







文章目录
PaperInfo
| 属性 | 属性值 |
|---|---|
| 论文名称 | FCOS: Fully Convolutional One-Stage Object Detection |
| 论文地址 | https://arxiv.org/abs/1904.01355 |
| 论文代码 | https://tinyurl.com/FCOSv1 |
Abstract
We propose a fully convolutional one-stage object detector (FCOS) to solve object detection in a per-pixel prediction fashion, analogue to semantic segmentation. Almost all state-of-the-art object detectors such as RetinaNet, SSD, YOLOv3, and Faster R-CNN rely on pre-defined anchor boxes. In contrast, our proposed detector FCOS is anchor box free, as well as proposal free. By eliminating the predefined set of anchor boxes, FCOS completely avoids the complicated computation related to anchor boxes such as calculating overlapping during training. More importantly, we also avoid all hyper-parameters related to anchor boxes, which are often very sensitive to the final detection performance. With the only post-processing non-maximum suppression (NMS), FCOS with ResNeXt-64x4d-101 achieves 44.7% in AP with single-model and single-scale testing, surpassing previous one-stage detectors with the advantage of being much simpler. For the first time, we demonstrate a much simpler and flexible detection framework achieving improved detection accuracy. We hope that the proposed FCOS framework can serve as a simple and strong alternative for many other instance-level tasks. Code is available at:Code is available at: https://tinyurl.com/FCOSv1
本文提出了一种全卷积的单阶段目标检测器(FCOS),以逐像素(per-pixel)预测方式解决目标检测问题,类似于语义分割。几乎所有现阶段最好的目标检测器,如:RetinaNet,SSD,YOLOv3,and Faster R-CNN 都依赖于预先定义的anchor boxes。相反,我们提出的FCOS检测器不需要anchor boxes,也不需要区域建议(proposal),FCOS完全避免了关于anchor boxes的复杂计算,如:在训练阶段的IoU计算,更重要的是,FCOS还避免了与anchor boxes相关的所有超参数,这些超参数一般对最终的预测结果非常敏感。通过唯一的后处理部分——非最大抑制(NMS),使用ResNeXt-64x4d-101作为backbone的FCOS在单模型(single-model)和单尺寸(single-scale)的AP测试中达到了44.7%,超过了之前的单阶段检测器,并且比这些单阶段目标检测器更加简单。首次展示了一个更简单、更灵活的检测框架,从而提高了检测精度。希望FCOS框架可以作为其他实例级(instance-level)检测任务简单而强大的替代方案。
1 Introduction
Object detection is a fundamental yet challenging task in computer vision, which requires the algorithm to predict a bounding box with a category label for each instance of interest in an image. All current mainstream detectors such as Faster R-CNN , SSD and YOLOv2, v3 rely on a set of pre-defined anchor boxes and it has long been believed that the use of anchor boxes is the key to detectors’ success. Despite their great success, it is important to note that anchor-based detectors suffer some drawbacks: 1)detection performance is sensitive to the sizes, aspect ratios and number of anchor boxes. For example, in RetinaNet, varying these hyper-parameters affects the performance up to 4% in AP on the COCO benchmar. As a result, these hyper-parameters need to be carefully tuned in anchor-based detectors. 2) Even with careful design, because the scales and aspect ratios of anchor boxes are keptfixed, detectors encounter difficulties to deal with object candidates with large shape variations, particularly for small objects. The pre-defined anchor boxes also hamper the generalization ability of detectors, as they need to be re-designed on new detection tasks with different object sizes or aspect ratios. 3) In order to achieve a high recall rate, an anchor-based detector is required to densely place anchor boxes on the input image (e.g., more than 180K anchor boxes in feature pyramid networks (FPN) for an image with its shorter side being 800). Most of these anchor boxes are labelled as negative samples during training. The excessive number of negative samples aggravates the imbalance between positive and negative samples in training. 4) Anchor boxes also involve complicated computation such as calculating the intersection-over-union (IoU) scores with ground-truth bounding boxes.
在计算机视觉中,目标检测是一项基础但是具有挑战性的任务,要求算法可预测图像中每个目标的边界框和类别标签。当前所有主流的检测算法,例如Faster R-CNN , SSD和YOLOv2/v3,都依赖于一组预先定义的Anchor Boxes,而且人们一直认为Anchor Boxes的使用是检测器成功的关键。尽管它们取得了巨大的成功,但依然应该注意基于Anchor的检测器存在一些缺点。
1)基于Anchor Boxes的目标检测模型的检测性能对Anchor Boxes的尺寸(size)、长宽比(aspect ratios)和数量(number)很敏感。例如,在RetinaNet中,改变这些超参数会影响其性能,在COCO benchmar上这些参数对AP的影响高达4%。因此,在基于Anchor的检测器中这些超参数需要仔细调整。
2)即使精心设计,由于Anchor Boxes的比例和长宽比是固定的,检测器在处理具有较大形状变化的候选目标时也会遇到困难,特别是对于小目标。预先定义的Anchor Boxes还妨碍了检测器的泛化能力,因为它们需要在具有不同目标尺寸或长宽比的新检测任务中重新设计。
3)为了实现高召回率,基于Anchor的检测器需要在输入图像上密集地放置Anchor Boxes(例如,对于短边为800的图像,在特征金字塔网络(FPN)中需要超过180K的Anchor Boxes)。在训练过程中,这些Anchor Boxes大部分被标记为负样本。负样本的数量过多,加剧了训练中正负样本之间的不平衡。
4) Anchor Boxes还涉及复杂的计算,如计算与GTBox的IoU分数。
Recently, fully convolutional networks (FCNs) have achieved tremendous success in dense prediction tasks such as semantic segmentation, depth estimation, keypoint detection and counting. As one of high-level vision tasks, object detection might be the only one deviating from the neat fully convolutional perpixel prediction framework mainly due to the use of anchor boxes. It is nature to ask a question: Can we solve object detection in the neat per-pixel prediction fashion, analogue to FCN for semantic segmentation, for example? Thus those fundamental vision tasks can be unified in (almost) one single framework. We show that the answer is affirmative. Moreover, we demonstrate that, for thefirst time, the much simpler FCN-based detector achieves even better performance than its anchor-based counterparts.
最近,全卷积网络(FCN)在密集预测任务中取得了巨大的成功,如语义分割、深度估计、关键点检测和计数。作为高级视觉任务之一,目标检测可能是唯一一个偏离整齐的全卷积逐像素预测框架的任务,这主要是因为使用了Anchor Boxes。 由此,可以很自然的提出一个问题:能否以整齐的单像素预测方式解决目标检测问题,例如类似于语义分割中的FCN模型?这会让这些基本的视觉任务可以(几乎)被统一在一个单一的框架中。经过一系列的探索,本文给出的答案是肯定的。此外,本文首次证明,基于FCN的更简单的检测器甚至比基于anchor的同类检测器的性能更好。
In the literature, some works attempted to leverage the FCNs-based framework for object detection such as DenseBox. Specifically, these FCN-based frameworks directly predict a 4D vector plus a class category at each spatial location on a level of feature maps. As shown in Fig. 1 (left), the 4D vector depicts the relative offsets from the four sides of a bounding box to the location. These frameworks are similar to the FCNs for semantic segmentation, except that each location is required to regress a 4D continuous vector. However, to handle the bounding boxes with different sizes, DenseBox crops and resizes training images to a fixed scale. Thus DenseBox has to perform detection on image pyramids, which is against FCN’s philosophy of computing all convolutions once. Besides, more significantly, these methods are mainly used in special domain objection detection such as scene text detection or face detection, since it is believed that these methods do not work well when applied to generic object detection with highly overlapped bounding boxes. As shown in Fig. 1 (right), the highly overlapped bounding boxes result in an intractable ambiguity: it is not clear w.r.t. which bounding box to regress for the pixels in the overlapped regions.
很多工作都试图利用基于FCN的框架进行目标检测,如DenseBox。具体来说,这些基于FCN的框架在特征图级别上对每个空间位置直接预测一个4D向量和类别。如图1(左)所示,4D向量描述了从Bounding Boxes的四边到该位置的相对偏移量。这些框架与用于语义分割的FCN相似,只是每个位置都需要回归一个4D连续向量。然而,为了处理不同大小的Bounding Boxes,DenseBox将训练图像裁剪并调整为固定的比例。因此,DenseBox必须对图像金字塔进行检测,这与FCN的所有卷积一次计算的理念相悖。此外,更重要的是,这些方法主要用于特殊领域的目标检测,如场景文本检测或人脸检测,因为人们认为这些方法在应用于具有高度重叠Bounding Boxes的通用目标检测时效果不佳。如图1(右)所示,高度重叠的Bounding Boxes导致了难以解决的不确定性:对于重叠区域的像素,不清楚应该回归哪个Bounding Boxes。

图1
In the sequel, we take a closer look at the issue and show that with FPN this ambiguity can be largely eliminated. As a result, our method can already obtain comparable detection accuracy with those traditional anchor based detectors. Furthermore, we observe that our method may produce a number of low-quality predicted bounding boxes at the locations that are far from the center of an target object. In order to suppress these low-quality detections, we introduce a novel“center-ness” branch (only one layer) to predict the deviation of a pixel to the center of its corresponding bounding box, as defined in Eq. (3). This score is then used to down-weight low-quality detected bounding boxes and merge the detection results in NMS. The simple yet effective center-ness branch allows the FCN-based detector to outperform anchor-based counterparts under exactly the same training and testing settings.
下文将仔细研究这个问题,并表明使用FPN可以在很大程度上消除这种不确定性。基于此,本文的方法已经可以获得与传统的基于Anchor的检测器相当的检测精度。此外,本文的方法可能会在远离目标中心的位置产生一些低质量的预测Bounding Boxes。为了抑制这些低质量的检测,FCOS引入了一种新颖的 "center-ness(中心度)"分支(只有一层)来预测单像素点对其相应Bounding Boxes中心的偏差,如公式(3)所定义。然后,这个分数被用来降低检测到的低质量Bounding Boxes的权重,并将检测结果合并到NMS中。简单而有效的center-ness分支使得基于FCN的检测器在完全相同的训练设置和测试设置下,表现优于基于anchor的同类检测器。
This new detection framework enjoys the following advantages.
