







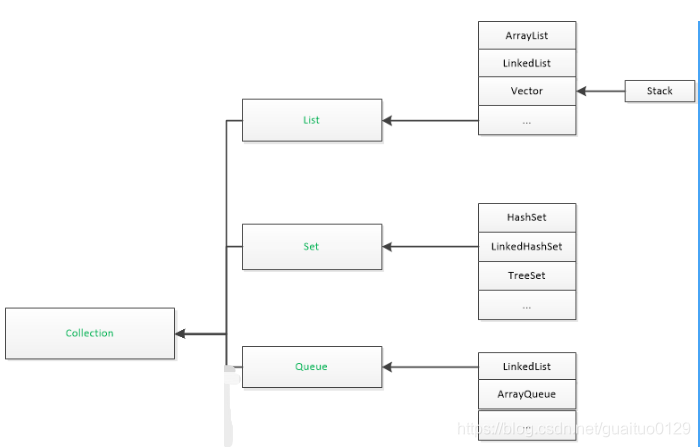
1.Collection常用接口及子类
Collection 表示一组对象,不包括Map
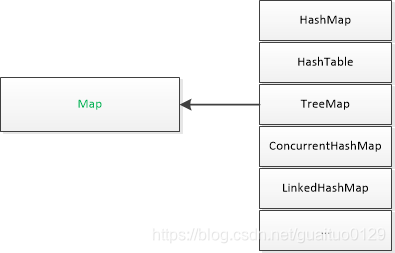
2.Map :将键映射到值的对象。
3.面试常见问题
3.1 ArrayList和Vector的区别
相同点:这两个类都实现了List接口(List接口继承了Collection接口),他们都是有序集合,即存储在这两个集合中的元素的位置都是有顺序的,相当于一种动态的数组,我们以后可以按位置索引号取出某个元素,,并且其中的数据是允许重复。
不同点:(1)同步性:Vector是线程安全的,,而ArrayList是线程序不安全的。(2)数据增长:ArrayList与Vector都有一个初始的容量大小。Vector增长原来的一倍,ArrayList增加原来的0.5倍。
3.2 HashMap和Hashtable的区别
1.HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
2.HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。
3.Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
4.Hashtable的方法是Synchronize的,而HashMap不是
3.3 HashMap和ConcurrentHashMap的区别
- HashMap非线程安全,若想实现同步,则需要使用Collection.synchronized(hashmap)方法,锁住的是整个方法
- ConcurrentHashMap使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。(jdk1.8之后,针对每个bucket分配一把锁)
3.4 为什么重写对象的equals()方法,就必须重写hashCode()方法
两个对象若相同,则HasCode一定相同;HashCode相同,但对象不一定相同。
HashMap中判断key值是否重复的步骤,是先判断对象的hashCode是否已存在,该hashCode不存在,则可以存入;hashCode已存在,则再利用equals方法判断是否重复。故如果重写了equals()方法,而没有重写HashCode()方法,理论上是重复值,但却可以存入,属于错误操作。
3.5 HashMap的put()方法执行逻辑
- Map是否为空,为空则初始化大小(1<<4),默认容量为16
- 对Key求hash值,然后计算数组下标(HashMap存储数据格式为 数组+链表+红黑树(1.8之后))
- 检查是否发生碰撞,没有则直接存入
- 发生碰撞则以链表的方式添加到链表尾部
- 如果链表的长度大于阀值(默认是8),则将链表转为红黑树结构
- 如果链表的长度小于阀值(默认是6),则将红黑树转回链表格式
- 如果该key已存在,则替换该节点内容
- 如果数组已满(即达到 容量*负载因子,默认16*0.75),则resize扩容2倍(x>>1)
3.6 HashMap的长度为什么要求是2的N次方
hashMap采用的数组+链表的结构,要求需要先找到bucket的位置,即数组索引。而其中为了快速取余,利用了一个等式:
当n是2的N次方时: 。
为什么这个等式相等呢,举个例子:17%4 = 17&3:
![]()
取到的都是图中后面两位二进制结果,故等式成立
3.7 解决哈希冲突的几种方法
- 开放定址法:一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,常用的有线性探测法、二次探测法
- 拉链法:即hashMap中使用的数组+链表结构,当发生冲突时,加入到链表中
- 再散列法:当发生冲突时,则再次使用其他散列方法计算hash值,直到找到合适的位置

















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









