




1.认识Python
Python的特点
Python是完全面向对象的语言
函数、模块、数字、字符串都是对象,在Python中一切皆对象
完全支持继承、重载、多重继承
支持重载运算符,也支持泛型设计
拥有一个强大的标准库
Python 语言的核心只包含数字、字符串、列表、字典、文件等常见类型和函数,而由Python标准库提供了系统管理、网络通信、文本处理、数据库接口、图形系统、XML 处理等额外的功能.
Python社区提供了大量的第三方模块,使用方式与标准库类似
它们的功能覆盖科学计算、人工智能、机器学习、Web 开发、数据库接口、图形系统 多个领域.
编译与解释
编译(静态语言):程序在执行之前需要一个专门的编译过程,把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如 C、C++、java
解释(脚本语言):以文本方式存储程序代码,会将代码一句一句直接运行。在发布程序时,看起来省了道编译工序,但是在运行程序的时候,必须先解释再运行(将源代码逐条翻译成目标代码同时逐条运行),如Python 、Java Script、PHP
- 速度 —— 编译型语言比解释型语言执行速度快
- 跨平台性 —— 解释型语言比编译型语言跨平台性好
执行python程序的方式
(1)解释器python/python3
Python 2.x 使用的解释器是 ipython
Python 3.x 使用的解释器是 ipython3
(2)交互式运行Python程序:对每个输入语句即时运行结果
默认:python shell
优点:适合于学习/验证 Python 语法或者局部代码
缺点:•代码不能保存
•不适合运行太大的程序
IPython:◦支持自动补全
◦自动缩进
◦支持 bash shell 命令
◦内置了许多很有用的功能和函数
退出解释器:①直接输入 exit②按热键 ctrl + d,IPython 会询问是否退出解释器
(3)Python的IDE - PyCharm:文件式编程,批量处理一组语句并运行结果,这是编程的主要方式
集成开发环境:图形用户界面、代码编辑器(支持代码补全/自动缩进)、编译器/解释器、调试器(断点/单步执行)
- 一个项目通常会包含 很多源文件
- 每个 源文件 的代码行数是有限的,通常在几百行之内
- 每个源文件各司其职,共同完成复杂的业务功能
(4)cmd运行python脚本
前置条件:先在windows设置python环境变量
进入cmd:
- cd D:\python+selenium\TestCase (py文件存放的路径)
- 输入python **.py 直接执行某某py文件,比如:python “E:\private\...\TextProBarV2.py
Python和pip
首先下载安装好python,命令行判断:
python是否安装成功和安装版本:输入python
检查是否安装了pip:输入pip
注意配置好环境变量(Python安装地址)。
环境变量分为系统环境变量和用户环境变量。
正常所说的环境变量是指系统环境变量,对所有用户起作用,而用户环境变量只对当前用户起作用,如果此电脑登入了另外个用户账号,那配置之前账号的用户环境变量就对另外个用户账号不起作用。
优先级高低是:系统变量 > 用户变量。也就是说,环境变量设置相同,先在系统变量里面找,找不到再到用户变量里面去找。
而在一个环境变量里面,如果有多个值,优先级是最前面的或者最上面的项优先级高。比如在Path环境变量里面,同时设置了python2.7和python3.6的路径,结果是先设置的起作用,这对于切换使用不同版本的软件比较方便,只需要上移/下移就行。
举例:
Python和pip环境变量,添加到path:
C:\Program Files\Python380
C:\Program Files\Python380\Scripts
pip
pip <command> [options]
进入cmd,输入pip,可以查看所有指令。
常用指令:
pip install package-name,用pip来安装第三方的包
- pip install -r requirements.txt 的作用是从一个文本文件 requirements.txt 中安装所需的 Python 包。一般情况下,项目提供者会在 requirements.txt 文件中列出所有项目所依赖的 Python 包及其版本号,使用这个命令可以方便地安装这些依赖并满足项目运行的需要。
pip install matplotlib==3.4.1,安装指定版本的第三方的包
pip uninstall package_name,卸载某个包
pip install --upgrade package_name# 或者是pip install -U package_name,更新某个包
pip show -f requests,查看指定包的信息
pip list -o 查看需要被升级的包
pip list 查看当前项目安装的包
查看python位置,注意:在环境变量中**WindowsApps这个路径要在**Python380这个路径下面。
C:\Users\Amy>where python
C:\Users\Amy\AppData\Local\Microsoft\WindowsApps\python.exe
C:\Program Files\Python380\python.exe
2. 基础语法
变量
概念:变量是用来保存和表示数据的占位符号
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建
创建一个变量,包括
- 变量的名称
- 变量保存的数据
- 变量存储数据的类型
- 变量的地址(标示)
使用(type)函数可以查看一个变量的类型
(1)数字型
整数(int)
%:取余
//:求整除
pow(x,y) :计算x^y
pow(x,y[,z]) : 幂余,x和y是必选参数,z是可选参数;如果使用了参数z,中括号必须去掉,即power(x,y,z),其结果是x的y次方再对z求余数,但是这种方式比power(x,y) % z的执行效率要高
abs(x) : 求绝对值
divmod(x,y), 商余,(x//y,x%y)结果为(商,余)
浮点数(float)
注意:浮点数计算存在不确定性位数,但这不是bug;round(x,d) :对x四舍五入,d是小数截取位数
科学计数法表示: <a>e<b> 表示a*(10^b)
布尔(bool)
“布尔”数据类型只有两种值:True 和False。
◾真 True ,非 0 数
◾假 False ,0
比较操作符
== 等于,!= 不等于,< 小于,> 大于,<= 小于等于,>= 大于等于,比较两个值,求值为一个布尔值。
>>> 42 == 42
True
布尔操作符
①二元布尔操作符
and 和or 操作符总是接受两个布尔值(或表达式),所以它们被认为是“二元”操作符。如果两个布尔值都为True,and 操作符就将表达式求值为True,否则求值为False。另一方面,只要有一个布尔值为真,or 操作符就将表达式求值为True。如果都是False,所求值为False。
>>> True and True
True
>>> True and False
False
>>> print(0 or 1 and True)
True
②not 操作符
not 操作符只作用于一个布尔值(或表达式),not 操作符求值为相反的布尔值。
>>> not True
False
在python中 None, False, 空字符串"“, 0, 空列表[], 空字典{}, 空元组()都相当于False。使用if not x这种写法的前提是:必须清楚x等于None, False, 空字符串”", 0, 空列表[], 空字典{}, 空元组()时对你的判断没有影响才行。
③混合布尔和比较操作符
>>> (4 < 5) and (5 < 6)
True
>>> (4 < 5) and (9 < 6)
False
复数型 (complex)
a+bj ; a-bj
注意:不同数字类型混合运算,结果为“最宽”类型
(2)非数字型
字符串、列表、元组、字典、set集合,详见以下链接:
Python变量——字符串、列表、元组、字典、set_python 字符串 *-优快云博客
(3)变量进阶
变量的引用
概念:
•变量 和 数据 是分开存储的
•数据 保存在内存中的一个位置
•变量 中保存着数据在内存中的地址
•变量 中 记录数据的地址,就叫做 引用
•使用 id() 函数可以查看变量中保存数据所在的 内存地址(每次运行脚本时,id会变化)
注意:如果变量已经被定义,当给一个变量赋值的时候,本质上是 修改了数据的引用
•变量 不再 对之前的数据引用
•变量 改为 对新赋值的数据引用
在 Python 中,函数的 实参/返回值 都是是靠 引用 来传递来的
可变和不可变类型
不可见类型,内存中的数据不允许被修改。value(值)一旦改变,id(内存地址)也改变,则称为不可变类型(id变,意味着创建了新的内存空间)。
◦数字类型 int, bool, float, complex, long(2.x)
