







字符串相关
字符串最后一个单词的长度
思路:
string.split(str="", num) 以 str 为分隔符拆分 string,str 默认包含 '\r', '\t', '\n' 和空格。
分割次数num默认为 -1, 即分隔所有。如果 num 有指定值,则仅分隔 num + 1 个子字符串。
'''
描述
对于给定的若干个单词组成的句子,每个单词均由大小写字母混合构成,单词间使用单个空格分隔。输出最后一个单词的长度。
输入描述:
在一行上输入若干个字符串,每个字符串代表一个单词,组成给定的句子。
除此之外,保证每个单词非空,由大小写字母混合构成,且总字符长度不超过 1000。
输出描述:
在一行上输出一个整数,代表最后一个单词的长度。
'''
str = input("请输入字符串")
LastWord = str.split()[-1]
print(len(LastWord))计算某字符出现次数
思路:字符串.count(数据) :数据在字符串中出现的次数,同样适用于元组等。
'''
对于给定的由大小写字母、数字和空格混合构成的字符串s,统计字符C在其中出现的次数。具体来说:
∙若C为大写或者小写字母,统计其大小写形态出现的次数和;
∙若C为数字,统计其出现的次数。
保证字符C仅为大小写字母或数字。
'''
def CountofChar():
str = input("请输入字符串")
str1 = str.upper()
char = input("请输入字符")
char1 = char.upper()
print(str1.count(char1))字符串分割 每行8个 不足8个后面补0
方法1
fromat() 字符串格式化
while True:
try:
l = input()
for i in range(0,len(l),8):
print("{0:0<8s}".format(l[i:i+8]))
except:
break输入
hellonowcoder
输出
hellonow
coder000
方法2
索引
l = input()
while len(l) > 0:
print(l[:8].ljust(8,"0"))
l = l[8:]进制转换
十进制转换为十六进制, :X 十六进制, :o八进制, :b二进制
n = int(input())
print("{:X}".format(n)) # 十进制转换为十六进制,且用大写字母表示
#输入10 输出A十六进制转换为十进制
class int(x, base=10)
- x -- 字符串或数字。
- base -- 进制数,默认十进制。
while True:
try:
n = input()
print(int(n,16))
except:
break质数因子
对于给定的整数n,从小到大依次输出它的全部质因子。比如180=2×2×3×3×5180=2×2×3×3×5 。
质因子(或质因数)在数论里是指能整除给定正整数的质数。平方根是为了减少循环次数,质因数个数不会大于平方根。
import math
n = int(input())
for i in range(2, int(math.sqrt(n))+1):
while n % i == 0:
print(i, end=' ')
n = n // i
if n > 2:
print(n)提取不重复的整数
n = input()
n = n[::-1]
num = []
for i in n:
if i in num: # 把不重复数字存入数组num
continue
else:
num.append(i)
print(i,end='')输入:12554
输出:4521
ASCII字符个数统计
对于给定的字符串,统计其中的 ASCIIASCII 在 00 到 127127 范围内的不同字符的个数。
n = input()
count = 0
n =set(n)
for i in n:
if 0<= ord(i) <= 127:
count += 1
print(count)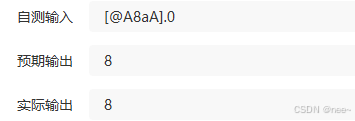
随机数
对于明明生成的 nn 个 11 到 500500 之间的随机整数,你需要帮助他完成以下任务:
∙ ∙删去重复的数字,即相同的数字只保留一个,把其余相同的数去掉;
∙ ∙然后再把这些数从小到大排序,按照排好的顺序输出。
你只需要输出最终的排序结果。
while True:
try:
n = input() #指定为N个数,输入
lst = [] #指定一个空列表
for i in range(int(n)): #循环N次
lst.append(int(input())) #空集合中追加一个N个数中的某一个随机数
uniq=set(lst) #列表去重,但是会变成无序
lst=list(uniq) #集合转列表
lst.sort() #列表排序
for i in lst:
print(i) #打印列表
except:
break输入

句子逆序
对于给定的若干个单词组成的句子,每个单词均由大小写字母混合构成,单词间使用单个空格分隔。输出以单词为单位逆序排放的结果,即仅逆序单词间的相对顺序,不改变单词内部的字母顺序。
n = input().split()[::-1]
for i in n:
print(i, end=' ')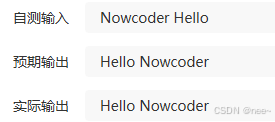
如果末尾有空格,可以用rstrip去除末尾空格。
字符串排序
对于给定的由大小写字母混合构成的 nn 个单词,输出按字典序从小到大排序后的结果。
从字符串的第一个字符开始逐个比较,直到找到第一个不同的位置,通过比较这个位置字符对应的 AsciiAscii 码( A<⋯<Z<a<⋯<zA<⋯<Z<a<⋯<z )得出字符串的大小,称为字典序比较。
n = input()
lst = []
for i in range(int(n)):
line = input()
lst.append(line)
for i in sorted(lst):
print(i)
数据加密
随机数num为四位数,对其按照如下的规则进行加密:
1.每一位分别加5,然后分别将其替换为该书除以10取余后的结果
2.将该数的第一位和第四位互换,第二位和第三位互换
3.最后合起来作为加密后的整数输出
输入描述:例如:输入:1000,输出5556
a = input()
b= []
for i in a:
b.append(str((int(i) + 5) % 10))
