




简说回归模型
回归模型是对统计关系进行定量描述的数学模型,研究的是因变量和自变量之间的关系。研究回归模型要用到回归方法,常见的回归方法有线性回归、逻辑回归、多项式回归等。
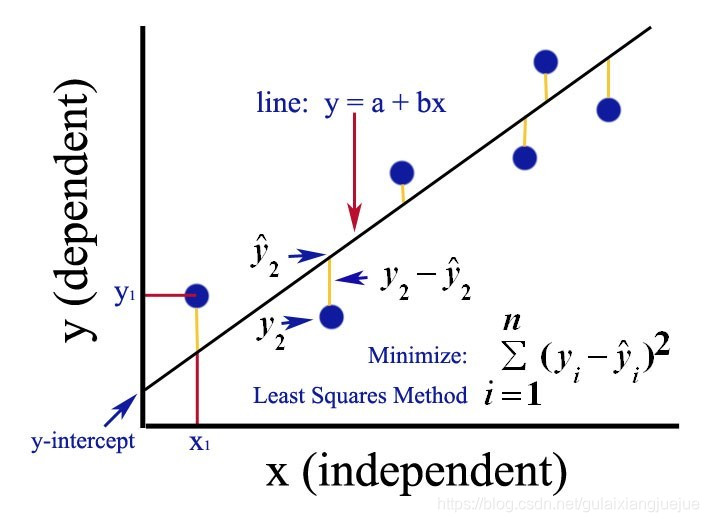
线性回归在自变量和因变量之间建立线性关系,如下图(图片来自网络):
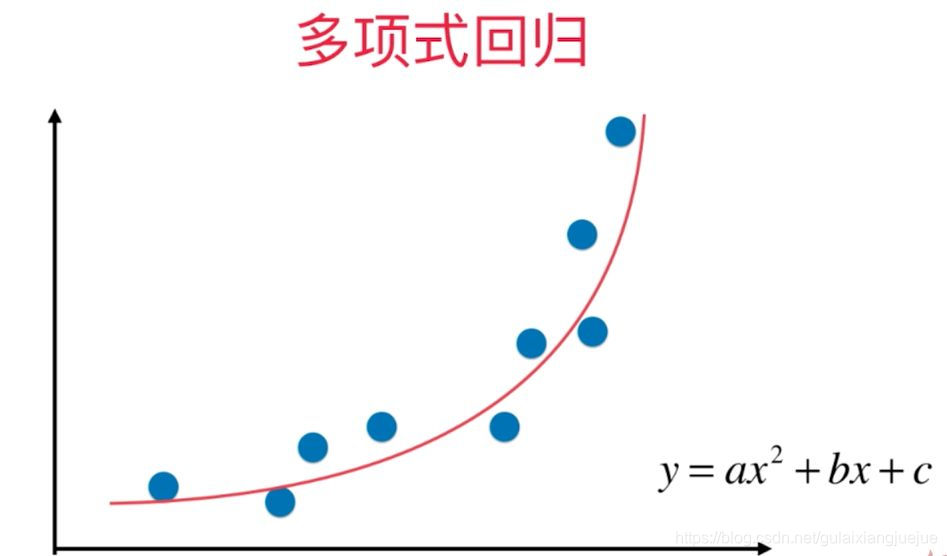
多项式回归模型对应自变量指数大于1的回归方程, 最佳拟合线是一条曲线,如下图:
逻辑回归模型介绍
首先介绍一下sigmoid函数:
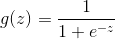
画出来图像如下图:
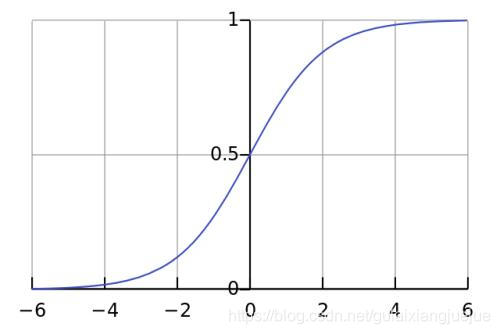
可以看到sigmoid函数中自变量z取值范围是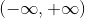 因变量g的取值范围是(0,1)。我们常用sigmoid函数做从实数到概率的映射。
因变量g的取值范围是(0,1)。我们常用sigmoid函数做从实数到概率的映射。
逻辑回归就是线性回归+sigmoid函数。
逻辑回归模型应用
##读取数据
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
train_data=pd.read_csv('datalab/14936/train_set.csv',nrows=5000)
#删除‘article’
train_data.drop(columns='article', inplace=True)
#TF-IDF文本处理
tfidf=TfidfVectorizer()
x_train=tfidf.fit_transform(train_data['word_seg'])
#将训练集拆分成训练集和测试集
y=train_data['class']
x_train,x_test,y_train,y_test=train_test_split(x_train,y,test_size=0.3,random_state=123)
##logistics regression
##模型中间的参数,C是用来确定模型对分类错误样本的敏感程度的,越小越不允许分错;dual表示采用对偶方法求解
from sklearn.linear_model import LogisticRegression
from sklearn import svm
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
lg = LogisticRegression(C=100, dual = True)
lg.fit(x_train, y_train)
lg_y_prediction = lg.predict(x_test)
label = []
for i in range(1, 20):
label.append(i)
f1 = f1_score(y_test, lg_y_prediction, labels=label, average='micro')
print('lg/The F1 Score: ' + str("%.2f" % f1))

















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









