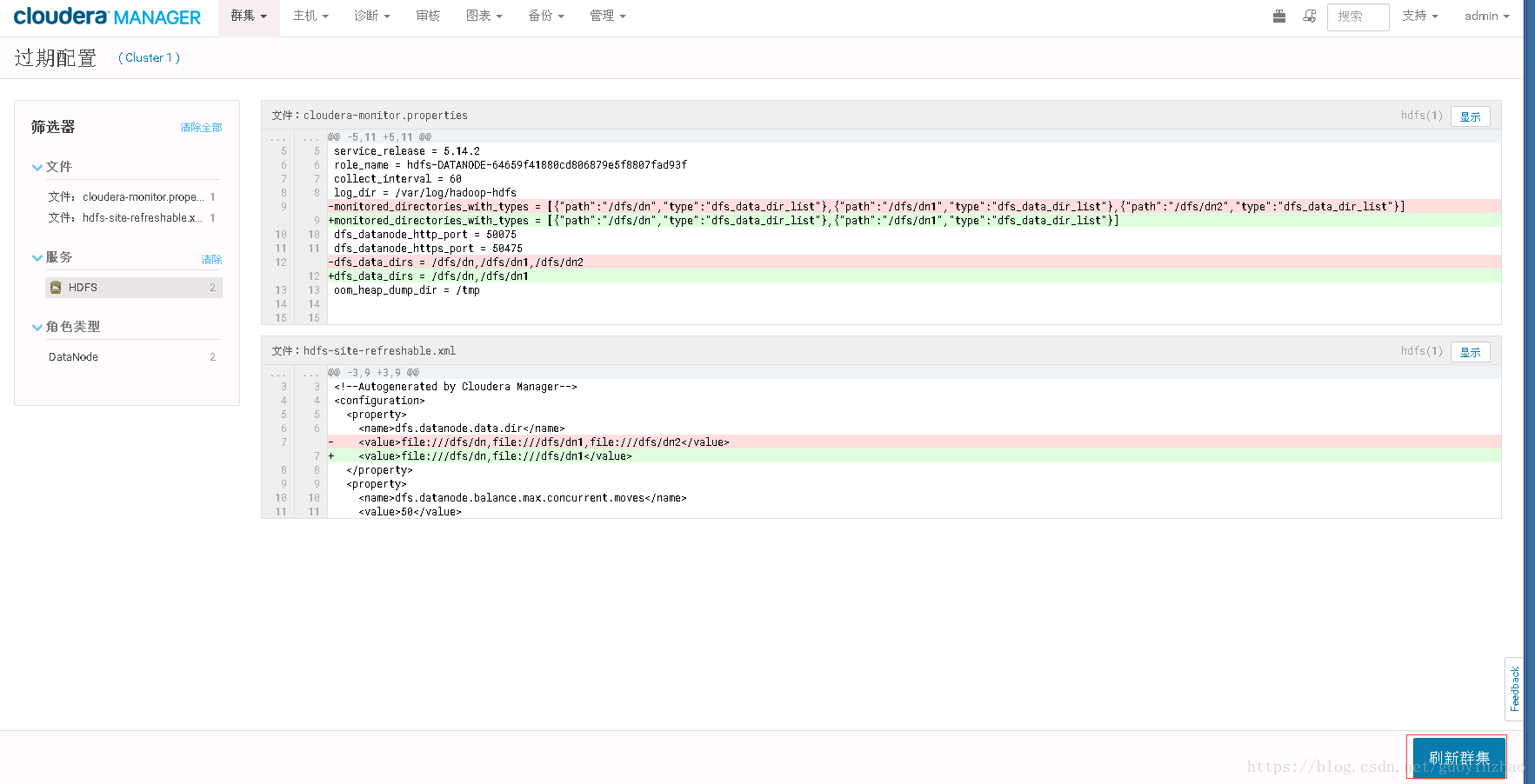
在刷新集群过程中dn2的数据块逐步向dn和dn1目录复制
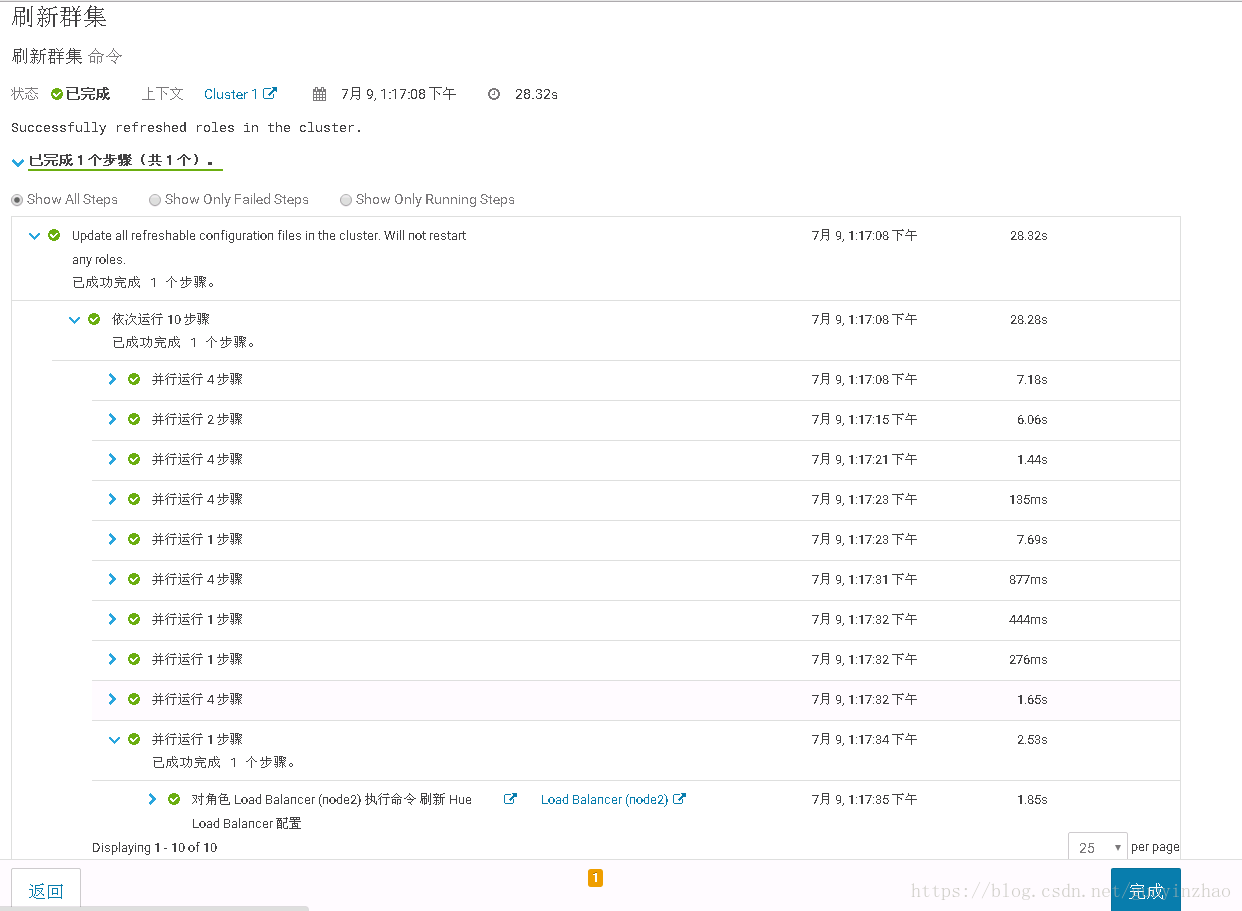
在刷新集群过程中dn2的数据块逐步向dn和dn1目录复制
- 检测
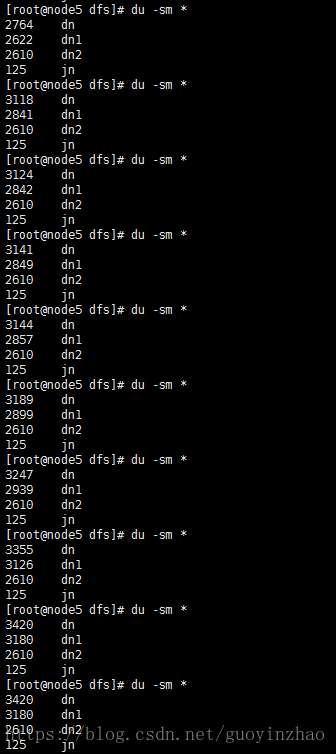