- Detection is now unified with many other FCNsolvable tasks such as semantic segmentation, making it easier to re-use ideas from those tasks.
- Detection becomes proposal free and anchor free, which significantly reduces the number of design parameters. The design parameters typically need heuristic tuning and many tricks are involved in order to achieve good performance. Therefore, our new detection framework makes the detector, particularly its training, considerably simpler.
- By eliminating the anchor boxes, our new detector completely avoids the complicated computation related to anchor boxes such as the IOU computation and matching between the anchor boxes and ground-truth boxes during training, resulting in faster training and testing as well as less training memory footprint than its anchor-based counterpart.
- Without bells and whistles, we achieve state-of-theart results among one-stage detectors. We also show that the proposed FCOS can be used as a Region Proposal Networks (RPNs) in two-stage detectors and can achieve significantly better performance than its anchor-based RPN counterparts. Given the even better performance of the much simpler anchor-free detector, we encourage the community to rethink the necessity of anchor boxes in object detection, which are currently considered as the de facto standard for detection.
- The proposed detector can be immediately extended to solve other vision tasks with minimal modification, including instance segmentation and key-point detection. We believe that this new method can be the new baseline for many instance-wise prediction problems.
这个新的检测框架具有以下优势:
-
将检测任务与许多其他FCN可解决的任务(如语义分割)统一起来,使之更容易重新使用这些任务的想法。
-
将目标检测任务进行了proposal-free和anchor-free改进,这大大减少了设计参数的数量。设计参数通常需要启发式的调整,为了达到良好的性能,会涉及许多技巧。因此,这个新检测框架使检测器,特别是其训练,变得相当简单。
-
通过消除Anchor Boxes,FCOS完全避免了与Anchor Boxes有关的复杂计算,如IoU计算和训练期间Anchor Boxes与真实框之间的匹配,从而使训练和测试更快,并且比基于Anchor Boxes的对应物的训练内存占用(memory footprint)更少。
-
在没有附加条件的情况下,FCOS在单阶段检测器中取得了最优的结果,除此之外,FCOS可以作为两阶段检测器中的区域提议网络(RPNs),并且可以取得比基于Anchor的RPN模块更好的性能。更简单的Anchor-free检测器的性能甚至更好。本文鼓励目标检测任务的研究者们重新思考目标检测中Anchor Boxes的必要性,目前Anchor Boxes被认为是目标检测任务的标准。
-
本文所提出的检测器可以快速扩展到解决其他视觉任务,只需最小的修改,包括实例分割和关键点检测,这种新方法可以成为许多实例预测问题的新基准。
2 Related Work
Anchor-based Detectors. Anchor-based detectors inherit the ideas from traditional sliding-window and proposal based detectors such as Fast R-CNN. In anchor-based detectors, the anchor boxes can be viewed as pre-defined sliding windows or proposals, which are classified as positive or negative patches, with an extra offsets regression to refine the prediction of bounding box locations. Therefore, the anchor boxes in these detectors may be viewed as training samples. Unlike previous detectors like Fast RCNN, which compute image features for each sliding window/proposal repeatedly, anchor boxes make use of the feature maps of CNNs and avoid repeated feature computation, speeding up detection process dramatically. The design of anchor boxes are popularized by Faster R-CNN in its RPNs, SSD and YOLOv2, and has become the convention in a modern detector.
基于Anchor的检测器。 基于Anchor的检测器继承了传统的sliding-window滑动窗口和基于proposal区域建议检测器的思想,如Faster R-CNN。在基于Anchor的检测器中,Anchor Box可以被看作是预先定义的滑动窗口或Proposal,它们被分类为正Anchor或负Anchor,通过一个额外的偏移量回归来调整对Bounding Boxes位置的预测。因此,这些检测器中的Anchor Box可以被看作是训练样本。与以前的检测器不同(如Fast RCNN反复计算每个滑动窗口/区域建议),Faster RCNN中Anchor Boxes利用了CNN的特征图,避免了重复的特征计算,大大加快了检测过程。Anchor Box的设计由Faster R-CNN在其RPNs、SSD和YOLOv2中得到推广,并成为现代检测器的惯例。
However, as described above, anchor boxes result in excessively many hyper-parameters, which typically need to be carefully tuned in order to achieve good performance. Besides the above hyper-parameters describing anchor shapes, the anchor-based detectors also need other hyper-parameters to label each anchor box as a positive, ignored or negative sample. In previous works, they often employ intersection over union (IOU) between anchor boxes and ground-truth boxes to determine the label of an anchor box (e.g., a positive anchor if its IOU is in [0.5, 1]). These hyper-parameters have shown a great impact on the final accuracy, and require heuristic tuning. Meanwhile, these hyper-parameters are specific to detection tasks, making detection tasks deviate from a neat fully convolutional network architectures used in other dense prediction tasks such as semantic segmentation.
然而,如上所述,Anchor Box导致了过多的超参数,为了达到良好的性能,通常需要仔细调整。除了上述描述Anchor形状的超参数外,基于Anchor的检测器还需要其他的超参数来标记每个Anchor Box为positive、ignore或negative。在之前的工作中,通常采用Anchor Box和GTBox之间的IoU来确定Anchor Box的标签(例如,如果其IoU在[0.5, 1]之间,则为positive anchor)。这些超参数对最终的精确度有很大的影响,需要启发式的调整。同时,这些超参数是针对检测任务的,这些专有参数使得检测任务偏离了其他密集型预测任务(如语义分割)中使用的整齐的全卷积网络架构。
Anchor-free Detectors. The most popular anchor-free detector might be YOLOv1 . Instead of using anchor boxes, YOLOv1 predicts bounding boxes at points near the center of objects. Only the points near the center are used since they are considered to be able to produce higherquality detection. However, since only points near the center are used to predict bounding boxes, YOLOv1 suffers from low recall as mentioned in YOLOv2. As a result, YOLOv2 [22] employs anchor boxes as well. Compared to YOLOv1, FCOS takes advantages of all points in a ground truth bounding box to predict the bounding boxes and the low-quality detected bounding boxes are suppressed by the proposed “center-ness” branch. As a result, FCOS is able to provide comparable recall with anchor-based detectors as shown in our experiments.
Anchor-free检测器。最流行的Anchor-free检测器可能是YOLOv1。YOLOv1不使用Anchor Box,而是在目标中心附近的点预测Bounding Box。它只有靠近中心的点才被使用,因为这些点被认为能够产生更高质量的检测。然而,由于只有靠近中心的点才被用来预测Bounding Box,所以造成了YOLOv1的召回率比较低。因此,YOLOv2也采用了Anchor Boxes。与YOLOv1相比,FCOS利用GTBox中的所有点来预测Bounding Boxes,并通过本文提出的 "center-ness"分支来抑制检测到的低质量Bounding Box。因此,如本文的实验所示,FCOS能够提供与基于Anchor的检测器相当的召回率。
CornerNet is a recently proposed one-stage anchor-free detector, which detects a pair of corners of a bounding box and groups them to form the final detected bounding box. CornerNet requires much more complicated postprocessing to group the pairs of corners belonging to the same instance. An extra distance metric is learned for the purpose of grouping.
CornerNet是最近提出的一个单阶段Anchor-free检测器,它检测一个Bounding Boxes的一对角点并将它们分组以形成最终检测的Bounding Boxes。CornerNet需要更复杂的后处理来分组属于同一实例的一对角点。为了分组的目的,需要学习额外的距离度量。
Another family of anchor-free detectors such as [32] are based on DenseBox [12]. The family of detectors have been considered unsuitable for generic object detection due to difficulty in handling overlapping bounding boxes and the recall being relatively low. In this work, we show that both problems can be largely alleviated with multi-level FPN prediction. Moreover, we also show together with our proposed center-ness branch, the much simpler detector can achieve even better detection performance than its anchor-based counterparts.
另一个Anchor-free检测器系列是基于DenseBox的。由于难以处理重叠的Bounding Boxes,而且召回率相对较低,该系列检测器被认为不适合于一般的目标检测。在这项工作中,本文表明这两个问题可以通过多级FPN预测得到很大程度的缓解。此外,与本文提出的center-ness分支一起,更简单的检测器甚至可以达到比基于Anchor的同类检测器更好的检测性能。
3 Our Approach
In this section, we first reformulate object detection in a per-pixel prediction fashion. Next, we show that how we make use of multi-level prediction to improve the recall and resolve the ambiguity resulted from overlapped bounding boxes. Finally, we present our proposed “centerness” branch, which helps suppress the low-quality detected bounding boxes and improves the overall performance by a large margin.
1 以单像素预测的方式重新表述目标检测。
2 展示了如何利用多级预测(multi-level prediction)来提高召回率,并解决由重叠的Bounding Box导致的模糊性。
3 介绍了本文提出的"center-ness”分支,它有助于抑制低质量的检测Bounding Box,并以很大的幅度提高整体性能。
3.1 Fully Convolutional One-Stage Object Detector
Let F i ∈ R H × W × C F_i∈R^{H×W×C} Fi∈RH×W×C be the feature maps at layer i i i of a backbone CNN and s s s be the total stride until the layer. The ground-truth bounding boxes for an input image are defined as B i {Bi} Bi, where B i = ( x 0 ( i ) , y 0 ( i ) , x 1 ( i ) , y 1 ( i ) , c ( i ) ) ∈ R 4 × { 1 , 2... C } B_i=(x^{(i)}_0,y^{(i)}_0,x^{(i)}_1,y^{(i)}_1,c^{(i)})∈\mathbb R^4×\{1,2...C\} Bi=(x0(i),y0(i),x1(i),y1(i),c(i))∈R4×{1,2...C}. Here ( x 0 ( i ) , y 0 ( i ) ) (x^{(i)}_0,y^{(i)}_0) (x0(i),y0(i)) and ( x 1 ( i ) , y 1 ( i ) ) (x^{(i)}_1,y^{(i)}_1) (x1(i),y1(i)) denote the coordinates of the left-top and right-bottom corners of the bounding box. c ( i ) c^{(i)} c(i) is the class that the object in the bounding box belongs to. C is the number of classes, which is 80 for MS-COCO dataset.