#id
a = 1
print(id(a),type(a)) #1452422928 <class 'int'>
a = 2
print(id(a),type(a)) #1452422944 <class 'int'>
#float
b = 1.23
print(id(b),type(b)) #13260288 <class 'float'>
b = 2.59
print(id(b),type(b)) #13260048 <class 'float'>
#复数型
c = 1+2j
print(id(c),type(c)) #17454936 <class 'complex'>
c = 1-2j
print(id(c),type(c)) #17455608 <class 'complex'>
#bool
d = True
print(id(d),type(d)) #1452241744 <class 'bool'>
d = False
print(id(d),type(d)) #1452241760 <class 'bool'>◦字符串 str,改变string值后,id也变了
str = "test string"
print(id(str)) #17515288
str = "change"
print(id(str)) #16472544◦元组 tuple,改变值后,id也变了
info_tuple = ("zhangsan", 18, 1.75)
print(id(info_tuple)) # 15016344
info_tuple = info_tuple + (1,2,3)
print(info_tuple)#('zhangsan', 18, 1.75, 1, 2, 3)
print(id(info_tuple)) #14083496◦日期
#日期
import datetime
oneday = datetime.date.today()
print(oneday) #2022-03-23
print(id(oneday),type(oneday))# 10508792 <class 'datetime.date'>
oneday = datetime.date.today() - oneday
print(oneday) #0:00:00
print(id(oneday),type(oneday)) #10509176 <class 'datetime.timedelta'>可变类型:在id(内存地址)不变的情况下,value(值)可以变,则称为可变类型
- 列表 list,改变列表值后,id不变
l = [1,2,3,4,5]
print(id(l)) # 13642288
print(l[4]) #5
l[4] = 9
print(id(l)) # 13642288- 字典 dict,改变value后,id不变(注意:字典的 key 只能使用不可变类型的数据)
info = {"name":"Mary","age":"26"}
print(id(info)) #18251528
info["name"] = "Cindy"
print(id(info)) #18251528- set
set1={1,2,1,3,4,5,6,7}
print(id(set1),type(set1))#21787872 <class 'set'>
set1={1,2,3,8,9,7,10}
print(id(set1),type(set1))#21787872 <class 'set'>可变类型的数据变化,是通过 方法 来实现的。如果给一个可变类型的变量,赋值了一个新的数据,引用会修改
•变量 不再 对之前的数据引用
•变量 改为 对新赋值的数据引用
身份运算符
身份运算符用于 比较 两个对象的 内存地址 是否一致 —— 是否是对同一个对象的引用
is:is 是判断两个标识符是不是引用同一个对象,x is y,类似 id(x) == id(y)
is not: is not 是判断两个标识符是不是引用不同对象 ,x is not y,类似 id(a) != id(b)
is 与 == 区别:
is 用于判断 两个变量 引用对象是否为同一个
== 用于判断 引用变量的值 是否相等
哈希 (hash)
Python 中内置有一个名字叫做 hash() 的函数,获取一个对象的哈希值。
◦接收一个 不可变类型 的数据作为 参数(list,dictionary,set都是unhashable type)
◦返回 结果是一个 整数
哈希 是一种 算法,其作用就是提取数据的 特征码(指纹)
◦相同的内容 得到 相同的结果
◦不同的内容 得到 不同的结果
在 Python 中,设置字典的 键值对 时,会首先对 key(字典中的key也是不可变数据类型) 进行 hash 以决定如何在内存中保存字典的数据,以方便后续对字典的操作:增、删、改、查。
str = "apple"
print(hash(str)) #-1877658494
print(hash(1.23)) #579820504局部变量和全局变量
局部变量:
•局部变量 是在 函数内部 定义的变量,只能在函数内部使用
•函数执行结束后,函数内部的局部变量,会被系统回收
•不同的函数,可以定义相同的名字的局部变量,但是 彼此之间 不会产生影响
作用:在函数内部使用,临时 保存 函数内部需要使用的数据
局部变量的生命周期
•所谓 生命周期 就是变量从 被创建 到 被系统回收 的过程
•局部变量 在 函数执行时 才会被创建
•函数执行结束后 局部变量 被系统回收
•局部变量在生命周期 内,可以用来存储 函数内部临时使用到的数据
全局变量:
全局变量 是在 函数外部定义 的变量,所有函数内部都可以使用这个变量
注意:函数执行时,需要处理变量时 会:
1.首先 查找 函数内部 是否存在 指定名称 的局部变量,如果有,直接使用
2.如果没有,查找 函数外部 是否存在 指定名称 的全局变量,如果有,直接使用
3.如果还没有,程序报错!
注意:
1.函数不能直接修改 全局变量的引用;
•如果在函数中需要修改全局变量,需要使用 global 进行声明
global num
# 只是定义了一个局部变量,不会修改到全局变量,只是变量名相同而已
num = 100
•为了保证所有的函数都能够正确使用到全局变量,应该 将全局变量定义在其他函数的上方
(4)多变量的灵活处理
交换两个元素
a, b = b, a
解压变量
假设我们有一个二元数组:[1, 2],我们希望用两个变量分别获取它的第0位和第一位,
我们当然可以写成这样:
l = [1, 2]
a, b = l[0], l[1]其实并不用这么麻烦,因为当Python检测到等号左边是多个变量,右边是list或者是tuple之后,会自动执行list和tuple的解压,将它依次赋值给对应的元素,所以上面的代码可以简化成:
l = [1, 2]
a, b = l
#结果a=1, b=2那如果l是一个二维数组,我们希望遍历它呢?同样可以在循环当中使用:
l = [[1, 2], [3, 4], [5, 6]]
for i, j in l:
print(i, j)
即使是在变量的组合当中也可以生效:
a, b, c = 1, 3, (4, 5)
print(c) # (4, 5)Python发现变量数量对不上之后,会自动将tuple当做一个整体进行赋值。不但如此,即使是下面这种情况,Python也能自动识别:
a, b, (c, d), e = 1, 3, (4, 5), 7
print(c, d) # 4 5实战,查询数据库,得到结果存在result和description中:

左边两个变量,一般数据库返回是个元组,result就是实际的查询值,用的比较多,description就是每个列名的描述偶尔会用到你用result一个等于也是可以的。
压缩变量
既然变量可以解压,那么自然也可以压缩。想象一个场景,比如有一批衡量工厂零件的数据,这个数据当中除了零件的尺寸之外还包含了零件的名称,生产日期和工厂名称等等其他的属性。假设我们当下希望解析这份数据,并且将零件的尺寸用数组存储,这个时候应该怎么办呢?
比如,零件的数据的规格长这样:wheel, factory1, 3, 4, 5, 6, 2020-02-02
Python同样针对这个问题提供了解决方法,就是变量压缩符*,针对上面那个问题,我们可以写成:
data = ['wheel', 'factory1', 3, 4, 5, 6, '2020-02-02']
name, factory, *inch, date = data
print(inch)
最后我们打印出来的inch是[3, 4, 5, 6],也就是说通过使用*,我们成功地将中间表示零件尺寸的数据赋值进了一个数组当中。这个操作非常重要,因为有可能不同零件尺寸的数量是不同的,如果我们自己写解析的话就很难处理这个问题。而使用Python当中的 *操作符,我们可以很好地解决这个问题。
联合使用
到这里,我们介绍了缺省符号的用法,介绍了压缩符号的用法,问题来了,我们能不能将这两个符号组合使用,获取数据当中任意个缺省值呢?