- 在数据平衡过程中可观察到数据块丢失比例在逐步减少
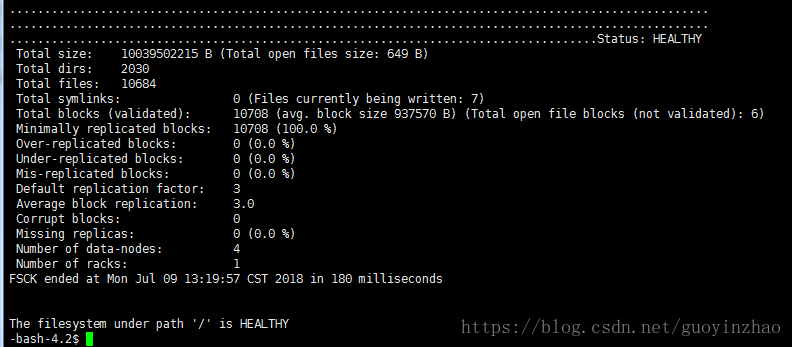
检测方法:hadoop fsck /
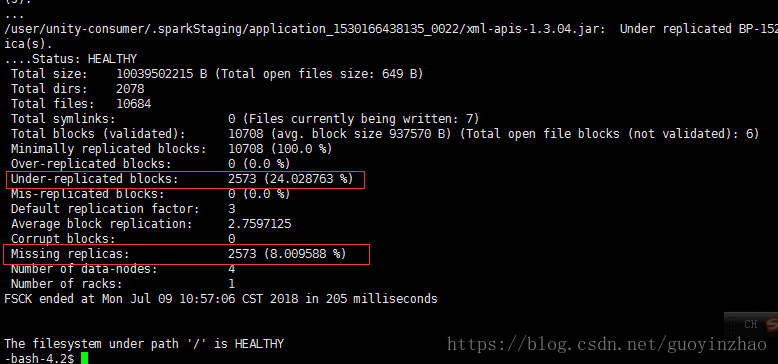
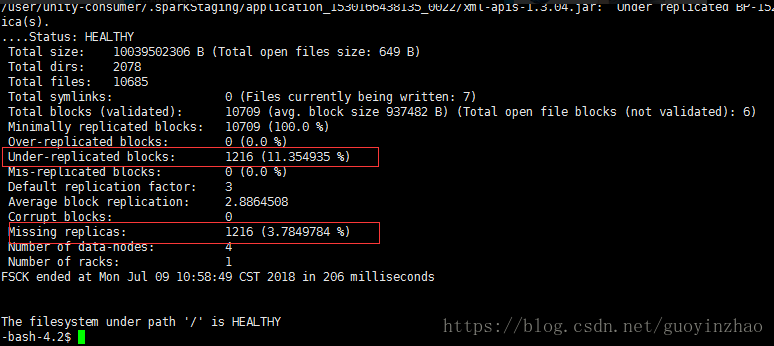
