









 本文详细介绍如何在Hadoop环境下安装和配置Spark集群,包括Scala的安装、Spark环境变量设置、集群配置文件调整及日志级别设定等关键步骤。
本文详细介绍如何在Hadoop环境下安装和配置Spark集群,包括Scala的安装、Spark环境变量设置、集群配置文件调整及日志级别设定等关键步骤。
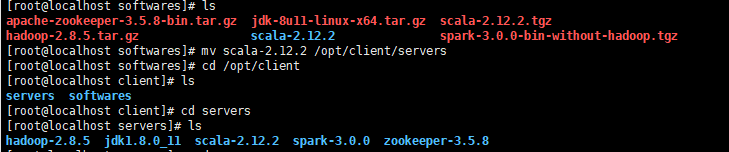
安装好hadoop后开始安装spark,
首先安装scala2.12.2.上传后解压
vim /etc/profile
export SCALA_HOME=/opt/client/servers/scala-2.12.2
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
scala -version验证是否安装成功

解压spark到安装目录
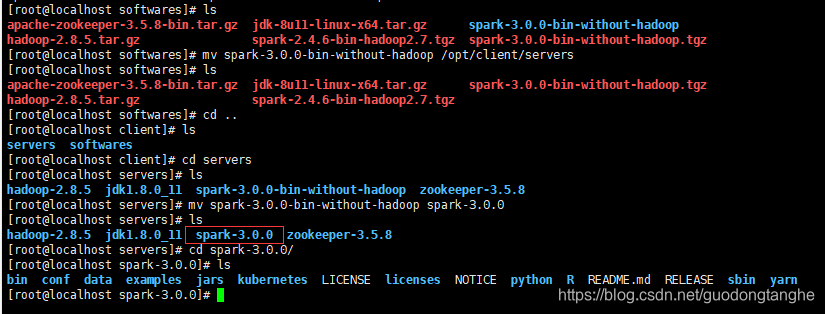
修改/etc/profile文件
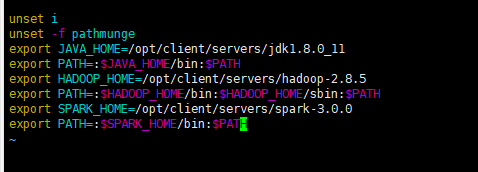
export SPARK_HOME=/opt/client/servers/spark-3.0.0
export PATH=:$SPARK_HOME/bin:$PATH
source /etc/profile
复制spark-env.sh.template成spark-env.sh

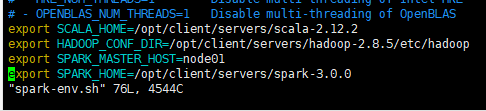
修改spark-env.sh
export SCALA_HOME=/opt/client/servers/scala-2.12.2
export HADOOP_CONF_DIR=/opt/client/servers/hadoop-2.8.5/etc/hadoop
export SPARK_MASTER_HOST=node01
export SPARK_HOME=/opt/client/servers/spark-3.0.0
复制slaves并修改内容


把文件发送给另外两台
scp -r scala-2.12.2 node02:$PWD
scp -r scala-2.12.2 node03:$PWD
scp -r spark-3.0.0 node02:$PWD
scp -r spark-3.0.0 node03:$PWD
修改spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:9000/historyserverforSpark
spark.yarn.historyServer.address node01:18080
spark.history.fs.logDirectory hdfs://node01:9000/historyserverforSpark
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
下载log4j的jar包
https://blog.youkuaiyun.com/Zsigner/article/details/104829562
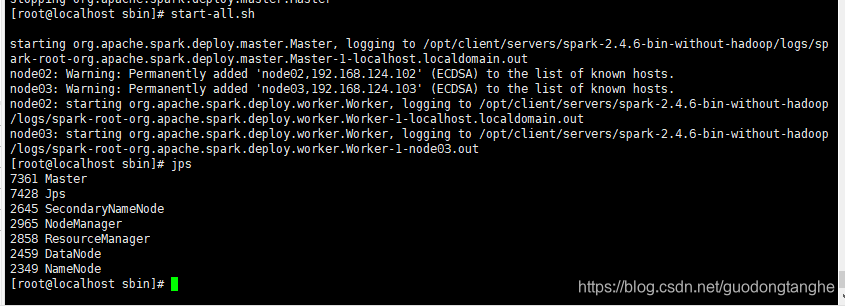
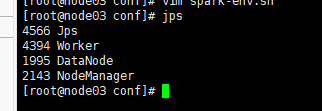
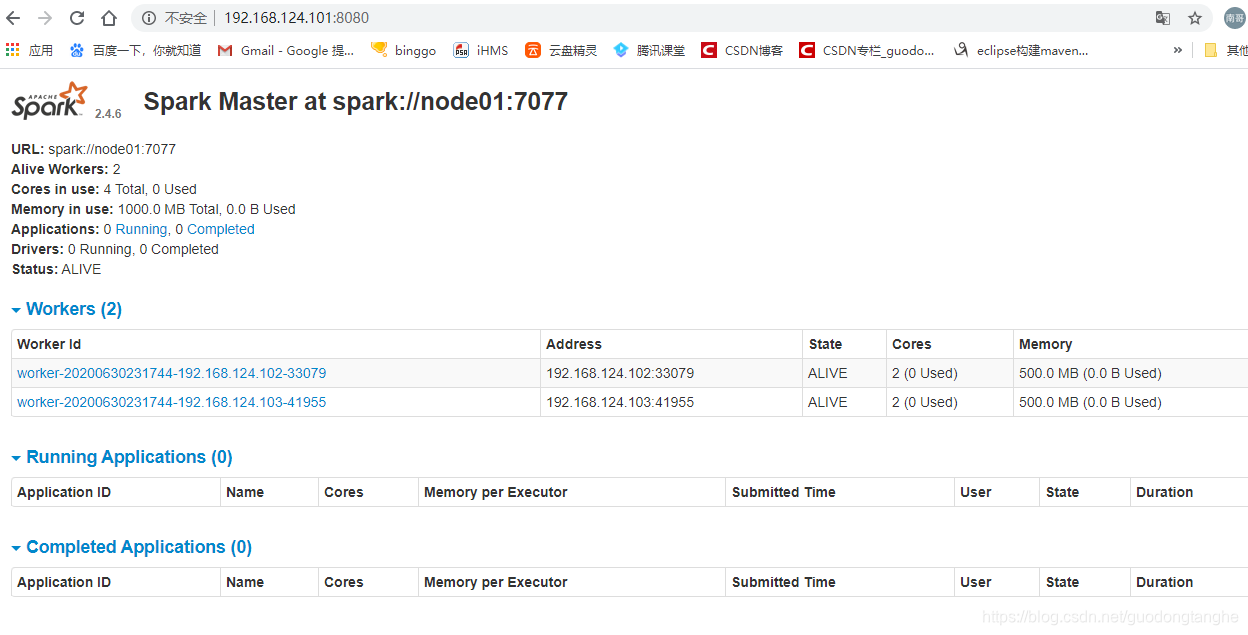
node1节点的spark-sbin目录下执行start-all.sh


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