当然是可以的,还是刚才的问题,假设我们现在不关心零件的尺寸,想要过滤掉它们,我们只要对上面的代码稍作改动即可:
data = ['wheel', 'factory1', 3, 4, 5, 6, '2020-02-02']
name, factory, *_, date = data
print(name)
print(factory)
print(_)
print(data)
结果
wheel
factory1
[3, 4, 5, 6]
['wheel', 'factory1', 3, 4, 5, 6, '2020-02-02']
如此我们就过滤掉了中间若干个尺寸信息,仅仅保留了头尾其他的信息。
参考:Python应用——多变量的灵活处理 - Coder梁 - 博客园
命名
命名规则:
- 大小写字母、数字、下划线
- 首字母不能是数字
- 大小写敏感
- 不与保留字相同
- 不能包含空格
在定义变量时,为了保证代码格式,= 的左右应该各保留一个空格
在 Python 中,如果变量名需要由两个或多个单词组成时,
- 每个单词都使用小写字母,单词与单词之间使用 _下划线 连接(例如:first_name、last_name、qq_number、qq_password)
- 小驼峰式命名法:第一个单词以小写字母开始,后续单词的首字母大写(例如:firstName、lastName);
- 大驼峰式命名法:每一个单词的首字母都采用大写字母(例如:FirstName、LastName、CamelCase )
私有性
- 单下划线前缀 (_variable):
私有性: 单个下划线前缀的变量或函数通常用于表示“私有”的,意味着这些变量或函数不应该被外部直接访问。在Python中,这种私有性是基于约定的(非强制性的),外部仍可以访问这些变量和函数。
内部使用: 这种约定通常用于模块或类内部,表示变量或方法主要用于内部逻辑,而不是作为API的一部分暴露给外部。
在使用"from XXX import *"语句从模块中导入时,这些模块变量或函数不能被导入。只允许当前类创建的对象和子类对象访问此变量。外部无法访问此变量。
- 单下划线后缀 (variable_):
避免命名冲突: Python中的关键字不能作为变量名。如果你需要使用一个可能与Python关键字冲突的名称,可以在名称后加一个下划线来避免这种冲突。例如,使用class_而不是class。
- 双下划线前缀 (__variable):
名称改编(Name Mangling): 在类的上下文中,使用双下划线前缀可以触发Python的名称改编特性,该特性意在限制变量或函数的访问范围。这通常用于类的私有成员。Python解释器改写变量名,加入类名作为前缀,从而使得从类外部直接访问这些变量或方法变得困难。
避免子类覆盖: 双下划线的使用有助于避免在子类中意外覆盖基类的方法。
只允许当前类对象访问,不允许子类对象和外部对象访问
- 双下划线前后缀 (__variable__):
特殊方法或属性: 这种形式的变量通常指代Python的特殊方法或属性(也称作“魔法”方法或属性),例如__init__、__str__、__len__等。这些是Python预定义的方法,用于实现特定的语言构造或功能。通常不建议开发者定义新的这种形式的变量。
__doc__ 表示类的描述信息
__module__ 表示当前操作的对象在那个模块
__class__ 表示当前操作的对象的类是什么
__init__ 初始化⽅法,通过类创建对象时,⾃动触发执⾏
__del__ 当对象在内存中被释放时,⾃动触发执⾏。此⽅法⼀般⽆须定义,因为Python是⼀⻔⾼级语⾔,程序员在使⽤时⽆需关⼼内存的分配和释放,因为此⼯作都是交给Python解释器来执⾏,所 以,__del__的调⽤是由解释器在进⾏垃圾回收时⾃动触发执⾏的。
__call__ 对象后⾯加括号,触发执⾏。注:__init__⽅法的执⾏是由创建对象触发的,即: 对象 = 类名() ;⽽对于 __call__ ⽅法的执⾏是由对象后加括号触发的,即: 对象() 或者 类()
class Foo:
def __init__(self):
pass
def __call__(self, *args, **kwargs):
print('__call__')
obj = Foo() # 执⾏ __init__
obj() # 执⾏ __call____dict__ 类或对象中的所有属性,类的实例属性属于对象;类中的类属性和⽅法等属于类.
class Province(object):
country = 'China'
def __init__(self, name, count):
self.name = name
self.count = count
def func(self, *args, **kwargs):
print('func')
# 获取类的属性,即:类属性、⽅法、
print(Province.__dict__)
# 输出:{'__dict__': <attribute '__dict__' of 'Province' objects>, '__module__': '__main__', 'country': 'China', '__doc__': None, '__weakref__': <attribute '__weakref__' of 'Province' objects>, 'func': <function Province.func at 0x101897950>, '__init__': <function Province.__init__ at 0x1018978c8>}
obj1 = Province('⼭东', 10000)
print(obj1.__dict__)
# 获取 对象obj1 的属性
# 输出:{'count': 10000, 'name': '⼭东'}
obj2 = Province('⼭⻄', 20000)
print(obj2.__dict__)
# 获取 对象obj1 的属性
# 输出:{'count': 20000, 'name': '⼭⻄'}__str__ 如果⼀个类中定义了__str__⽅法,那么在打印 对象 时,默认输出该⽅法的返回值。
class Foo:
def __str__(self):
return 'laowang'
obj = Foo()
print(obj)
# 输出:laowang__getitem__、__setitem__、__delitem__ ⽤于索引操作,如字典。以上分别表示获取、设置、删除数据。
xx: 公有变量_x: 单前置下划线,私有化属性或⽅法,from somemodule import *禁⽌导⼊,类对象和⼦类可以访问__xx:双前置下划线,避免与⼦类中的属性命名冲突,⽆法在外部直接访问(名字重整所以访问不到)__xx__:双前后下划线,⽤户名字空间的魔法对象或属性。例如: __init__ , __ 不要⾃⼰发明这样的名字xx_:单后置下划线,⽤于避免与Python关键词的冲突
⽗类中属性名为 __名字 的,⼦类不继承,⼦类不能访问如果在⼦类中向 __名字 赋值,那么会在⼦类中定义的⼀个与⽗类相同名字的属性_名 的变量、函数、类在使⽤ from xxx import * 时都不会被导⼊
保留字/关键字(33个)
被编程语言内部定义并保留使用的标识符:and,as,assert,break,class,continue,def,del,elif,else,expect,finally,for,from,False,global,if,is,import,in,lambda,not,nonlocal,None,or,pass,return,raise,try,True,while,with,yeild
标识符/关键字后面不需要使用括号
语法:每个保留字所在行最后存在一个冒号(:),比如def,class后面
运算符
算术运算符:+ - * / %(取余) //(整除) ** (求次方)
逻辑运算符:与(and),或(or),非(not)
成员运算符:
- in:判断一个元素是否在序列中;
- not in : 如果在指定的序列中没有找到值返回True,否则返回False

转义符
\b : 回退
\n : 换行
\r : 回车
\t:横向制表符,在控制台输出一个 制表符,协助在输出文本时 垂直方向 保持对齐
\\:反斜杠符号
\' :单引号
\": 双引号
缩进
Python以缩进表达程序的格式框架,所以要严格控制缩进,一般是4个空格,或者一个 tab 键。
注意:在 Python 开发中,Tab 和空格不要混用!