设 F i ∈ R H × W × C F_i∈R^{H×W×C} Fi∈RH×W×C为backbone中CNN第i层的特征图,s为该层之前的总步长。输入图像的真实Bounding Box定义为 B i {B_i} Bi,其中 B i = ( x 0 ( i ) , y 0 ( i ) , x 1 ( i ) , y 1 ( i ) , c ( i ) ) ∈ R 4 × { 1 , 2... C } B_i=(x^{(i)}_0,y^{(i)}_0,x^{(i)}_1,y^{(i)}_1,c^{(i)})∈\mathbb R^4×\{1,2...C\} Bi=(x0(i),y0(i),x1(i),y1(i),c(i))∈R4×{1,2...C}。 这里 ( x 0 ( i ) , y 0 ( i ) ) (x^{(i)}_0,y^{(i)}_0) (x0(i),y0(i))和 ( x 1 ( i ) , y 1 ( i ) ) (x^{(i)}_1,y^{(i)}_1) (x1(i),y1(i))表示Bounding Box的左上角和右下角的坐标。 c ( i ) c^{(i)} c(i)是Bounding Boxes中目标所属的类。C是类的数量,对于MS-COCO数据集来说是80。
For each location (x,y) on the feature map F i F_i Fi, we can map it back onto the input image as ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) (⌊\frac {s}{2}⌋+xs,⌊\frac {s}{2}⌋+ys) (⌊2s⌋+xs,⌊2s⌋+ys), which is near the center of the receptive field of the location (x,y). Different from anchor-based detectors, which consider the location on the input image as the center of (multiple) anchor boxes and regress the target bounding box with these anchor boxes as references, we directly regress the target bounding box at the location. In other words, our detector directly views locations as training samples instead of anchor boxes in anchor-based detectors, which is the same as FCNs for semantic segmentation.
对于特征图 F i F_i Fi上的每个位置(x,y),FCOS可以将其映射到输入图像上,即 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) (⌊\frac {s}{2}⌋+xs,⌊\frac {s}{2}⌋+ys) (⌊2s⌋+xs,⌊2s⌋+ys),它靠近位置(x,y)的感受野中心。基于Anchor的检测器,将输入图像上的位置视为(多个)Anchor Box的中心,并以这些Anchor Box做为参考对目标Bounding Boxes进行回归。但FOCS直接在位置上回归目标边界框, 换句话说,FCOS直接将位置视为训练样本,而不是基于Anchor的检测器中的Anchor Boxes,这与语义分割的FCN相同。
Specifically, location (x,y) is considered as a positive sample if it falls into any ground-truth box and the class label c ∗ c^∗ c∗ of the location is the class label of the ground-truth box. Otherwise it is a negative sample and c ∗ = 0 c^∗=0 c∗=0 (background class). Besides the label for classification, we also have a 4D real vector t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) t^∗=(l^∗,t^∗,r^∗,b^∗) t∗=(l∗,t∗,r∗,b∗) being the regression targets for the location. Here l ∗ , t ∗ , r ∗ l^∗,t^∗,r^∗ l∗,t∗,r∗ and b ∗ b^∗ b∗ are the distances from the location to the four sides of the bounding box, as shown in Fig. 1 (left). If a location falls into multiple bounding boxes, it is considered as an ambiguous sample. We simply choose the bounding box with minimal area as its regression target. In the next section, we will show that with multi-level prediction, the number of ambiguous samples can be reduced significantly and thus they hardly affect the detection performance. Formally, if location (x,y) is associated to a bounding box Bi, the training regression targets for the location can be formulated as,
l ∗ = x − x 0 ( i ) , t ∗ = y − y 0 ( i ) , r ∗ = x 1 ( i ) − x , b ∗ = y 1 ( i ) − y . (1) l^∗=x-x_0^{(i)}, t^∗=y-y_0^{(i)},\\ r^∗=x_1^{(i)}-x, b^*=y_1^{(i)}-y. \tag {1} l∗=x−x0(i),t∗=y−y0(i),r∗=x1(i)−x,b∗=y1(i)−y.(1)
It is worth noting that FCOS can leverage as many foreground samples as possible to train the regressor. It is different from anchor-based detectors, which only consider the anchor boxes with a highly enough IOU with ground-truth boxes as positive samples. We argue that it may be one of the reasons that FCOS outperforms its anchor-based counterparts.
It is worth noting that FCOS can leverage as many foreground samples as possible to train the regressor. It is different from anchor-based detectors, which only consider the anchor boxes with a highly enough IOU with ground-truth boxes as positive samples. We argue that it may be one of the reasons that FCOS outperforms its anchor-based counterparts.
具体来说,如果位置(x,y)落入任何一个GTBox,并且该位置的类标签
c
∗
c^∗
c∗是GTBox的类标签,则该位置被认为是一个正样本。否则它就是一个负样本,并且
c
∗
=
0
c^∗=0
c∗=0(背景类)。除了用于分类的标签,本文还有一个4D实数向量
t
∗
=
(
l
∗
,
t
∗
,
r
∗
,
b
∗
)
t^∗=(l^∗,t^∗,r^∗,b^∗)
t∗=(l∗,t∗,r∗,b∗)作为该位置的回归目标。这里
l
∗
,
t
∗
,
r
∗
l^∗,t^∗,r^∗
l∗,t∗,r∗和
b
∗
b^∗
b∗是位置到Bounding Boxes四边的距离,如图1(左)所示。如果一个位置落入多个Bounding Boxes,则被认为是一个不确定的样本。本文只需选择面积最小的Bounding Box作为其回归目标。这将在下一节中说明,通过多级预测,不确定样本的数量可以大大减少,因此它们几乎不影响检测性能。形式上,如果位置(x,y)与一个Bounding Box
B
i
B_i
Bi相关,则该位置的训练回归目标可以表述为:
l
∗
=
x
−
x
0
(
i
)
,
t
∗
=
y
−
y
0
(
i
)
,
r
∗
=
x
1
(
i
)
−
x
,
b
∗
=
y
1
(
i
)
−
y
.
(1)
l^∗=x-x_0^{(i)}, t^∗=y-y_0^{(i)},\\ r^∗=x_1^{(i)}-x, b^*=y_1^{(i)}-y. \tag {1}
l∗=x−x0(i),t∗=y−y0(i),r∗=x1(i)−x,b∗=y1(i)−y.(1)
值得注意的是,FCOS可以利用尽可能多的前景样本来训练回归器。它与基于Anchor的检测器不同,后者只考虑将与GTBox有足够高的IoU的Anchor Boxes作为正样本,这可能是FCOS优于基于Anchor的同类模型的原因之一。
Network Outputs
Network Outputs. Corresponding to the training targets, the final layer of our networks predicts an 80D vector p of classification labels and a 4D vector t=(l,t,r,b) bounding box coordinates. Following [Focal loss for dense object detection.], instead of training a multi-class classifier, we train C binary classifiers. Similar to [Focal loss for dense object detection.], we add four convolutional layers after the feature maps of the backbone networks respectively for classification and regression branches. Moreover, since the regression targets are always positive, we employ exp(x) to map any real number to (0,∞) on the top of the regression branch. It is worth noting that FCOS has 9× fewer network output variables than the popular anchor-based detectors with 9 anchor boxes per location.
网络输出。 对应于训练目标,FCOS网络的最后一层预测了一个80维的分类标签向量p和一个4D的向量 t = ( l , t , r , b ) t=(l,t,r,b) t=(l,t,r,b) Bounding Boxes坐标。遵循[Focal loss for dense object detection.]一文中的描述,FCOS并没有训练一个多类分类器,而是训练C类二进制分类器。与[Focal loss for dense object detection.]类似,FCOS在backbone网络的特征图后加入四个卷积层,分别用于分类和回归分支。此外,由于回归目标总是正数,FCOS采用 e x p ( x ) exp(x) exp(x) 将任何实数映射到回归分支顶部的(0,∞)。值得注意的是,FCOS的网络输出变量比流行的基于Anchor的检测器(每个位置有9个Anchor盒)少9倍。
Loss Function
We define our training loss function as follows:
L ( { p x , y } , { t x , y } ) = 1 N p o s ∑ x , y L c l s ( p x , y , c x , y ∗ ) + λ N p o s ∑ x , y 1 { c x , y ∗ > 0 } L r e g ( t x , y , t x , y ∗ ) (2) L(\{p_{x,y}\},\{t_{x,y}\})\\ =\frac {1}{N_{pos}}\sum_{x,y} L_{cls}(p_{x,y},c^*_{x,y}) +\frac {\lambda}{N_{pos}}\sum_{x,y} \mathbb{1}_{\{c^*_{x,y}>0\}}L_{reg}(t_{x,y},t^*_{x,y}) \tag{2} L({px,y},{tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλx,y∑1{cx,y∗>0}Lreg(tx,y,tx,y∗)(2)
where L c l s L_{cls} Lcls is focal loss as in [Focal loss for dense object detection.] and L r e g L_{reg} Lreg is the IoU loss as in UnitBox. N p o s N_{pos} Npos denotes the number of positive samples and λ \lambda λ being 1 in this paper is the balance weight for L r e g L_{reg} Lreg. The summation is calculated over all locations on the feature maps F i F_i Fi. 1 { c x , y ∗ > 0 } 1_{\{c^*_{x,y}>0\}} 1{cx,y∗>0} is the indicator function, being 1 if c i ∗ > 0 c^∗_i>0 ci∗>0 and 0 otherwise.