b.reverse()
print(''.join(b))
输入 1111 输出 6666
输入 2345 输出 0987
求十进制转换为二进制后1的个数
方法1:
n = input()
n = "{:b}".format(int(n))
print(n.count('1'))方法2:
num = int(input())
print(bin(num).count('1'))输入10 转换为二进制是1010 输出2
正则表达式练习——用split()制作一个电话簿
这里有一串电话簿信息,包含姓名、电话号码、房间号、地址。
import re
text = """Ross McFluff: 834.345.1254 155 Elm Street
Ronald Heathmore: 892.345.3428 436 Finley Avenue
Frank Burger: 925.541.7625 662 South Dogwood Way
Heather Albrecht: 548.326.4584 919 Park Place"""
#条目用一个或者多个换行符分开。现在我们将字符串转换为一个列表,每个非空行都有一个条目
entries = re.split("\n", text)
print(entries)
#最终,将每个条目分割为一个由名字、姓氏、电话号码和地址组成的列表
print("电话本:")
for entry in entries:
#:? 样式匹配姓后面的冒号,因此它不出现在结果列表中
ret = re.split(":? ", entry,3)
print(ret)结果:
['Ross McFluff: 834.345.1254 155 Elm Street', 'Ronald Heathmore: 892.345.3428 436 Finley Avenue', 'Frank Burger: 925.541.7625 662 South Dogwood Way', 'Heather Albrecht: 548.326.4584 919 Park Place']
电话本:
['Ross', 'McFluff', '834.345.1254', '155 Elm Street']
['Ronald', 'Heathmore', '892.345.3428', '436 Finley Avenue']
['Frank', 'Burger', '925.541.7625', '662 South Dogwood Way']
['Heather', 'Albrecht', '548.326.4584', '919 Park Place']
数组、集合相关
找出数组中出现次数最多的元素
方法1:
list = ['1', '2', '3', '6', '5', '6', '6', '2', '1']
list1 = set(list)
print(list1) #{'6', '2', '3', '1', '5'}
count = max(list1)
print(count) # 6 出现的数字最大的元素方法2:
使用numpy库
np.bincount():计算非负整数数组中每个值的出现次数(统计0~max出现的次数)。语法:numpy.bincount(x, weights=None, minlength=None)。
np.argmax:返回的是最大数的索引
import numpy as np
array = [0,1,2,2,3,4,4,4,5,6]
#np.bincount:首先找到数组最大值max,然后返回0~max的各个数字出现的次数,在上例中,0出现了1次,1出现了1次,2出现了2次...以此类推。np.bincount返回的数组中的下标对应的就是原数组的元素值。
print(np.bincount(array))
#np.argmax:返回数组中最大值对应的下标
print(np.argmax(np.bincount(array)))结果:
[1 1 2 1 3 1 1]
4
方法3:
Counter用来对数组中元素出现次数进行统计,然后通过most_common函数找到出现次数最多的元素。这种方法对于数组就没有过多限制,甚至是各种类型元素混合的数组也可以。
from collections import Counter
array = [0,1,2,2,3,4,4,4,5,6]
print(Counter(array))
print(Counter(array).most_common(1)[0][0])结果:
Counter({4: 3, 2: 2, 0: 1, 1: 1, 3: 1, 5: 1, 6: 1})
4
统计数组中每个元素出现的次数
List = [1,2,3,4,5,3,2,1,4,5,6,4,2,3,4,6,2,2]
List_set = set(List)
print(List_set)
for item in List_set:
print("the %d has found %d" % (item, List.count(item)))结果:
{1, 2, 3, 4, 5, 6}
the 1 has found 2
the 2 has found 5
the 3 has found 3
the 4 has found 4
the 5 has found 2
the 6 has found 2
或者 自己数各个元素出现的次数,然后找到出现次数最多的元素。max求最大值默认情况返回value值(出现次数)最大的key值(元素),而不是value值
appear_times = {}
list = [1,1,2,3,4,5,5,5]
for lable in list:
if lable in appear_times:
appear_times[lable] += 1
else:
appear_times[lable] = 1
most_common = max(appear_times)
print(appear_times)
print(most_common)结果:
{1: 2, 2: 1, 3: 1, 4: 1, 5: 3}
5
数组奇偶位交换数据
def swap_odd_even_positions(arr):
for i in range(0, len(arr)-1, 2):
arr[i], arr[i+1] = arr[i+1], arr[i]
return arr
# 示例
arr = [1, 2, 3, 4, 5]
print(swap_odd_even_positions(arr)) # 输出: [2, 1, 4, 3, 5]冒泡排序