注释
单行注释: # 追加说明文字 注意:尽量在文字前面打个空格 在# 号前面需要追加两个空格。例如 print() # 注释
多行注释语法:
"""
注释内容
"""
3.面向对象编程
面向对象编程 —— Object Oriented Programming 简写 OOP。
面向对象与面向过程:
| 面向过程 | 面向对象 | |
| 怎么做 | 1.把完成某一个需求的所有步骤从头到尾逐步实现 2.根据开发需求,将某些功能独立 的代码封装成一个又一个 函数 3.最后完成的代码,就是顺序地调用不同的函数 | 相比较函数,面向对象是更大的封装,根据职责在一个对象中 封装多个方法 1.在完成某一个需求前,首先确定职责 —— 要做的事情(方法) 2.根据职责确定不同的对象,在对象内部封装不同的方法(多个) 3.最后完成的代码,就是顺序地让不同的对象调用不同的方法 |
| 特点 | 1.注重步骤与过程,不注重职责分工 2.如果需求复杂,代码会变得很复杂 3.开发复杂项目,没有固定的套路,开发难度很大 | 1.注重对象和职责,不同的对象承担不同的职责 2.更加适合应对复杂的需求变化,是专门应对复杂项目开发,提供的固定套路 3.需要在面向过程基础上,再学习一些面向对象的语法 |
| 面向对象是更大的封装,在一个类中封装多个方法,这样通过这个类创建出来的对象,就可以直接调用这些方法了 |
3.1类
(1)概念
类是对一群具有相同特征或者行为的事物的一个统称,是抽象的,不能直接使用。
◦特征 被称为属性
◦行为 被称为方法
(2)类的设计
类名:命名方法:首字母大写
名词提炼法 :分析整个业务流程,出现的名词,通常就是找到的类
属性:对对象的特征描述,通常可以定义成属性
方法:对象具有的行为(动词),通常可以定义成方法。类中的函数称为方法,函数的一切都适用于方法,二者之间有一个重要的差别就是调用方式不同。
定义只包含方法的类:
class 类名:
def 方法1(self, 参数列表):
pass
def 方法2(self):
pass3.2对象
对象是由类创建出来的一个具体存在,可以直接使用。
由哪一个类创建出来的对象,就拥有在哪一个类中定义的属性和方法
创建对象:对象变量 = 类名(),例如:my_dog = Dog()
类和对象的关系
类是模板,对象是根据类这个模板创建出来的,应该先有类,再有对象
•类 只有一个,而对象可以有很多个,不同的对象之间属性可能会各不相同
•类 中定义了什么属性和方法,对象中就有什么属性和方法,不可能多,也不可能少
class 类(object):
属性1
属性2
def ⽅法1(self):
pass
def ⽅法2(self):
pass
class 类2(object):
属性3
def ⽅法3(self):
pass为什么要继承object类
Python2中,遇到 class A 和 class A(object) 是有概念上和功能上的区别的,分别称为经典类(旧式类,old-style)与新式类(new-style)的区别。python2中为什么在进行类定义时最好要加object,加 & 不加如下实例。
历史进程:2.2以前的时候type和object还不统一. 在2.2统一到3之间, 要用class
- Foo(object)来申明新式类, 因为它的type是 < type ‘type’ > 。
- 不然的话, 生成的类的type就是 <type ‘classobj’ >。
继承object类的原因:主要目的是便于统一操作。
- 在python 3.X中已经默认继承object类。
python2中继承object类是为了和python3保持一致,python3中自动继承了object类。
python2: class(object)
python3: class() object写不写都行。
3.3方法
初始化方法__init__ ()
当使用类名() 创建对象时,会自动执行以下操作:
- 为对象在内存中分配空间 — 创建对象
- 为对象的属性设置初始值 — 初始化方法
这个初始化方法就是 __init__ 方法,__init__ 是对象的内置方法(类是一个特殊的对象 —— 类对象,如果不在类中定义def __init__(self),会使用默认的内置方法,如果在类中定义def __init__(self),相当于重构)。__init__ 方法是专门用来定义一个类具有哪些属性的方法。每当根据类创建新实例时,Python都会自动运行这个方法(其他自定义方法需要调用才能使用,要调用方法,可指定实例的名称和要调用的方法:对象.方法名())。
初始化方法__init__ ()开头和末尾有两个下划线,这是一种约定,旨在避免Python默认方法与普通方法发生名称冲突。
在开发中,如果希望在创建对象的同时,就设置对象的属性,可以对 __init__ 方法进行 改造
- 把希望设置的属性值,定义成 __init__ 方法的参数
- 在方法内部使用 self.属性 = 形参 接收外部传递的参数,属性可以任意命名
- 在创建对象时,使用 类名(属性1, 属性2...) 调用
__init__ ()是一个实例方法,用来在实例创建完成后进行必要的初始化,该方法必须返回None.
Python不会自动调用父类的__init__ ()方法,这需要额外的调用:super(C,self).__init__ ()来完成。
__contains__(), python预定义的特殊方法(内置方法)__contains__(self, item)
布尔测试y in x会调用 x.__contains__(y);
对于序列x而言,如果y等于x中的某一个值,那么__contains__()方法应该返回True;对于映射x而言,如果y等于x的键中的某一个,那么__contains__()方法应该返回True.
举例1:
class Cat:
def __init__(self, name):
print("初始化方法 %s" % name)
self.name = name
tom = Cat("Tom")
lazy_cat = Cat("大懒猫")举例2:给属性设置默认值
类中的每个属性都必须有初始值,哪怕这个值是0或空字符串。在方法__init__()中制定这种初始值是可行的;如果你对某个属性这样做了,就无需包含为它提供初始值的形参。
def __init__(self):
"""初始化游戏的静态设置"""
#屏幕设置
self.screen_width = 1200
self.screen_height = 800
self.bg_color = (230,230,230)
#飞船设置
self.ship_limit = 3
#子弹设置
self.bullet_width = 3
self.bullet_height = 15
self.bullet_color = 60,60,60
#将未消失的子弹设置为最大为3颗
self.bullets_allowed = 3
#外星人设置
self.fleet_drop_speed = 10
#以什么样的速度加快游戏节奏
self.speed_up_scale = 1.1
#外星人点数的提高速度
self.score_scale = 1.5方法中的形参self
python调用__init__()来创建实例时,将自动传入实参self。每个与类相关联的方法调用都自动传实参self,它是一个指向实例(instance)本身的引用,让实例能够访问类中的属性和方法。例如,我们将通过实参向Cat()传递名字和年龄,self会自动传递,因此我们不需要传递它。当我们根据Cat类创建实例时,都只需要给后面的形参(比如:name,age)提供值。
以self为前缀的变量都可以供类中所有的方法使用,我们也可以通过类的任何实例来访问这些变量。
self.name(实参) = name(形参)获取存储在形参name中的值,并将其存储到变量name中,然后该变量被关联到当前创建的实例。像这样可以通过实例访问的变量称为属性。( self.属性 = 形参)
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i)
#结果:3.0 -4.5 •在类的外部,通过变量名(即对象名). 访问对象的属性和方法
•在类封装的方法中通过self.访问对象的属性和方法
总结:
由哪一个对象调用的方法,方法内的self就是哪一个对象的引用.