损失函数。 FCOS的训练损失函数如下:
L
(
{
p
x
,
y
}
,
{
t
x
,
y
}
)
=
1
N
p
o
s
∑
x
,
y
L
c
l
s
(
p
x
,
y
,
c
x
,
y
∗
)
+
λ
N
p
o
s
∑
x
,
y
1
{
c
x
,
y
∗
>
0
}
L
r
e
g
(
t
x
,
y
,
t
x
,
y
∗
)
(2)
L(\{p_{x,y}\},\{t_{x,y}\})\\ =\frac {1}{N_{pos}}\sum_{x,y} L_{cls}(p_{x,y},c^*_{x,y}) +\frac {\lambda}{N_{pos}}\sum_{x,y} \mathbb{1}_{\{c^*_{x,y}>0\}}L_{reg}(t_{x,y},t^*_{x,y}) \tag{2}
L({px,y},{tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλx,y∑1{cx,y∗>0}Lreg(tx,y,tx,y∗)(2)
其中
L
c
l
s
L_{cls}
Lcls是[Focal loss for dense object detection.]中的焦点损失,
L
r
e
g
L_{reg}
Lreg是UnitBox中的IoU损失。
N
p
o
s
N_{pos}
Npos表示正样本的数量,本文中
λ
\lambda
λ 为1,是
L
r
e
g
L_{reg}
Lreg的平衡权重。求和是对特征图
F
i
F_i
Fi上的所有位置进行计算的。
1
{
c
x
,
y
∗
>
0
}
1_{\{c^*_{x,y}>0\}}
1{cx,y∗>0}是指标函数,如果
c
i
∗
>
0
c^∗_i>0
ci∗>0则为1,否则为0。
Inference
Inference. The inference of FCOS is straightforward. Given an input images, we forward it through the network and obtain the classification scores p x , y p_{x,y} px,y and the regression prediction t x , y t_{x,y} tx,y for each location on the feature maps F i F_i Fi. Following [15], we choose the location with p x , y > 0.05 p_{x,y}>0.05 px,y>0.05 as positive samples and invert Eq. (1) to obtain the predicted bounding boxes.
推理。 FCOS的推理是简单明了的。给定一个输入图像,FCOS通过网络进行转发,获得分类分数 p x , y p_{x,y} px,y和特征图 F i F_i Fi上每个位置的回归预测值 t x , y t_{x,y} tx,y。遵循[Focal loss for dense object detection.],FCOS选择 p x , y > 0.05 p_{x,y}>0.05 px,y>0.05的位置作为正样本,并反转公式(1)以获得预测的Bounding Box。
3.2 Multi-level Prediction with FPN for FCOS
Here we show that how two possible issues of the proposed FCOS can be resolved with multi-level prediction with FPN.
- The large stride (e.g., 16×) of the final feature maps in a CNN can result in a relatively low best possible recall (BPR). For anchor based detectors, low recall rates due to the large stride can be compensated to some extent by lowering the required IOU scores for positive anchor boxes. For FCOS, at the first glance one may think that the BPR can be much lower than anchor-based detectors because it is impossible to recall an object which no location on the final feature maps encodes due to a large stride. Here, we empirically show that even with a large stride, FCN-based FCOS is still able to produce a good BPR, and it can even better than the BPR of the anchor-based detector RetinaNet in the official implementation Detectron (refer to Table 1). Therefore, the BPR is actually not a problem of FCOS. Moreover, with multi-level FPN prediction , the BPR can be improved further to match the best BPR the anchor-based RetinaNet can achieve.
- Overlaps in ground-truth boxes can cause intractable ambiguity , i.e., which bounding box should a location in the overlap regress? This ambiguity results in degraded performance of FCN-based detectors. In this work, we show that the ambiguity can be greatly resolved with multi-level prediction, and the FCN-based detector can obtain on par, sometimes even better, performance compared with anchor-based ones.
本文展示了如何用FPN的多级预测来解决FCOS的两个可能的问题。
1)CNN中最终特征图的大步长(如16倍)会导致相对较低的最佳可能召回率(BPR)。对于基于Anchor的检测器来说,由于大步长导致的低召回率可以通过降低正Anchor Boxes所需的IOU分数在一定程度上得到补偿。对于FCOS,乍一看,人们可能会认为BPR会比基于Anchor的检测器低得多,因为步长比较大,不可能召回最终特征图上没有位置编码的目标。本文经过实验表明,即使步幅很大,基于FCN的FCOS仍然能够产生一个很好的BPR,甚至比官方实现Detectron中基于Anchor的检测器RetinaNet的BPR更好(参考表1)。因此,BPR实际上不是FCOS的问题。此外,通过多级FPN预测,BPR可以进一步提高,以匹配基于Anchor的RetinaNet可以达到的最佳BPR。
2)GTBox的重叠会导致难以解决的不确定性,即重叠处的位置应该回归哪个Bounding Box?这种不确定性导致了基于FCN的检测器的性能下降。在这项工作中,本文表明这种不确定性可以通过多级预测得到极大的解决,并且基于FCN的检测器可以获得与基于anchor的检测器相同的性能,有时甚至更好。
Following FPN, we detect different sizes of objects on different levels of feature maps. Specifically, we make use of five levels of feature maps defined as {P3, P4, P5, P6, P7}. P3, P4 and P5 are produced by the backbone CNNs’ feature maps C3, C4 and C5 followed by a 1 × 1 convolutional layer with the top-down connections in [14], as shown in Fig. 2. P6 and P7 are produced by applying one convolutional layer with the stride being 2 on P5 and P6, respectively. As a result, the feature levels P3, P4, P5, P6 and P7 have strides 8, 16, 32, 64 and 128, respectively.
遵循FPN,FCOS在不同级别的特征图上检测不同大小的目标。具体来说,FCOS利用了五级特征图,定义为 P 3 , P 4 , P 5 , P 6 , P 7 {P3, P4, P5, P6, P7} P3,P4,P5,P6,P7。如图2所示,P3、P4和P5是由主干CNN的特征图C3、C4和C5以及1×1卷积层自上而下的连接所产生。P6和P7是通过在P5和P6上分别应用一个步长为2的卷积层而产生。因此,特征层P3、P4、P5、P6和P7的步长分别为8、16、32、64和128。
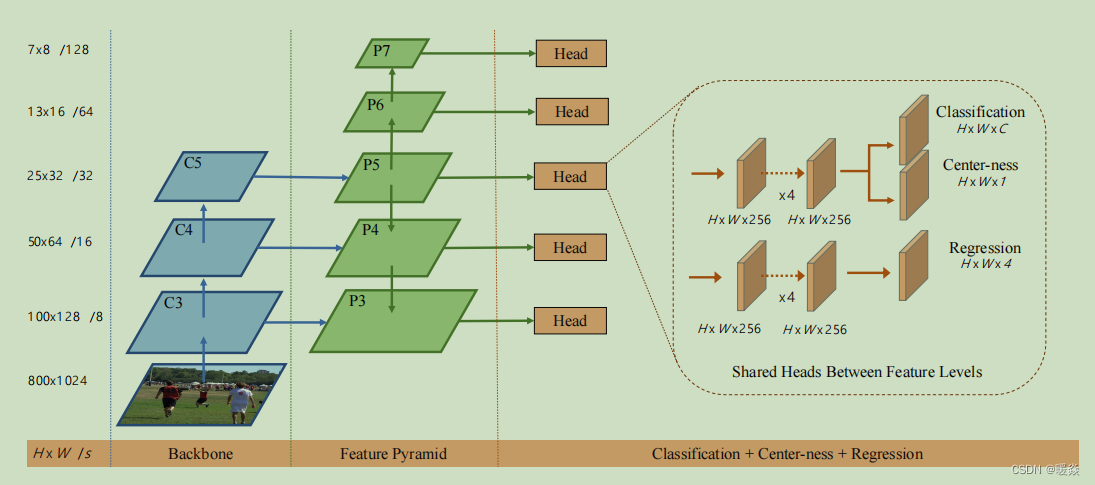
图2
Unlike anchor-based detectors, which assign anchor boxes with different sizes to different feature levels, we directly limit the range of bounding box regression for each level. More specifically, wefirstly compute the regression targets l ∗ , t ∗ , r ∗ l^∗,t^∗,r^∗ l∗,t∗,r∗ and b ∗ b^∗ b∗ for each location on all feature levels. Next, if a location satisfies m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) > m i max(l^∗,t^∗,r^∗,b^∗)>m_i max(l∗,t∗,r∗,b∗)>mi or m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) < m i − 1 max(l^∗,t^∗,r^∗,b^∗)<m_{i-1} max(l∗,t∗,r∗,b∗)<mi−1, it is set as a negative sample and is thus not required to regress a bounding box anymore. Here m i m_i mi is the maximum distance that feature level i i i needs to regress. In this work, m 2 , m 3 , m 4 , m 5 , m 6 m_2,m_3,m_4,m_5,m_6 m2,m3,m4,m5,m6 and m 7 m_7 m7 are set as 0, 64, 128, 256, 512 and∞, respectively. Since objects with different sizes are assigned to different feature levels and most overlapping happens between objects with considerably different sizes. If a location, even with multi-level prediction used, is still assigned to more than one ground-truth boxes, we simply choose the groundtruth box with minimal area as its target. As shown in our experiments, the multi-level prediction can largely alleviate the aforementioned ambiguity and improve the FCN-based detector to the same level of anchor-based ones.
基于Anchor的检测器中,不同层次的特征图指定不同大小的anchor boxes,不同的是,FCOS直接限制了每个层次的Bounding Box的回归范围。更具体地说,FCOS首先计算所有特征层上每个位置的回归目标 l ∗ , t ∗ , r ∗ l^∗,t^∗,r^∗ l∗,t∗,r∗ 和 b ∗ b^∗ b∗。接下来,如果一个位置满足 m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) > m i max(l^∗,t^∗,r^∗,b^∗)>m_i max(l∗,t∗,r∗,b∗)>mi 或者 m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) < m i − 1 max(l^∗,t^∗,r^∗,b^∗)<m_{i-1} max(l∗,t∗,r∗,b∗)<mi−1,它就被设定为负样本,不需要再回归一个Bounding Box。这里 m i m_i mi是特征层 i i i需要回归的最大距离。在这项工作中, m 2 , m 3 , m 4 , m 5 , m 6 m_2,m_3,m_4,m_5,m_6 m2,m3,m4,m5,m6 和 m 7 m_7 m7分别被设置为0、64、128、256、512和∞。由于不同大小的目标被分配到不同的特征层,而且大部分重叠发生在大小差异很大的目标之间。如果一个位置,即使使用了多级预测,仍然被分配到一个以上的GTBox上,FCOS只选择面积最小的GTBox作为其目标。正如本文的实验所显示的,多级预测可以在很大程度上缓解上述的模糊性,并将基于FCN的检测器提高到与基于Anchor的检测器相同的水平。
Finally, following [FPN, Focal Loss], we share the heads between different feature levels, not only making the detector parameter-efficient but also improving the detection performance. However, we observe that different feature levels are required to regress different size range, and therefore it is not reasonable to make use of identical heads for different feature levels. As a result, instead of using the standard exp(x), we make use of exp(six) with a trainable scalar si to automatically adjust the base of the exponential function for feature level Pi, which slightly improves the detection performance.
