







原文:XGBoost Algorithm: Long May She Reign!
这句话意思是XGBoost算法:她可能会长期统治。虽然现在有了lightGBM,但还是有必要学习下XGBoost 这一经典算法。以下是翻译内容:
我仍然记得15年前我第一份工作的第一天。我刚完成我的毕业设计,加入了一个全球的投资银行做分析师。我上班第一天,我拉直我的领带,尝试回忆所有学过的知识。在此期间,我深深怀疑我对企业而言是否足够优秀,我的老板感觉到我的忧虑,笑着说:别紧张,你需要知道的唯一东西是回归模型!
我记得内心想着:“我懂了”。我知道回归模型,包括线性回归和逻辑回归。我的老板是对的,在我的工作期间,我只构建基于回归的统计模型。我并不孤独,事实上在那时候,回归模型是预测分析的毫无争议的女王。如今15年了,回归模型的时代已过,年迈的女王过世了。有着时髦名称的新的女王将永存:XGBoost 或者叫 极端梯度提升。
XGBoost 是什么?
XGBoost 是基于决策树的集成机器学习算法 ,使用了 梯度提升 框架. 在涉及无结构数据(图像、文本等)的预测问题中,人工神经网络比所有其他算法框架都优越。 然而,当面临小到中型结构化数据时,决策树被认为是最好的。树算法这些年的演变见下图:
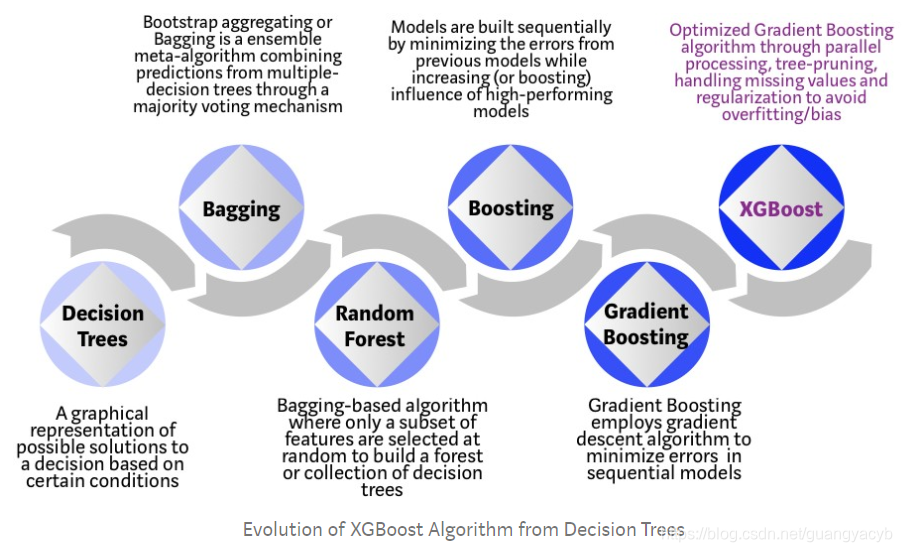
- 决策树:基于指定条件下,某决策的可行解的图形化表示
- bagging:引导聚集算法或bagging,是一种集成元算法,将多个决策树的预测结合,用多数投票机制做决策
- 随机森林:基于bagging的算法,随机选择部分特征来建立森林或决策树集合
- 提升:按序建立模型,以最小化前一个模型的误差,并提升高性能模型的影响
- 梯度提升:引入梯度下降算法来最小化顺序模型的误差
- XGBoost:通过并行处理、树剪枝、处理缺失值、正则化来避免过拟合,以优化梯度提升算法
XGBoost 算法是在华盛顿大学一项研究项目中开发的,Tianqi Chen and Carlos GuestrinTianqi Chen and Carlos Guestrin将他们的论文2016年发表于 SIGKDD 会议,点爆了整个机器学习界。该算法不仅赢得了众多Kaggle竞赛的殊荣,而且还成为许多先进行业应用的幕后推手。因此,有一个数据科学家社区投入到了XGBoost 开源项目中——350 贡献者 ~3,600 次提交 GitHub。这个算法的特殊性在于:
- 应用广泛: 可用于解决回归、分类、排序、用户定义的预测问题
- 可移植:可以在Windows, Linux, OS X 下流畅运行.