- 在类封装的方法内部,self 就表示当前调用方法的对象自己
- 调用方法时,不需要传递 self 参数
- 在方法内部 ◦可以通过 self. 访问对象的属性 ◦也可以通过 self. 调用其他的对象方法
self. 调用其他的对象方法举例:

私有属性和私有方法
应用场景:
•在实际开发中,对象的某些属性或方法可能只希望在对象的内部被使用,而不希望在外部被访问到
•私有属性就是对象不希望公开的属性
•私有方法就是对象不希望公开的方法
定义方式:在定义属性或方法时,在属性名或者方法名前增加两下划线,定义的就是私有属性或方法,如:self.__age = 18
类属性和类方法
①术语:实例
1.创建出来的对象叫做类的实例
2.创建对象的动作叫做实例化
3.对象的属性叫做实例属性
4.对象调用的方法叫做实例方法
②类是一个特殊的对象
Python中一切皆对象
•在程序运行时,类同样会被加载到内存
•在Python中,类是一个特殊的对象 — 类对象
•在程序运行时,类对象在内存中只有一份,使用一个类可以创建出很多个对象实例
•除了封装实例的属性和方法外,类对象还可以拥有自己的属性和方法(类属性和类方法) • 通过 “ 类名. ” 的方式可以 访问类的属性 或者 调用类的方法
③类属性和实例属性
它们在定义和使⽤中有所区别,⽽最本质的区别是内存中保存的位置不同,实例属性属于对象,类属性属于类。
- 类属性在内存中只保存⼀份,实例属性在每个对象中都要保存⼀份。
- 类属性就是给类对象定义的属性,通常用来记录与这个类相关的特征
- 实例属性需要通过对象来访问,类属性通过类访问。
class Province(object):
# 类属性
country = '中国'
def __init__(self, name):
# 实例属性
self.name = name
# 创建⼀个实例对象
obj = Province('⼭东省')
# 直接访问实例属性
print(obj.name)
# 直接访问类属性
Province.country④类方法和静态方法
实例⽅法、静态⽅法和类⽅法,三种⽅法在内存中都归属于类,区别在于调⽤⽅式不同。
- 实例⽅法(普通方法):由对象调⽤;⾄少⼀个self参数;执⾏实例⽅法时,⾃动将调⽤该⽅法的对象赋值给self;
- 类⽅法:由类调⽤; ⾄少⼀个cls参数;执⾏类⽅法时,⾃动将调⽤该⽅法的类赋值给cls;需要使用修饰器classmethod;
- 静态⽅法:由类调⽤;⽆默认参数;需要使用修饰器staticmethod
class Foo():
def __init__(self, name):
self.name = name
def ord_func(self):
""" 定义实例⽅法,⾄少有⼀个self参数 """
print('实例⽅法')
@classmethod
def class_func(cls):
""" 定义类⽅法,⾄少有⼀个cls参数 """
print('类⽅法')
@staticmethod
def static_func():
""" 定义静态⽅法 ,⽆默认参数"""
print('静态⽅法')
f = Foo("中国")
print(f.name)
# 调⽤实例⽅法
f.ord_func()
# 调⽤类⽅法
Foo.class_func()
# 调⽤静态⽅法
Foo.static_func()输出结果:
中国
实例⽅法
类⽅法
静态⽅法
一般来说,要使用某个类的方法,需要先实例化一个对象再调用方法。而使用@staticmethod或@classmethod,就可以不需要实例化,直接类名.方法名()来调用。
这有利于组织代码,把某些应该属于某个类的函数给放到那个类里去,同时有利于命名空间的整洁。
类方法
类方法就是针对类对象定义的方法,在类方法内部可以直接访问类属性或者调用其他的类方法。
类方法和普通方法的区别是,类方法只能访问类变量,不能访问实例变量。
语法:
@classmethod
def 类方法名(cls):
pass•类方法需要用 修饰器 @classmethod 来标识,告诉解释器这是一个类方法
•类方法的第一个参数应该是 cls
◦由哪一个类调用的方法,方法内的cls就是哪一个类的引用
◦这个参数和实例方法的第一个参数self 类似
◦其实使用其他名称也可以,不过习惯使用 cls
•通过类名. 调用类方法,调用方法时,不需要传递 cls 参数
在方法内部
◦可以通过 cls. 访问类的属性
◦也可以通过 cls. 调用其他的类方法
cls通常用作类方法的第一参数 跟self有点类似( __init__里面的slef通常用作实例方法的第一参数)。即通常用self来传递当前类的实例–对象,cls传递当前类。
self 和cls 没有特别的含义,作用只是把参数绑定到普通的函数上, 不一定非得是self 或cls,可以换成别的xxx。
那么为什么会出现classmethod?
classmethod设计的目的是什么呢?事实上与Python面向对象编程有关的,由于Python不支持多个的參数重载构造函数,比方在C++里,构造函数能够依据參数个数不一样。能够写多个构造函数。Python为了解决问题,採用classmethod修饰符的方式,这样定义出来的函数就能够在类对象实例化之前调用这些函数,就相当于多个构造函数,解决多个构造函数的代码写在类外面的问题;
类最基本的作用是实例化出一个对象,但是有的时候再实例化之前,就需要先和类做一定的交互,这种交互可能会影响实际实例化的过程,所以必须放在调用构造函数之前。大概也可能是因为这个原因出现了classmethod;
直接一点来说,我们知道对于一个普通的类,我们要使用其中的函数的话,需要对类进行实例化,而一个类中,某个函数前面加上了staticmethod或者classmethod的话,那么这个函数就可以不通过实例化直接调用,可以通过类名进行调用的;
@classmethod 定义的类方法是可选构造函数中,我们定义了一个类方法,类方法的第一个参数(cls)指代的就是类本身。类方法会用这个类来创建并返回最终的实例。使用类方法的另一个好处就
静态方法
•在开发时,如果需要在类中封装一个方法,这个方法:
◦既不需要访问实例属性或者调用实例方法
◦也不需要访问类属性或者调用类方法
•这个时候,可以把这个方法封装成一个静态方法
语法如下
@staticmethod
def 静态方法名():
pass•静态方法需要用修饰器 @staticmethod 来标识,告诉解释器这是一个静态方法
•通过类名. 调用静态方法
举例:
class Dog(object):
# 狗对象计数
dog_count = 0
@staticmethod
def run():
# 不需要访问实例属性也不需要访问类属性的方法
print("狗在跑...")
def __init__(self, name):
self.name = namestaticmethod用于修饰类中的方法,使其可以在不创建类实例的情况下调用方法,这样做的好处是执行效率比较高。当然,也可以像一般的方法一样用实例调用该方法。
该方法一般被称为静态方法。静态方法不可以引用类中的属性或方法,其参数列表也不需要约定的默认参数self。
property属性
(1)property属性是⼀种⽤起来像是使⽤的实例属性⼀样的特殊属性,可以对应于某个⽅法。
- 定义时,在实例⽅法的基础上添加 @property 装饰器;并且仅有⼀个self参数
- 调⽤时,⽆需括号
# ############### 定义 ###############
class Foo:
def func(self):
pass
# 定义property属性
@property
def prop(self):
pass
# ############### 调⽤ ###############
foo_obj = Foo()
foo_obj.func() # 调⽤实例⽅法
foo_obj.prop # 调⽤property属性简单的实例,Python的property属性的功能是:property属性内部进⾏⼀系列的逻辑计算,最终将计算结果返回。
# ############### 定义 ###############
class Pager:
def __init__(self, current_page):