最后,遵循 [FPN, Focal Loss],FCOS在不同的特征层之间共享检测头,不仅使检测器的参数有效,而且还提高了检测性能。然而,不同的特征级别需要回归不同的大小范围,因此,对不同的特征级别使用相同的头是不合理的。因此,本文没有使用标准的 e x p ( x ) exp(x) exp(x),而是利用 e x p ( s i x ) exp(s_ix) exp(six)与一个可训练的标量 s i s_i si来自动调整特征级别 P i P_i Pi的指数函数的基数,这稍微提高了检测性能。
3.3 Center-ness for FCOS
After using multi-level prediction in FCOS, there is still a performance gap between FCOS and anchor-based detectors. We observed that it is due to a lot of low-quality predicted bounding boxes produced by locations far away from the center of an object.
在FCOS中使用多级预测后,FCOS和基于Anchor的检测器之间仍然存在性能差距,这是由于大量由远离目标中心的位置产生的低质量的预测Bounding Box造成的。
We propose a simple yet effective strategy to suppress these low-quality detected bounding boxes without introducing any hyper-parameters. Specifically, we add a singlelayer branch, in parallel with the classification branch (as shown in Fig. 2) to predict the“center-ness” of a location. The center-ness depicts the normalized distance from the location to the center of the object that the location is responsible for, as shown Fig. 7. Given the regression targets l ∗ , t ∗ , r ∗ l^∗,t^∗,r^∗ l∗,t∗,r∗ and b ∗ b^∗ b∗ for a location, the center-ness target is defined as,
c e n t e r n e s s ∗ = m i n ( l ∗ , r ∗ ) m a x ( l ∗ , r ∗ ) × m i n ( t ∗ , b ∗ ) m a x ( t ∗ , b ∗ ) (3) centerness^*=\sqrt{\frac {min(l^*,r^*)}{max(l^*,r^*)} \times \frac {min(t^*,b^*)}{max(t^*,b^*)}} \tag{3} centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)(3)
We employ sqrt here to slow down the decay of the centerness. The center-ness ranges from 0 to 1 and is thus trained with binary cross entropy (BCE) loss. The loss is added to the loss function Eq. (2). When testing, thefinal score (used for ranking the detected bounding boxes) is computed by multiplying the predicted center-ness with the corresponding classification score. Thus the center-ness can downweight the scores of bounding boxes far from the center of an object. As a result, with high probability, these lowquality bounding boxes might befiltered out by thefinal non-maximum suppression (NMS) process, improving the detection performance remarkably.
本文提出了一个简单而有效的策略,在不引入任何超参数的情况下抑制这些低质量的检测Bounding Boxes。具体来说,FCOS在分类分支的基础上增加了一个单层分支(如图2所示)来预测一个位置的 “center-ness”。如图7所示,中心度描述了从一个位置到该位置所负责的目标中心的归一化距离。一个位置的回归目标
l
∗
,
t
∗
,
r
∗
l^∗,t^∗,r^∗
l∗,t∗,r∗ 和
b
∗
b^∗
b∗,中心度目标被定义为:
c
e
n
t
e
r
n
e
s
s
∗
=
m
i
n
(
l
∗
,
r
∗
)
m
a
x
(
l
∗
,
r
∗
)
×
m
i
n
(
t
∗
,
b
∗
)
m
a
x
(
t
∗
,
b
∗
)
(3)
centerness^*=\sqrt{\frac {min(l^*,r^*)}{max(l^*,r^*)} \times \frac {min(t^*,b^*)}{max(t^*,b^*)}} \tag{3}
centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)(3)
FCOS在这里采用sqrt来减缓center-ness的衰减。center-ness的范围从0到1,因此用二元交叉熵(BCE)损失进行训练。该损失被添加到损失函数公式(2)中。测试时,最终得分(用于对检测到的Bounding Box进行排名)是通过预测的center-ness与相应的分类得分相乘来计算的。因此,中心度可以降低远离目标中心的Bounding Box的分数。因此,这些低质量的Bounding Box很有可能被最终的非最大抑制(NMS)过程过滤掉,从而极大地提高检测性能。
An alternative of the center-ness is to make use of only the central portion of ground-truth bounding box as positive samples with the price of one extra hyper-parameter, as shown in works. After our submission, it has been shown in [FCOS_PLUS] that the combination of both methods can achieve a much better performance. The experimental results can be found in Table 3.
center-ness的一个替代方法是只利用真实Bounding Box的中心部分作为正样本,代价是多出一个超参数。在本文提交之后,[FCOS_PLUS]的实验部分已经表明,两种方法的结合可以达到更好的性能。实验结果可以在表3中找到。
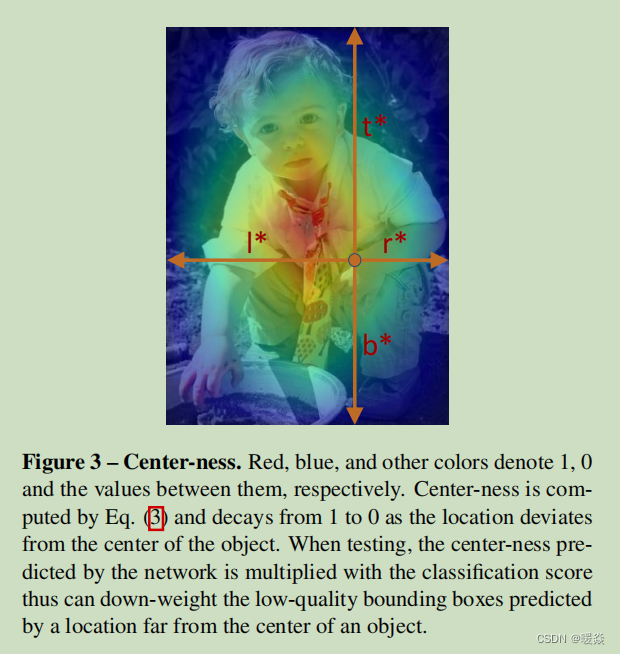
图3
4 Experiments
Our experiments are conducted on the large-scale detection benchmark COCO [16]. Following the common practice [15, 14, 24], we use the COCO trainval35k split (115K images) for training and minival split (5K images) as validation for our ablation study. We report our main results on the test dev split (20K images) by uploading our detection results to the evaluation server.
我们的实验是在大规模检测基准COCO [16]上进行的。按照常见的[15,14,24]实践,我们使用COCO trainval35K 分割(115K图像)进行训练和 minival 分割(5K图像)作为我们的消融研究的验证。通过将检测结果上传到评估服务器,我们报告了关于test dev 分割(20K图像)的主要结果。
MS COCO:
原始的COCO的检测任务共含有80个类,在2014年发布的数据规模分train/val/test分别为80k/40k/40k。为了增加训练集,特将val中分出35k给train。
COCO trainval35k:使用train和35k的val子集作为训练集,剩余的val作为测试集(minival)。MS COCO 2017中,trainval35k共包含118287张图片。
Training Details. Unless specified, ResNet-50 [8] is used as our backbone networks and the same hyper-parameters with RetinaNet [15] are used. Specifically, our network is trained with stochastic gradient descent (SGD) for 90K iterations with the initial learning rate being 0.01 and a minibatch of 16 images. The learning rate is reduced by a factor of 10 at iteration 60K and 80K, respectively. Weight decay and momentum are set as 0.0001 and 0.9, respectively.
We initialize our backbone networks with the weights pretrained on ImageNet [4]. For the newly added layers, we initialize them as in [15]. Unless specified, the input images are resized to have their shorter side being 800 and their longer side less or equal to 1333.
训练细节。除非特别说明,否则使用ResNet-50 [8]作为我们的主干网络,并使用与RetinaNet[15]相同的超参数。具体来说,我们的网络采用随机梯度下降(SGD)进行90K迭代训练,初始学习率为0.01和小批量16张图像。在迭代60K和80K时,学习率分别降低10倍。权值衰减和动量分别设为0.0001和0.9。我们使用在ImageNet [4]上预先训练的权值来初始化我们的主干网络。对于新添加的图层,我们在[15]中初始化它们。除非指定,否则输入图像将调整大小,使其较短的边为800,而较长的边小于或等于1333。
Inference Details. We firstly forward the input image through the network and obtain the predicted bounding boxes with a predicted class. Unless specified, the following post-processing is exactly the same with RetinaNet [15] and we directly make use of the same post-processing hyper-parameters of RetinaNet. We use the same sizes of input images as in training. We hypothesize that the performance of our detector may be improved further if we carefully tune the hyper-parameters.
推理细节。首先将输入图像通过网络进行转发,得到具有预测类的预测边界框。除非有特别说明,否则下面的后处理与RetinaNet [15]完全相同,直接使用RetinaNet 相同的后处理超参数。使用与训练中相同大小的输入图像。如果假设我们仔细调整超参数,检测器的性能可能会进一步提高。
4.1 Ablation Study
4.1.1 Multi-level Prediction with FPN
As mentioned before, the major concerns of an FCN-based detector are low recall rates and ambiguous samples resulted from overlapping in ground-truth bounding boxes. In the section, we show that both issues can be largely resolved with multi-level prediction.