- 语言:支持所有主要编程语言 C++, Python, R, Java, Scala, ulia.
- 云集成: 支持AWS, Azure, Yarn 集群 ,与 Flink, Spark 协作.
如何直观理解XGBoost?
决策树最简单的形式,容易可视化也可解释,但建立对下一代基于树的算法的直观理解有点困难,阅读下文以更好理解树算法的演进。
想象你是一个招聘经理,正在面试几位资历不错的候选人。树算法的每一步演进可以视为面试过程的一个版本。
- 决策树: 每个招聘经理有一套标准,如教育水平、工作年限、面试表现。决策树类似招聘经理用他的标准来面试候选人。
- Bagging: 想象有多个面试官,每个面试官可以投票, Bagging 或 引导聚合将所有面试官的观点作为最终的参考,利用民主投票.
- 随机森林: 是基于bagging的算法, 但有一个关键区别,在于会随机选择一部分特征. 换句话说,每位面试官只考察候选人的随机几个方面特质 (如,技术面试考察编程能力,行为面试考察非技术能力)
- 提升: 这是一种替代方法,每位面试官根据上一位面试官的反馈修改评价标准. 通过更加动态的评价过程提升了面试效率.
- 梯度提升: 提升的一个特殊情况,通过梯度下降来对误差最小化。(咨询公司,并使用动态的面试过程排除不合格候选之人).
- XGBoost: XGBoost 可以认为是梯度提升的类固醇 (称作‘极端梯度提升’). 完美结合了软件和硬件的优化技术,在更短的时间更少的计算资源下达到更出色的结果
为什么XGBoost 表现这么好?
XGBoost 和梯度提升机 (GBMs) 都是集成树方法 ,对使用梯度下降的弱学习器(一般是CARTs )运用提升原理。然而XGBoost 通过系统优化和算法改进对GBM框架进行了改造。
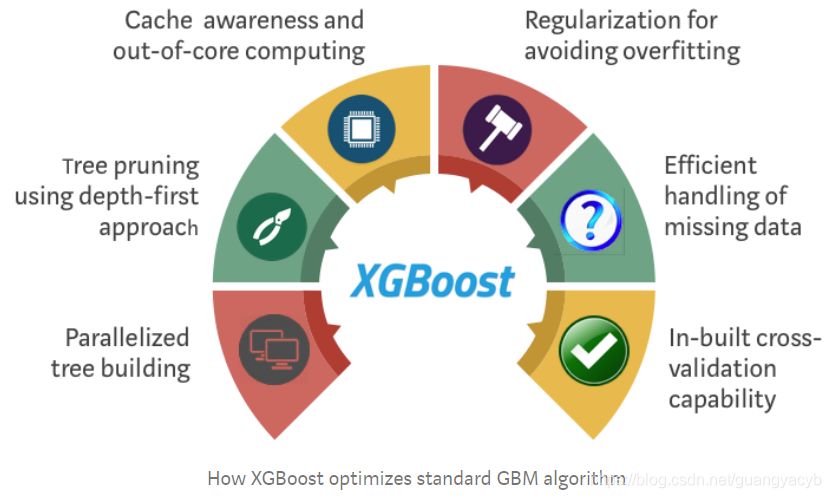
系统优化:
- 并行化: XGBoost 使用并行实现来完成按序构建树的过程。 这是可行的,源于构建基础学习器时的循环的可互换性:外层循环遍历一棵树的叶子节点,内部第二层循环计算特征. 这种循环的叠加限制了并行化,因为内部循环(需要更多计算量)完成前,外层循环无法继续。因此为了改进运行时间,通过全局扫描所有实例,用线程并行对其排序,交换两个循环的位置。这个交换改进了算法性能,抵消了计算中的任何并行化开销。
- 树剪枝: GBM 框架中树分割的停止条件取决于分割点的负损失准则。 XGBoost 使用最大深度参数‘max_depth’ 作为准则,并开始反向对树剪枝。这个基于深度的准则极大改进了计算性能.