# ⽤户当前请求的⻚码(第⼀⻚、第⼆⻚...)
self.current_page = current_page
# 每⻚默认显示10条数据
self.per_items = 10
@property
def start(self):
val = (self.current_page - 1) * self.per_items
return val
@property
def end(self):
val = self.current_page * self.per_items
return val
# ############### 调⽤ ###############
p = Pager(1)
print(p.start) # 就是起始值,即:m
print(p.end) # 就是结束值,即:n运算结果
0
10
(2)property属性的有两种⽅式
装饰器⽅式
在类的实例⽅法上应⽤@property装饰器,Python中的类有 经典类 和 新式类 , 新式类 的属性比经典类的属性丰富( 如果类继object,那么该类是新式类 )。经典类中的属性只有⼀种访问⽅式,其对应被 @property 修饰的⽅法,新式类中的属性有三种访问⽅式,并分别对应了三个被@property、@⽅法名.setter、@⽅法名.deleter修饰的⽅法。由于新式类中具有三种访问⽅式,我们可以根据它们⼏个属性的访问特点,分别将三个⽅法定义为对同⼀个属性:获取、修改、删除。
经典类:
# ############### 定义 ###############
class Goods:
@property
def price(self):
return "laowang"
# ############### 调⽤ ###############
obj = Goods()
result = obj.price # ⾃动执⾏ @property 修饰的 price ⽅法,并获取⽅法的返回值
print(result)新式类:
# ############### 定义 ###############
class Goods:
"""
python3中默认继承object类
只有在python3中才有@xxx.setter @xxx.deleter
"""
@property
def price(self):
print('@property')
@price.setter
def price(self, value):
print('@price.setter')
@price.deleter
def price(self):
print('@price.deleter')
# ############### 调⽤ ###############
obj = Goods()
obj.price # ⾃动执⾏ @property 修饰的 price ⽅法,并获取⽅法的返回值
obj.price = 123 # ⾃动执⾏ @price.setter 修饰的 price ⽅法,并将 123 赋值给⽅法的参数
del obj.price # ⾃动执⾏ @price.deleter 修饰的 price ⽅法运行结果:
@property
@price.setter
@price.deleter
类属性⽅式
class Foo:
def get_bar(self):
return 'laowang'
BAR = property(get_bar)
obj = Foo()
reuslt = obj.BAR # ⾃动调⽤get_bar⽅法,并获取⽅法的返回值
print(reuslt) #laowang- 第⼀个参数是⽅法名,调⽤ 对象.属性 时⾃动触发执⾏⽅法
- 第⼆个参数是⽅法名,调⽤ 对象.属性 = XXX 时⾃动触发执⾏⽅法
- 第三个参数是⽅法名,调⽤ del 对象.属性 时⾃动触发执⾏⽅法
- 第四个参数是字符串,调⽤ 对象.属性.__doc__ ,此参数是该属性的描述信息
由于 类属性⽅式 创建property属性具有3种访问⽅式,我们可以根据它们⼏个属性的访问特点,分别将三个⽅法定义为对同⼀个属性:获取、修改、删除。
class Foo(object):
def get_bar(self):
print("getter...")
return 'laowang'
def set_bar(self, value):
"""必须两个参数"""
print("setter...")
return 'set value' + value
def del_bar(self):
print("deleter...")
return 'laowang'
BAR = property(get_bar, set_bar, del_bar, "description...")
obj = Foo()
obj.BAR # ⾃动调⽤第⼀个参数中定义的⽅法:get_bar
obj.BAR = "alex" # ⾃动调⽤第⼆个参数中定义的⽅法:set_bar⽅法,并将“alex”当作参数传⼊
desc = Foo.BAR.__doc__ # ⾃动获取第四个参数中设置的值:description...
print(desc)
del obj.BAR # ⾃动调⽤第三个参数中定义的⽅法:del_bar⽅法运行结果:
getter...
setter...
description...
deleter...
property属性-应⽤
①使⽤property升级getter和setter⽅法。
class Money(object):
def __init__(self):
self.__money = 0
def getMoney(self):
return self.__money
def setMoney(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
# 定义⼀个属性,当对这个money设置值时调⽤setMoney,当获取值时调⽤getMoney
money = property(getMoney, setMoney)
a = Money()
a.money = 100 # 调⽤setMoney⽅法
print(a.money) # 调⽤getMoney⽅法 # 100②使⽤property取代getter和setter⽅法,重新实现⼀个属性的设置和读取⽅法,可做边界判定。
class Money(object):
def __init__(self):
self.__money = 0
# 使⽤装饰器对money进⾏装饰,那么会⾃动添加⼀个叫money的属性,当调⽤获取money的值时,调⽤装饰的⽅法
@property
def money(self):
return self.__money
# 使⽤装饰器对money进⾏装饰,当对money设置值时,调⽤装饰的⽅法
@money.setter
def money(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
a = Money()
a.money = 100
print(a.money) #1003.4继承
面向对象三大特性:继承、封装、多态。
(1)概念
继承,实现代码的重用,相同的代码不需要重复的编写
概念:子类拥有父类的所有方法和属性
语法:•子类继承自父类,可以直接享受父类中已经封装好的方法,不需要再次开发
•子类中应该根据职责,封装子类特有的属性和方法
继承的语法: class 类名(父类名):
术语:Dog 类是 Animal 类的子类,Animal 类是 Dog 类的父类,Dog 类从 Animal 类继承
Dog 类是 Animal 类的派生类,Animal 类是 Dog 类的基类,Dog 类从 Animal 类派生
继承的传递性:子类拥有父类以及父类的父类中封装的所有属性和方法。
(2)重写
当父类的方法实现不能满足子类需求时,可以对方法进行重写(override)两种情况:
①覆盖父类的方法
•如果在开发中,父类的方法实现和子类的方法实现完全不同
•就可以使用覆盖的方式,在子类中重新编写父类的方法实现
具体的实现方式,就相当于在子类中定义了一个和父类同名的方法并且实现
重写之后,在运行时,只会调用子类中重写的方法,而不再会调用父类封装的方法
②对父类方法进行扩展
1.在子类中重写父类的方法
2.在需要的位置使用super().父类方法来调用父类方法的执行
3.代码其他的位置针对子类的需求,给子类定义属性和方法,编写子类特有的代码实现
super:•在Python中super是一个特殊的类
•super() 就是使用super类创建出来的对象
•最常使用的场景就是在重写父类方法时,调用在父类中封装的方法实现
super()._init_() 调用父类的方法_init_()
class Bullet(Sprite):
"""一个对飞船发射的子弹进行管理的类"""
def __init__(self,ai_settings,screen,ship):
"""在飞船所处的位置创建一个子弹对象"""
super().__init__()
self.screen = screen
# 在(0,0)处创建一个表示子弹的矩形,再设置正确的位置
self.rect = pygame.Rect(0,0,ai_settings.bullet_width,ai_settings.bullet_height)
self.rect.centerx = ship.rect.centerx
self.rect.top = ship.rect.top
# 存储用小数表示的子弹位置
self.y = float(self.rect.y)
self.color = ai_settings.bullet_color
self.speed_factor = ai_settings.bullet_speed_factor
def update(self):
"""向上移动子弹"""
#更新表示子弹位置的小数值
self.y -= self.speed_factor
#更新表示子弹的rect位置
self.rect.y =self.y
def draw_bullet(self):
"""在屏幕上绘制子弹"""
pygame.draw.rect(self.screen,self.color,self.rect)(3)将实例用作属性
有时候,根据需要,我们可以把很多属性和方法提取出来,放到一个类中。
举例说明:把很多属性和方法另一个类Battery中,并将一个Battery实例用作ElectricCar类的一个属性。
class Car():
--snip--
class Battery():
def _init_(self,battery_size=70):
self.battery_size = battery_size
class ElectricCar(Car):
def _init_():
super()._init_(make,model,year)
#将实例用作属性
self.battery = Battery()
my_tesla = ElectricCar('tesla','model s','2018')(4)父类的私有属性和私有方法
1.子类对象不能在自己的方法内部,直接访问父类的私有属性或私有方法
2.子类对象可以通过父类的公有方法间接访问到私有属性或私有方法
•私有属性、方法是对象的隐私,不对外公开,外界以及子类都不能直接访问
•私有属性、方法通常用于做一些内部的事情
(5)多继承
概念:子类可以拥有多个父类,并且具有所有父类的属性和方法
例如:孩子会继承自己父亲和母亲的特性
语法:class 子类名(父类名1, 父类名2...)