如前所述,基于FCN的检测器的主要问题是低召回率和由于真实边界框的重叠而导致的不确定样本。在本一节中,我们展示了这两个问题可以通过多层次预测很大程度上解决。
Best Possible Recalls. The first concern about the FCN-based detector is that it might not provide a good best possible recall (BPR). In the section, we show that the concern is not necessary. Here BPR is defined as the ratio of the number of ground-truth boxes a detector can recall at the most divided by all ground-truth boxes. A ground-truth box is considered being recalled if the box is assigned to at least one sample (i.e., a location in FCOS or an anchor box in anchor-based detectors) during training. As shown in Table 1, only with feature level P4 with stride being 16 (i.e., no FPN), FCOS can already obtain a BPR of 95.55%. The BPR is much higher than the BPR of 90.92% of the anchor-based detector RetinaNet in the official implementation Detectron, where only the low-quality matches with IOU ≥ 0.4 are used. With the help of FPN, FCOS can achieve a BPR of 98.40%, which is very close to the best BPR that the anchor-based detector can achieve by using all low-quality matches. Due to the fact that the best recall of current detectors are much lower than 90%, the small BPR
gap (less than 1%) between FCOS and the anchor-based detector will not actually affect the performance of detector. It is also confirmed in Table 3, where FCOS achieves even better AR than its anchor-based counterparts under the same training and testing settings. Therefore, the concern about low BPR may not be necessary.
关于基于FCN的检测器的第一个担忧是,它可能不能提供良好的最佳召回率(BPR)。在本一节中,我们证明这种担忧是不必要的。在这里,Best Possible Recall,BPR被定义为一个检测器最多能召回到的GTBoxes的数量除以所有GTBoxes的比率。 一个GTBox被认为是被召回的条件:在训练中如果该GTBox被指定给至少一个样本(即(i.e.),FCOS中的一个位置或基于anchor的检测器中的一个anchor box)。像表1所展示的,仅仅使用步长为16的特征级别 P 4 P_4 P4,FCOS就已经可以得到95.55%BPR,远远高于基于anchor的RetinaNet90.92%的BPR,RetinaNet中只使用了IoU≥0.4的低质量匹配。如果使用FPN,FCOS可以得到98.4%BPR,这已经非常接近基于anchor检测器使用所有低质量匹配可以获得的最佳BPR。由于当前检测器的最佳召回率远低于90%,FCOS与基于anchor检测器之间的BPR差别较小(小于1%)实际上不会影响检测器的性能。表3也证实了这一点,在相同的训练和测试设置下,FCOS比基于anchor的同行实现了更好的AR。因此,不需要担心FCOS低BPR。

表1
Ambiguous Samples. Another concern about the FCN-based detector is that it may have a large number of ambiguous samples due to the overlapping in ground-truth bounding boxes, as shown in Fig. 1 (right). In Table 2, we show the ratios of the ambiguous samples to all positive samples on minival split. As shown in the table, there are indeed a large amount of ambiguous samples (23.16%) if FPN is not used and only feature level P4 is used. However, with FPN, the ratio can be significantly reduced to only 7.14% since most of overlapped objects are assigned to different feature levels. Moreover, we argue that the ambiguous samples resulted from overlapping between objects of the same category do not matter. For instance, if object A and B with the same class have overlap, no matter which object the locations in the overlap predict, the prediction is correct because it is always matched with the same category. The missed object can be predicted by the locations only belonging to it.Therefore, we only count the ambiguous samples in overlap between bounding boxes with different categories. As shown in Table 2, the multi-level prediction reduces the ratio of ambiguous samples from 17.84% to 3.75%. In order to further show that the overlapping in ground truth boxes is not a problem of our FCN-based FCOS, we count that when inferring how many detected bounding boxes come from the ambiguous locations. We found that only 2.3% detected bounding boxes are produced by the ambiguous locations.By further only considering the overlap between different categories, the ratio is reduced to 1.5%. Note that it does not imply that there are 1.5% locations where FCOS cannot work. As mentioned before, these locations are associated with the ground-truth boxes with minimal area. Therefore,these locations only take the risk of missing some larger objects. As shown in the following experiments, they do not make our FCOS inferior to anchor-based detectors.
不确定样本。基于FCN的检测器的另一个问题是,由于GTBoxes的重叠,它可能有大量的不确定样本,如图1(右)所示。在表2中,我们展示了不确定样本与所有正样本的比例。如表中所示,如果不使用FPN,只使用特征级P4,则确实存在大量的不确定样本(23.16%)。
然而,使用FPN,由于大多数重叠的对象被分配到不同的特征级别,该比例可以显著降低到仅7.14%。此外,我们认为,由于同一类别的对象之间的重叠而导致的模糊样本并不重要。例如,如果具有相同类的目标A和B有重叠,无论重叠的对象预测哪个位置,预测都是正确的,因为它总是与相同的类别匹配。被遗漏的对象只能通过属于它的位置来预测。因此,我们只计算具有不同类别的边界框之间重叠的不确定样本。如表2所示,多层次预测将不确定样本的比例从17.84%降低到3.75%。为了进一步证明基于FCN的FCOS不受GTBoxes重叠的影响,我们在推断有多少检测到的box是来自不确定位置。我们发现,只有2.3%的检测到的box是由不确定位置产生的。进一步考虑不同类别之间的重叠,比例降低到1.5%。请注意,这并不意味着有1.5%的位置的FCOS不能工作。如前所述,这些位置与面积最小的GTBox相关联。因此,这些位置只冒着丢失一些较大物体的风险。如下面的实验所示,它们并没有使我们的FCOS不如基于anchor的检测器。

表2
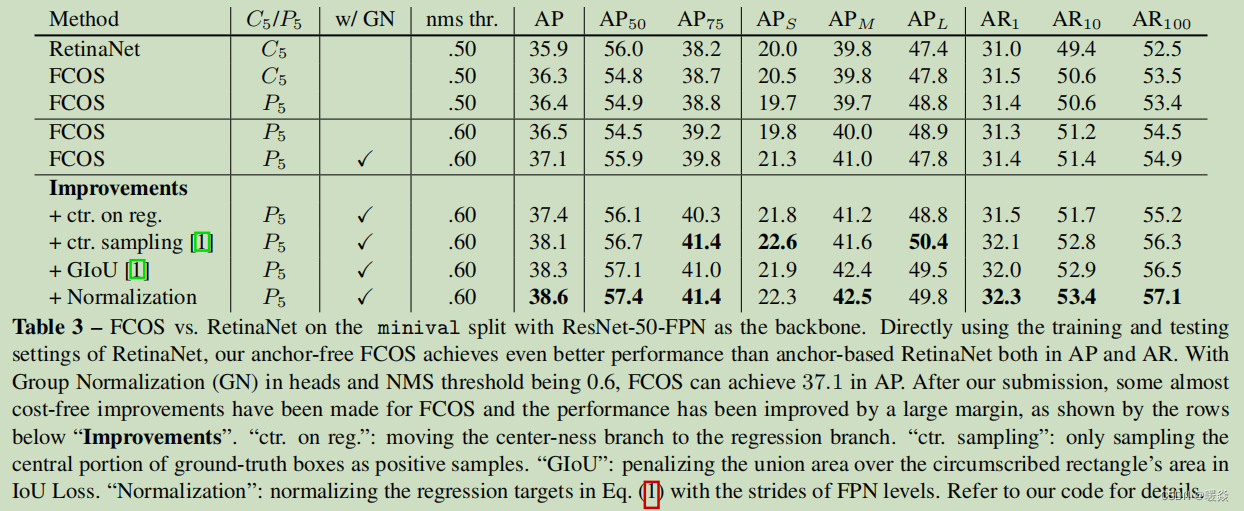
表3
4.1.2 With or Without Center-ness
As mentioned before, we propose “center-ness” to suppress the low-quality detected bounding boxes produced by the locations far from the center of an object. As shown in
Table 4, the center-ness branch can boost AP from 33.5% to 37.1%, making anchor-free FCOS outperform anchor-based RetinaNet (35.9%). Note that anchor-based RetinaNet employs two IoU thresholds to label anchor boxes as positive/negative samples, which can also help to suppress the low-quality predictions. The proposed center-ness can eliminate the two hyper-parameters. However, after our initial submission, it has shown that using both center-ness and the thresholds can result in a better performance, as shown by the row “+ ctr. sampling” in Table 3. One may note that center-ness can also be computed with the predicted regression vector without introducing the extra center-ness branch. However, as shown in Table 4, the center-ness computed from the regression vector cannot improve the performance and thus the separate center-ness is necessary.
如前所述,我们提出“中心性”来抑制由远离物体中心的位置产生的低质量检测边界盒。如表4所示,中心向分支可以将AP从33.5%提高到37.1%,使无anchor的FCOS优于基于anchor的RetinaNet (35.9%)。请注意,基于anchor的RetinaNet使用两个IoU阈值将anchor-box标记为正/负样本,这也有助于抑制低质量的预测。我们提出的中心度可以消除这两个超参数。然而,在我们最初的提交之后,已经表明,同时使用中心性和阈值可以获得更好的性能,如“+ ctr. sampling”行见表3。我们可以注意到,中心度也可以用预测的回归向量来计算,而不引入额外的中心度分支。但是,如表4所示,从回归向量计算出的中心度并不能提高性能,因此需要进行单独的中心度。
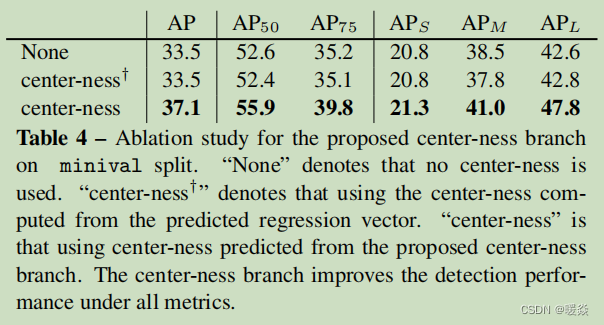
表4
4.1.3 FCOS vs. Anchor-based Detectors
The aforementioned FCOS has two minor differences from the standard RetinaNet. 1) We use Group Normalization (GN) [29] in the newly added convolutional layers except for the last prediction layers, which makes our training more stable. 2) We use P5 to produce the P6 and P7 instead of C5 in the standard RetinaNet. We observe that using P5 can improve the performance slightly.