- 硬件优化: 这个算法被设计为可高效利用硬件资源。这是通过缓存机制,为每个线程分配内部缓冲区以存放梯度信息,更多改进如“核外计算”在处理无法放入内存的大规模数据时优化了可用的磁盘空间。
算法改进:
- 正则化: 通过 LASSO (L1) 和 Ridge (L2) 正则化 来惩罚复杂的模型,避免过拟合
- 稀疏意识: XGBoost 可接受稀疏特征作为输入,依据训练损失自动学习最佳缺失值,更高效的处理数据中不同类型的 稀疏模式
- 加权分位数略图: XGBoost引入分布式 加权分位数略图算法 在加权数据集中高效的找到最佳分割点.
- 交叉验证: 算法在每次迭代内置了 交叉验证 , 使得在单次运行中不必显示编程搜索并指定迭代次数.
证明在哪?
我们使用Scikit-learn 的 ‘Make_Classification’ 数据包来创建100万个20个特征(2 个有用的 2 个多余的)的随机样本. 我们对不同的算法如:逻辑回归、随机森林、标准梯度提升,XGBoost 进行测试.
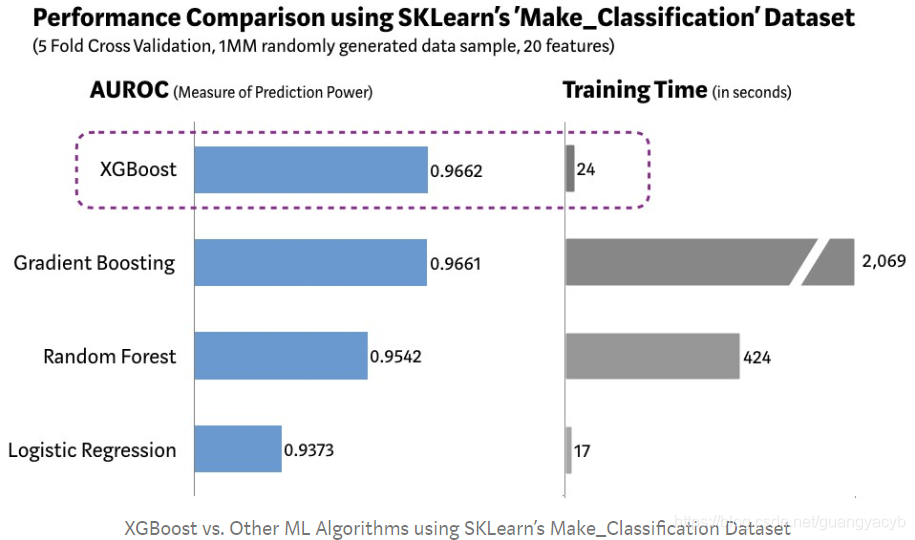
正如上表所示, XGBoost 有着最佳的预测性能和处理时间。其他 benchmarking 研究也得到类似结果。难怪 XGBoost 会用于最近的比赛中.
“When in doubt, use XGBoost” — Owen Zhang, Avito 广告点击预测比赛的胜者
我们是否应一直只用XGBoost?
当来到机器学习 (或是生活中), 并没有免费的午餐。作为数据科学家, 我们必须对手里的数据尝试所有算法来得知最佳算法. 此外,选择最佳算法还不够. 我们必须通过调整超参数以选择正确的算法配置。另外,对于最佳算法的选择还要考虑计算复杂度,可解释性,可实现难易度。这就是机器学习从科学走向艺术的点,魔法的所在。
未来何去何从?
机器学习是非常活跃的研究领域,并且已有可替代XGBoost 的选择. 微软最近发布的 LightGBM 框架展现了良好的潜力. Yandex 技术 开发的CatBoost 也展示了印象深刻的成果。我们何时会有一个更好的框架在预测性能、灵活性、可解释性、实用性上打败XGBoost 只是时间问题。但在它来临前,XGBoost仍然会统治机器学习领域一段时间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