冒泡排序(Bubble Sort)是最简单和最通用的排序方法,其基本思想是:在待排序的一组数中,将相邻的两个数进行比较,若前面的数比后面的数大就交换两数,否则不交换;如此下去,直至最终完成排序。由此可得,在排序过程中,大的数据往下沉,小的数据往上浮,就像气泡一样,于是将这种排序算法形象地称为冒泡排序。
比较第一个和第二个元素,看是否交换,再比较第二个第三个元素,看是否交换...一遍遍排序直到结束
优点:每趟结束时,不仅能挤出一个最大值到最后面位置,还能同时部分理顺其他元素;一旦下趟没有 交换发生,还可以提前结束排序。
def bubble_sort(nums):
for i in range(len(nums) - 1):
for j in range(len(nums) - i - 1):
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
return nums
if __name__ == '__main__':
l = [33, 11, 26, 78, 3, 9, 40]
print(l)
bubble_sort(l)
print(l) # [3, 9, 11, 26, 33, 40, 78]购物单问题/类似背包问题
主件可以没有附件,至多有 2个附件。
附件不再有从属于自己的附件。
如果要买归类为附件的物品,必须先买该附件所属的主件,且每件物品只能购买一次。
预算n元,给每件物品规定了一个重要度,用整数 1∼5 表示。他希望在花费不超过 n 元的前提下,使自己的满意度达到最大。
满意度是指所购买的每件物品的价格与重要度的乘积的之和。

字典
合并表记录
数据表记录包含表索引和数值,请对表索引相同的记录进行合并,即将相同索引的数值进行求和运算,随后按照索引值的大小从小到大依次输出。
方法1
n = int(input())
dic = {}
# idea: 动态建构字典
for i in range(n):
line = input().split()
key = int(line[0])
value = int(line[1])
dic[key] = dic.get(key,0) + value # 累积key所对应的value
for each in sorted(dic): # 最后的键值对按照升值排序
print(each, dic[each])
方法2
dic = {}
n = int(input())
while True:
try:
line = input()
tmp = line.split()
index = int(tmp[0])
value = int(tmp[1])
if index in dic:
dic[index] += value
else:
dic[index] = value
except:
break
for k, v in sorted(dic.items()):
print(f'{k} {v}')约瑟夫生者死者小游戏
问题描述:
30 个人在一条船上,超载,需要 15 人下船。于是人们排成一队,排队的位置即为他们的编号。
报数,从 1 开始,数到 9 的人下船。如此循环,直到船上仅剩 15 人为止,问都有哪些编号的人下船了呢?
解决思路:
给30个人编号1-30,每个人的初值都是1(在船上),i代表他们的编号,j代表被扔下船的人数(j=15时循环结束),用check记数,check=9时将对应编号i的人置0(扔下船)并让check重新记数。
当i等于31时,手动将i置为1
当对应编号i的人值为0时,代表此人已经不在船上,i+1找到下一个人记数,以此类推。
代码实现:
people={}
#此处for循环会输出{1: 1, 2: 1, 3: 1, ..., 30: 1},相当于给30个人都赋初始值1
for x in range(1,31):
people[x]=1
# print(people)
#check记数,0-9;i为人们的编号,1-30;j为下船的人数
check=0
i=1
j=0
while i<=31:
#因为只有30人,当i等于31时,手动将i置为1
if i == 31:
i=1
#下船15人后退出循环
elif j == 15:
break
else:
#people[i]为0时,表示此人已下船,i加1,check不增加,继续循环
if people[i] == 0:
i+=1
continue
else:
check += 1
# i=1,check=1,...i=9,check=9
if check == 9:
#数到9的人的值设为0(下船),check置0,重新开始计数
people[i]=0
check = 0
print("{}号下船了".format(i))
#j为下船的人数,下一个人j加1
j+=1
else:
i+=1
continue结果:

其他
获得当前项目所在根目录
方法1:
from os.path import dirname, relpath
from pathlib import Path
def get_root_folder():
path = Path(dirname(relpath(__file__)))
return path.resolve().parents[0]
ROOT_DIR = get_root_folder()
if __name__ == "__main__":
print(ROOT_DIR)输出:F:\study\python\huawei100code
方法2:
ROOT_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
银行家算法
[背景知识]
⼀个银⾏家如何将⼀定数⽬的资⾦安全地借给若⼲个客户,使这些客户既能 借到钱完成要⼲事,同时银⾏家⼜能收回全部资⾦⽽不⾄于破产,这就是银⾏家问题。这个问题同操作系统中资源分配问题⼗分相似:银⾏家就像⼀个操作系统,客户就像运⾏的进程,银⾏家的资⾦就是系统的资源。
[问题的描述]
⼀个银⾏家拥有⼀定数量的资⾦,有若⼲个客户要贷款。每个客户须在⼀开始就声明他所需贷款的总额。若该客户贷款总额不超过银⾏家的资⾦总数,银⾏家可以接收客户的要求。客户贷款是以每次⼀个资⾦单位(如1万RMB等)的⽅式进⾏的,客户在借满所需的全部单位款额之前可能会等待,但银⾏家须保证这种等待是有限的,可完成的。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