To show that our FCOS can serve as an simple and strong alternative of anchor-based detectors, and for a fair comparison, we remove GN (the gradients are clipped to prevent them from exploding) and use C5 in our detector. As shown in Table 3, with exactly the same settings, our FCOS still compares favorably with the anchor-based detector (36.3% vs 35.9%). Moreover, it is worth to note that we directly use all hyper-parameters (e.g., learning rate, the NMS threshold and etc.) from RetinaNet, which have been optimized for the anchor-based detector. We argue that the performance of FCOS can be improved further if the hyper-parameters are tuned for it.
It is worth noting that with some almost cost-free improvements, as shown in Table 3, the performance of our anchor-free detector can be improved by a large margin. Given the superior performance and the merits of the anchor-free detector (e.g., much simpler and fewer hyperparameters than anchor-based detectors), we encourage the community to rethink the necessity of anchor boxes in object detection.
上述的FCOS与标准的RetinaNet有两个小的区别。1)除了最后的预测层外,我们在新添加的卷积层中使用组归一化(GN)[29],这使得我们的训练更加稳定。2)我们使用P5来生成P6和P7,而不是C5。我们观察到,使用P5可以略微提高性能。
为了证明我们的FCOS可以作为anchor检测器的一个简单而强大的替代方案,并且为了进行公平的比较,我们去除GN(被剪辑的梯度以防止它们爆炸),并在我们的探测器中使用C5。如表3所示,在完全相同的设置下,我们的FCOS仍然优于基于anchor的检测器(36.3% vs 35.9%)。此外,值得注意的是,我们直接使用了RetinaNet所有的超参数(如学习率、NMS阈值等)。它已经为基于anchor检测器进行了优化。我们认为,如果对超参数进行调整,FCOS的性能可以进一步提高。
值得注意的是,通过一些几乎免费的改进,如表3所示,我们的无anchor检测器的性能可以得到很大幅度的提高。考虑到无anchor检测器的优越性能和优点(例如,比基于anchor的检测器更简单和更少的超参数),我们鼓励社区重新考虑anchor boxes在目标检测中的必要性。
4.2 Comparison with State-of-the-art Detectors
We compare FCOS with other state-of-the-art object detectors on test−dev split of MS-COCO benchmark. For these experiments, we randomly scale the shorter side of images in the range from 640 to 800 during the training and double the number of iterations to 180K (with the learning rate change points scaled proportionally). Other settings are exactly the same as the model with AP 37.1% in Table 3. As shown in Table 5, with ResNet-101-FPN, our FCOS outperforms the RetinaNet with the same backbone ResNet-101-FPN by 2.4% in AP. To our knowledge, it is the first time that an anchor-free detector, without any bells and whistles outperforms anchor-based detectors by a large margin. FCOS also outperforms other classical two-stage anchor-based detectors such as Faster R-CNN by a large margin. With ResNeXt-64x4d-101-FPN [30] as the backbone, FCOS achieves 43.2% in AP. It outperforms the recent state-of-the-art anchor-free detector CornerNet [13] by a large margin while being much simpler. Note that CornerNet requires to group corners with embedding vectors, which needs special design for the detector. Thus, we argue that FCOS is more likely to serve as a strong and simple alternative to current mainstream anchor-based detectors. Moreover, FCOS with the improvements in Table 3 achieves 44.7% in AP with single-model and single scale testing, which surpasses previous detectors by a large margin.
我们比较了FCOS与其他最先进的目标检测器在test−dev分割的MS-COCO基准测试。在这些实验中,我们在训练过程中随机改变图像短边到从640~800的范围,并将迭代次数翻倍到180K(学习率变化点按比例缩放)。其他设置与表3中AP值为37.1%的模型完全相同。如表5所示,在ResNet-101-FPN中,我们的FCOS在AP中比具有相同主干的ResNet-101-FPN的RetinaNet好2.4%。据我们所知,这是第一次,一个没有任何附加条件的无anchor检测器的性能大大优于基于anchor的检测器。FCOS的性能也大大优于其他经典的基于anchor的两级检测器,如Faster R-CNN。以ResNeXt-64x4d-101-FPN [30]为骨干,FCOS在AP中达到43.2%。它的性能比最近最先进的无anchor检测器[13]更好,同时简单得多。请注意,CornerNet 需要将嵌入向量的corners 进行分组,这需要对检测器进行特殊的设计。因此,我们认为FCOS更有可能作为当前主流的基于anchor检测器的一个强大和简单的替代品。此外,在表3中改进的FCOS在单模型和单尺度测试的AP中达到了44.7%,大大超过了以往的检测器。
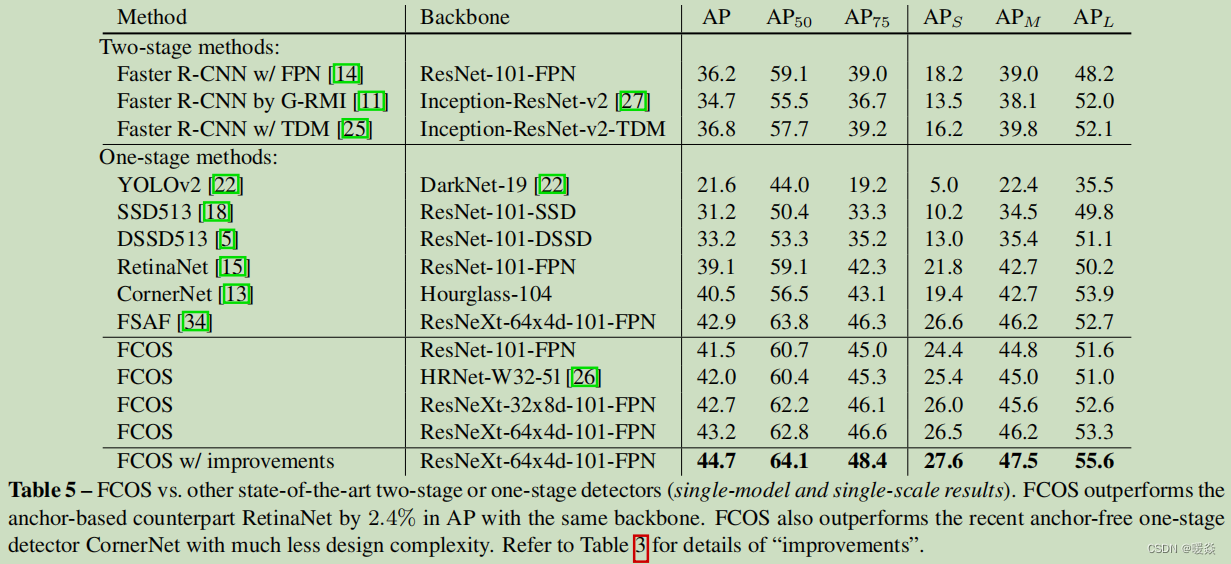
表5
5 Extensions on Region Proposal Networks
So far we have shown that in a one-stage detector, our FCOS can achieve even better performance than anchor-based counterparts. Intuitively, FCOS should be also able to replace the anchor boxes in Region Proposal Networks (RPNs) with FPN [14] in the two-stage detector Faster RCNN. Here, we confirm that by experiments.
Compared to RPNs with FPN [14], we replace anchor boxes with the method in FCOS. Moreover, we add GN into the layers in FPN heads, which can make our training more stable. All other settings are exactly the same with RPNs with FPN in the official code [7]. As shown in Table 6, even without the proposed center-ness branch, our FCOS already improves both AR100 and AR1k significantly. With the proposed center-ness branch, FCOS further boosts AR100 and AR1k respectively to 52.8% and 60.3%, which are 18% relative improvement for AR100 and 3.4% absolute improvement for AR1k over the RPNs with FPN.
到目前为止,我们已经证明,在one-stage检测器中,我们的FCOS可以获得比基于anchor的同类探测器更好的性能。直观地说,FCOS可以替换使用FPN的two-stage检测器Faster RCNN中RPN中anchor boxes。在这里,我们通过实验证实了这一点。
与使用FPN [14]的RPNs相比,我们用FCOS中的方法替换了anchor boxes。此外,我们在FPN头的各层中添加了Group Normalization,这可以使我们的训练更加稳定。其他所有设置与使用FPN的RPNs官方代码[7]完全相同。如表6所示,即使没有提出的中心性分支,我们的FCOS已经显著改善了AR100和AR1k。通过提出的中心性分支,FCOS进一步将AR100和AR1k分别提高到52.8%和60.3%,与FPN相比,AR100的相对提高18%,AR1k的绝对提高3.4%。

表6
6. Conclusion
We have proposed an anchor-free and proposal-free one-stage detector FCOS. As shown in experiments, FCOS compares favourably against the popular anchor-based one-stage detectors, including RetinaNet, YOLO and SSD, but with much less design complexity. FCOS completely avoids all computation and hyper-parameters related to anchor boxes and solves the object detection in a per-pixel prediction fashion, similar to other dense prediction tasks such as semantic segmentation. FCOS also achieves state-of-the-art performance among one-stage detectors. We also show that FCOS can be used as RPNs in the two-stage detector
Faster R-CNN and outperforms the its RPNs by a large margin. Given its effectiveness and efficiency, we hope that FCOS can serve as a strong and simple alternative of current mainstream anchor-based detectors. We also believe that FCOS can be extended to solve many other instance-level recognition tasks.
我们提出了一种无anchor和无建议的one-stage检测器FCOS。如实验所示,FCOS优于流行的基于anchor的one-stage检测器,包括RetinaNet、YOLO和SSD,但设计复杂性要小得多。FCOS完全避免了所有与anchor boxes相关的计算和超参数,并以逐像素预测的方式解决了目标检测,类似于其他密集的预测任务,如语义分割。FCOS还在one-stage检测器中取得了最先进的性能。我们还表明,FCOS可以作为two-stage Faster R-CNN 的RPN,并且性能大大优于其RPN。鉴于FCOS的有效性和效率,我们希望FCOS可以作为当前主流基于anchor的一个强大和简单的选择。我们也相信FCOS可以扩展到解决许多其他的实例识别任务。
7 Class-agnostic Precision-recall Curves
In Fig. 4, Fig. 5 and Fig. 6, we present class-agnostic precision-recall curves on split minival at IOU thresholds being 0.50, 0.75 and 0.90, respectively. Table 7 shows APs corresponding to the three curves.