-
- 平衡完成后数据块检测正常
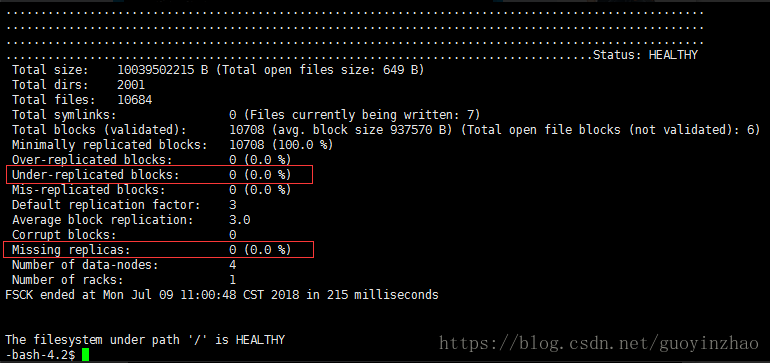
-
- 研发测确认是否有数据丢失
- 更换硬盘,web重新增加dn2目录
- 更换新硬盘,重新挂载dn2目录后,dn2目录归属root权限,需调整为hdfs权限
chown hdfs.hadoop /dfs/ -R
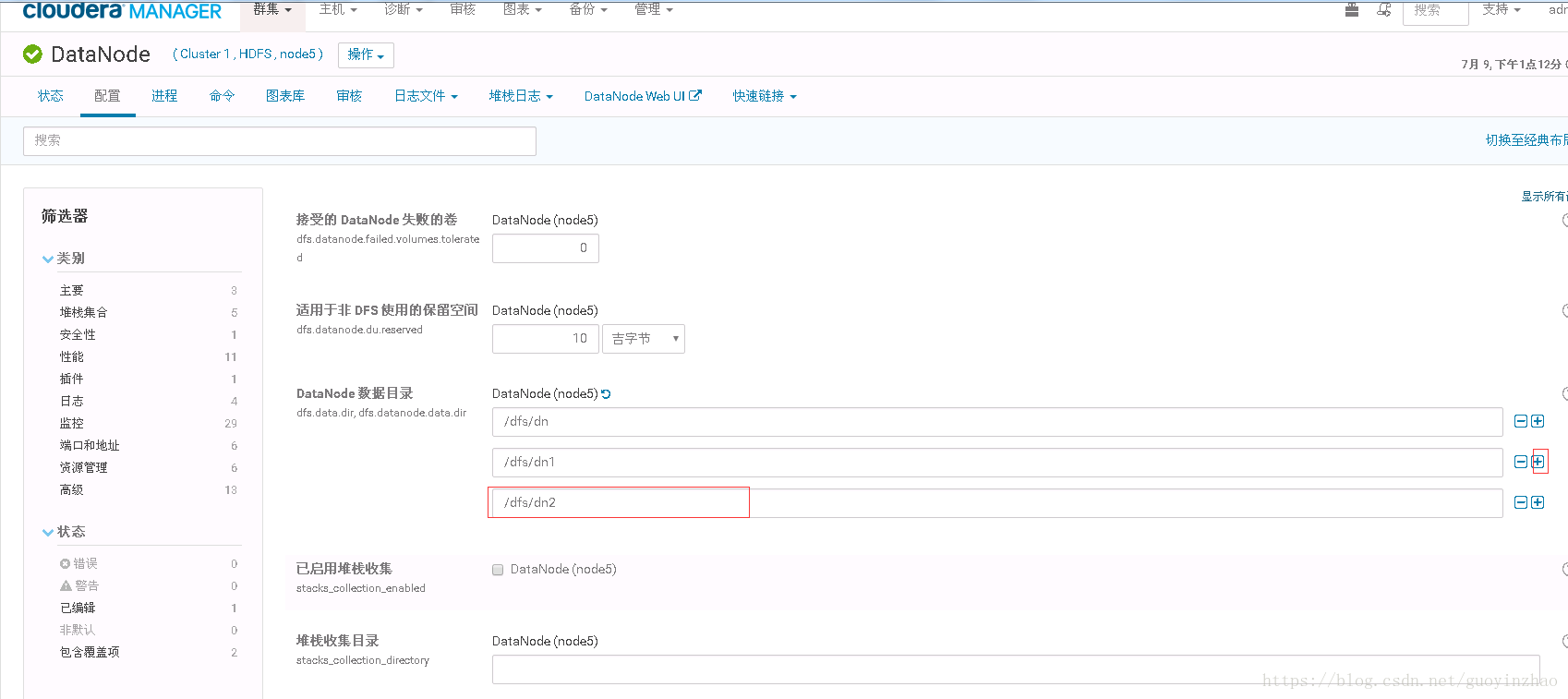
-
- 重新刷新集群(详见2.3)
-
- 检查数据块是否有丢失

















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