pass
注意事项:开发时,应该尽量避免容易产生混淆的情况—— 如果 父类之间存在同名的属性或者方法,应该尽量避免使用多继承。
# coding=utf-8
print("******多继承使⽤类名.__init__ 发⽣的状态******")
class Parent(object):
def __init__(self, name):
print('parent的init开始被调⽤')
self.name = name
print('parent的init结束被调⽤')
class Son1(Parent):
def __init__(self, name, age):
print('Son1的init开始被调⽤')
self.age = age
Parent.__init__(self, name)
print('Son1的init结束被调⽤')
class Son2(Parent):
def __init__(self, name, gender):
print('Son2的init开始被调⽤')
self.gender = gender
Parent.__init__(self, name)
print('Son2的init结束被调⽤')
class Grandson(Son1, Son2):
def __init__(self, name, age, gender):
print('Grandson的init开始被调⽤')
Son1.__init__(self, name, age) # 单独调⽤⽗类的初始化⽅法
Son2.__init__(self, name, gender)
print('Grandson的init结束被调⽤')
gs = Grandson('grandson', 12, '男')
print('姓名:', gs.name)
print('年龄:', gs.age)
print('性别:', gs.gender)
print("******多继承使⽤类名.__init__ 发⽣的状态******\n\n")运行结果
多继承中super调⽤有所⽗类的被重写的⽅法
print("******多继承使⽤super().__init__ 发⽣的状态******")
class Parent(object):
def __init__(self, name, *args, **kwargs): # 为避免多继承报错,使⽤不定⻓参数,接受参数
print('parent的init开始被调⽤')
self.name = name
print('parent的init结束被调⽤')
class Son1(Parent):
def __init__(self, name, age, *args, **kwargs): # 为避免多继承报错,使⽤不定⻓参数,接受参数
print('Son1的init开始被调⽤')
self.age = age
super().__init__(name, *args, **kwargs) # 为避免多继承报错,使⽤不定⻓参数,接受参数
print('Son1的init结束被调⽤')
class Son2(Parent):
def __init__(self, name, gender, *args, **kwargs): # 为避免多继承报错,使⽤不定⻓参数,接受参数
print('Son2的init开始被调⽤')
self.gender = gender
super().__init__(name, *args, **kwargs) # 为避免多继承报错,使⽤不定⻓参数,接受参数
print('Son2的init结束被调⽤')
class Grandson(Son1, Son2):
def __init__(self, name, age, gender):
print('Grandson的init开始被调⽤')
# 多继承时,相对于使⽤类名.__init__⽅法,要把每个⽗类全部写⼀遍
# ⽽super只⽤⼀句话,执⾏了全部⽗类的⽅法,这也是为何多继承需要全部传参的⼀个原因
# super(Grandson, self).__init__(name, age, gender)
super().__init__(name, age, gender)
print('Grandson的init结束被调⽤')
print(Grandson.__mro__)
gs = Grandson('grandson', 12, '男')
print('姓名:', gs.name)
print('年龄:', gs.age)
print('性别:', gs.gender)
print("******多继承使⽤super().__init__ 发⽣的状态******\n\n")运行结果
注意:
1. 以上2个代码执⾏的结果不同
2. 如果2个⼦类中都继承了⽗类,当在⼦类中通过⽗类名调⽤时,parent被执⾏了2次
3. 如果2个⼦类中都继承了⽗类,当在⼦类中通过super调⽤时,parent被执⾏了1次
单继承中super
print("******单继承使⽤super().__init__ 发⽣的状态******")
class Parent(object):
def __init__(self, name):
print('parent的init开始被调⽤')
self.name = name
print('parent的init结束被调⽤')
class Son1(Parent):
def __init__(self, name, age):
print('Son1的init开始被调⽤')
self.age = age
super().__init__(name) # 单继承不能提供全部参数
print('Son1的init结束被调⽤')
class Grandson(Son1):
def __init__(self, name, age, gender):
print('Grandson的init开始被调⽤')
super().__init__(name, age) # 单继承不能提供全部参数
print('Grandson的init结束被调⽤')
gs = Grandson('grandson', 12, '男')
print('姓名:', gs.name)
print('年龄:', gs.age)
#print('性别:', gs.gender)
print("******单继承使⽤super().__init__ 发⽣的状态******\n\n")以下的代码的输出将是什么? 说出你的答案并解释。
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x)
Child1.x = 2
print(Parent.x, Child1.x, Child2.x)
Parent.x = 3
print(Parent.x, Child1.x, Child2.x输出结果
3.5封装
1.封装是面向对象编程的一大特点
2.面向对象编程的第一步—— 将属性和方法封装到一个抽象的类中
3.外界使用类创建对象,然后让对象调用方法
4.对象方法的细节都被封装在类的内部
模块化和参数化:
假设要实现关于126邮箱的自动化测试项目那么可能每条用例都要有登录和退出动作,大部分测试用例都是在登录后进行的,例如:发邮件、查看、删除、搜索邮件等操作。
此时,创建一个module.py文件来存放登录和退出操作(模块化)。测试数据会不同,将login()方法参数化。
class Mail:
def __init__(self,driver):
self.driver = driver
def login(self,username,password):
"""登录"""
login_frame = self.driver.find_element_by_css_selector('iframe[id^="x-URS-iframe"]')
self.driver.switch_to.frame(login_frame)
self.driver.find_element_by_name("email").clear()
self.driver.find_element_by_name("email").send_keys("username")
self.driver.find_element_by_name("password").clear()
self.driver.find_element_by_name("password").send_keys("password")
self.driver.find_element_by_id("dologin").click()
def logout(self):
"""退出"""
self.driver.find_element_by_link_text("退出").click()在test_mail.py中,调用Mail类的login()和logout()方法。
from time import sleep
from selenium import webdriver
from module import Mail
driver = webdriver.Chrome()
driver.get("https://www.126.com/")
#调用Mail类并接受driver驱动
mail = Mail(driver)
#登录账号为空
mail.login("","")
#用户名为空
mail.login("","password")
#密码为空
mail.login("username","")
#用户名/密码错误
mail.login("error","error")
#管理员登录
mail.login("admin","admin123")
#登录之后的操作
sleep(5)
#退出
mail.logout()
driver.quit()3.6多态
多态:不同的子类对象 调用相同的父类方法,产生不同的执行结果
•多态可以增加代码的灵活度
•以继承和重写父类方法为前提
•是调用方法的技巧,不会影响到类的内部设计
class MiniOS(object):
"""MiniOS 操作系统类 """
def __init__(self, name):
self.name = name
self.apps = [] # 安装的应⽤程序名称列表
def __str__(self):
return "%s 安装的软件列表为 %s" % (self.name, str(self.apps))
def install_app(self, app):
# 判断是否已经安装了软件
if app.name in self.apps:
print("已经安装了 %s,⽆需再次安装" % app.name)
else:
app.install()
self.apps.append(app.name)
class App(object):
def __init__(self, name, version, desc):
self.name = name
self.version = version
self.desc = desc
def __str__(self):
return "%s 的当前版本是 %s - %s" % (self.name, self.version, self.desc)
def install(self):
print("将 %s [%s] 的执⾏程序复制到程序⽬录..." % (self.name, self.version))
class PyCharm(App):
pass
class Chrome(App):
def install(self):
print("正在解压缩安装程序...")
super().install()
linux = MiniOS("Linux")
print(linux)
pycharm = PyCharm("PyCharm", "1.0", "python 开发的 IDE 环境")
chrome = Chrome("Chrome", "2.0", "⾕歌浏览器")
linux.install_app(pycharm)
linux.install_app(chrome)
linux.install_app(chrome)
print(linux)运行结果
3.7模块和包
模块
①概念
模块是 Python 程序架构的一个核心概念
•每一个以扩展名.py 结尾的 Python源代码文件都是一个模块
•模块名同样也是一个标识符,需要符合标识符的命名规则
•在模块中定义的全局变量 、函数、类都是提供给外界直接使用的工具
•模块就好比是工具包,要想使用这个工具包中的工具,就需要先导入这个模块
②模块的两种导入方式
import 导入
提示:在导入模块时,每个导入应该独占一行
import 模块名1
import 模块名2
导入之后 ,通过 模块名. 使用 模块提供的工具——全局变量、函数、类
如果模块的名字太长,可以使用 as 指定模块的名称,以方便在代码中的使用
实现:import 模块名1 as 模块别名 (模块别名应该符合大驼峰命名法)
import game_functions as gf
def run_game():
while True:
gf.check_events(ai_settings,screen,stats,sb,play_button,ship,aliens,bullets)
if stats.game_active:
gf.update_bullets(ai_settings,screen,stats,sb,ship,aliens,bullets)
gf.update_aliens(ai_settings,screen,sb,ship,aliens,stats,bullets)
gf.update_screen(ai_settings,screen,stats,sb,ship,aliens,bullets,play_button)
run_game()from...import 导入
•如果希望 从某一个模块 中,导入 部分 工具,就可以使用 from ... import 的方式
•import 模块名 是 一次性 把模块中 所有工具全部导入,并且通过 模块名/别名 访问
实现:from 模块名1 import 工具名
导入之后
◦不需要通过模块名.
◦可以直接使用模块提供的工具——全局变量、函数、类
注意:如果两个模块,存在同名的函数,那么后导入模块的函数,会覆盖掉先导入的函数
一旦发现冲突,可以使用 as 关键字 给其中一个工具起一个别名
# 从模块导入所有工具,提示:这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查
from 模块名1 import *
from settings import Settings
from ship import Ship
def run_game():
ai_settings = Settings()
ship = Ship(ai_settings,screen)
run_game()③模块的搜索顺序
Python的解释器在导入模块时,会:
1.搜索当前目录指定模块名的文件,如果有就直接导入
2.如果没有,再搜索系统目录
在开发时,给文件起名,不要和系统的模块文件重名
Python中每一个模块都有一个内置属性 __file__ 可以查看模块的完整路径
④原则——每一个文件都应该是可以被导入的
•一个独立的 Python 文件就是一个模块
•在导入文件时,文件中所有没有任何缩进的代码都会被执行一遍
实际开发场景:
•在实际开发中,每一个模块都是独立开发的,大多都有专人负责
•开发人员通常会在模块下方增加一些测试代码
◦仅在模块内使用,而被导入到其他文件中不需要执行
__name__ 属性
__name__ 属性可以做到,测试模块的代码只在测试情况下被运行,而在被导入时不会被执行!
•__name__ 是 Python 的一个内置属性,记录着一个 字符串
•如果 是被其他文件导入的,__name__ 就是 模块名
•如果 是当前执行的程序 __name__ 是 __main__
if __name__ == '__main__'表示:当模块被直接运行时,下面的代码块将被允许,当模块被其他程序文件调用时,下面的代码块不被运行。
if __name__ == '__main__':
#测试代码包(Package)
所有包都是模块,但并非所有模块都是包。 或者换句话说,包只是一种特殊的模块。 特别地,任何具有 __path__ 属性的模块都会被当作是包。
- 包是一个包含多个模块的特殊目录
- 目录下有一个特殊的文件__init__.py
- 包名的命名方式和变量名一致,小写字母 +“ _”
- 有了__init__.py我们可以轻易地from package import module
把普通目录文件变成package,只需要在下面新增一个__init__.py。
__init__.py
__init__.py默认为空,在import一个包的时候, 首先执行__init__.py的代码, 在导入某些子模块之前,如果需要进行某些初始化操作,那么写入__init__.py是一个好方法。
我们在导入一个包时,实际上导入了它的__init__.py文件。我们可以在__init__.py文件中再导入其他的包,或者模块。
这样,当我们导入这个包的时候,__init__.py文件自动运行。帮我们导入了这么多个模块,我们就不需要将所有的import语句写在一个文件里了,也可以减少代码量。不需要一个个去导入module了。
没有 init .py文件的目录,使用import x,会报错吗?
看版本,在较低的版本中(如3.2及以下),没有 init .py文件的目录不能使用import xx.xx导入相关模块,但是后面的版本可以。
__all__ 变量
使用‘import 包名’ ‘from 包名 import *’可以一次性导入包中所有的模块.
要在外界使用包中的模块,需要在__init__.py中指定对外界提供的模块列表。当用 import 导入package时,会首先执行 __init__.py 里面的代码。可以在__init__.py定义__all__ 变量,定义指定import *到底处理哪些模块。需要导入的模块。比如:
__all__ = ['subpackage_1', 'subpackage_2']4.其他
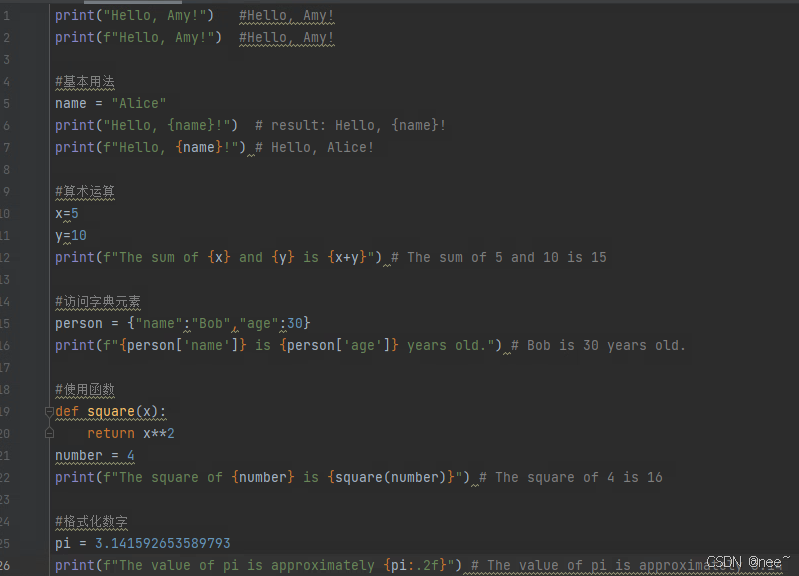
f-string
f-string是Python3.6版本开始引入的一种字符串格式化的语法,它允许在字符串中使用花括号{}来引用Python中的变量或表达式,并将它们的值插入到字符串中。这种语法简单易懂,使得字符串格式化变得更加简洁和高效。
f-string以f或F开头,后面跟着一个带有花括号的表达式,花括号中可以放置要引用的变量或表达式。例如:
name = "Tom"
age =18
print(f"My name is {name}, and I am {age} years old.")
输出结果就是:
My name is Tom, and I am 18 years old.
在下面的最后一个例子中,:.2f是一个格式说明符,它告诉Python将浮点数pi格式化为带有两位小数的字符串。
格式化字符串为字符串插值和格式化提供了一种简洁且可读的方式,尤其是在需要嵌入变量或执行简单计算时。与传统的字符串格式化方法(如%运算符或str.format()方法)相比,f-string通常更加直观和方便。

















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