As shown in Table 7, our FCOS achieves better performance than its anchor-based counterpart RetinaNet. Moreover, it worth noting that with a stricter IOU threshold, FCOS enjoys a larger improvement over RetinaNet, which suggests that FCOS has a better bounding box regressor to detect objects more accurately. One of the reasons should be that FCOS has the ability to leverage more foreground samples to train the regressor as mentioned in our main paper.
Finally, as shown in all precision-recall curves, the best recalls of these detectors in the precision-recall curves are much lower than 90%. It further suggests that the small gap
(98.40% vs. 99.23%) of best possible recall (BPR) between FCOS and RetinaNet hardly harms the final detection performance.
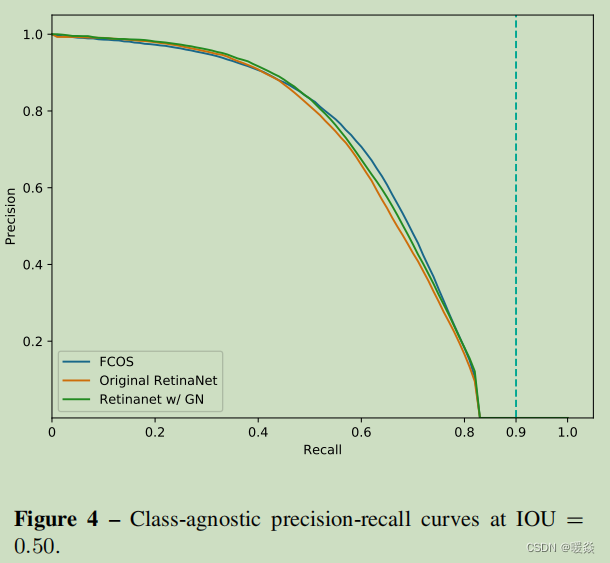
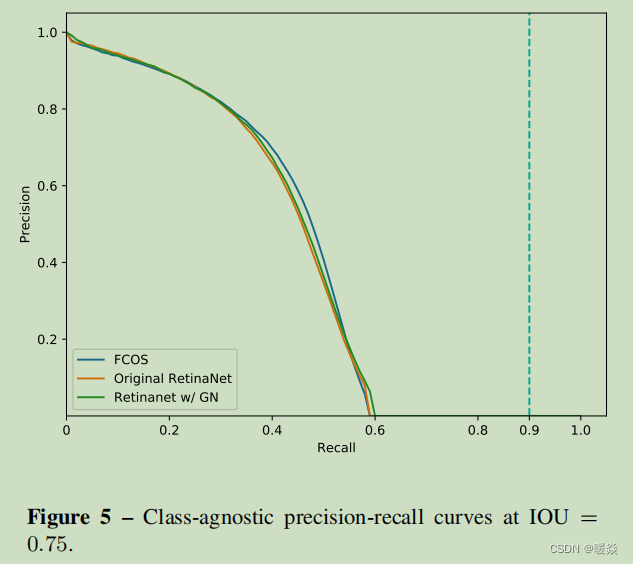
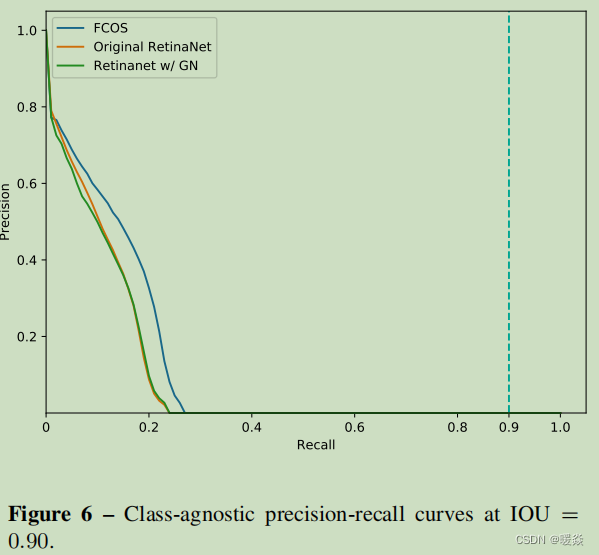
在图4、图5和图6中,我们分别给出了IOU阈值为0.50、0.75和0.90的分割时的类不可知精度-召回曲线。表7显示了这三条曲线对应的AP值。
如表7所示,我们的FCOS比基于anchor的RetinaNet取得了更好的性能。此外,值得注意的是,在更严格的IOU阈值下,FCOS比RetinaNet有了更大的改进,这表明FCOS有更好的边界盒回归器来更准确地检测目标。其中一个原因应该是FCOS有能力利用更多的前景样本来训练我们在主要论文中提到的回归变量。
最后,如所有的精度-召回率曲线所示,这些检测器在精度-召回率曲线中的最佳召回率远低于90%。这进一步表明,FCOS和RetinaNet之间的最佳可能召回率(BPR)的小差距(98.40% vs. 99.23%)几乎不影响最终的检测性能。
8. Visualization for Center-ness
As mentioned in our main paper, by suppressing low-quality detected bounding boxes, the proposed center-ness branch improves the detection performance by a large margin. In this section, we confirm this.
We expect that the center-ness can down-weight the scores of low-quality bounding boxes such that these bounding boxes can be filtered out in following post-processing such as non-maximum suppression (NMS). A detected bounding box is considered as a low-quality one if it has a low IOU score with its corresponding ground-truth bounding box. A bounding box with low IOU but a high confidence score is likely to become a false positive and harm the precision.
In Fig. 7, we consider a detected bounding box as a 2D point (x, y) with x being its score and y being the IOU with its corresponding ground-truth box. As shown in Fig. 7 (left), before applying the center-ness, there are a large number of low-quality bounding boxes but with a high confidence score (i.e., the points under the line y = x). Due to their high scores, these low-quality bounding boxes cannot be eliminated in post-processing and result in lowering the precision of the detector. After multiplying the classification score with the center-ness score, these points are pushed to the left side of the plot (i.e., their scores are reduced), as shown in Fig. 7 (right). As a result, these low-quality bounding boxes are much more likely to be filtered out in post-processing and the final detection performancecan be improved.
正如我们的主要论文所述,通过抑制低质量的检测边界盒,提出的中心性分支很大程度地提高了检测性能。在本节中,我们将确认这一点。
我们期望中心性可以降低低质量边界框的分数,这样这些边界框就可以在后续的后处理中被过滤掉,如非最大抑制(NMS)。如果一个检测到的边界框及其相应的GTBoxes的IOU得分较低,则认为它是一个低质量的边界框。一个低IoU但置信度高的边界框很可能成为假正例并损害精度。
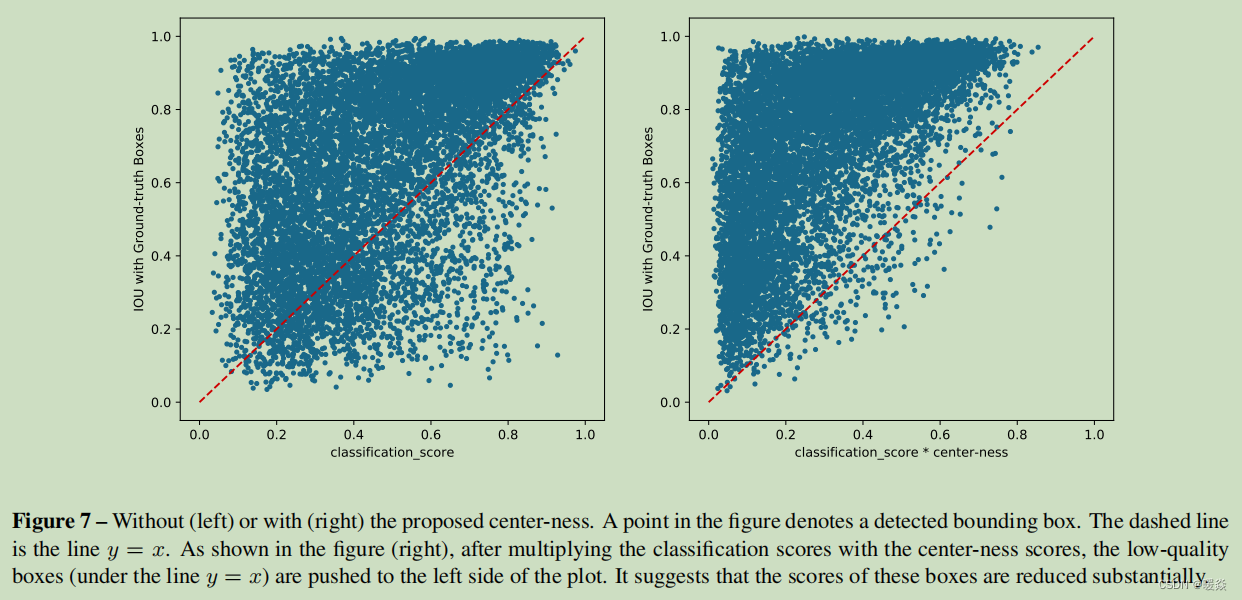
图7
在图7中,我们将一个检测到的边界框视为一个二维点(x,y),x是它的分数,y是它对应的GTBox的IOU。如图7(左)所示,在应用中心度之前,存在大量低质量的边界框,但置信度得分较高(即线y=x下的点)。由于分数较高,这些低质量的边界框在后处理中无法消除,导致探测器的精度降低。将分类得分与中心度得分相乘后,将这些分数推到图的左侧(即减少它们的分数),如图7(右)所示。因此,这些低质量的边界框更有可能在后处理中被过滤掉,最终的检测性能得到提高。
9 Qualitative Results
Some qualitative results are shown in Fig. 8. As shown in the figure, our proposed FCOS can detect a wide range of objects including crowded, occluded, highly overlapped, extremely small and very large objects.
部分定性结果如图8所示。如图所示,我们提出的FCOS可以检测到广泛的物体,包括拥挤、遮挡、高度重叠、极小和非常大的物体。

图8
10 More discussions
Center-ness vs. IoUNet
Center-ness and IoUNet of Jiang et al. “Acquisition of Localization Confidence for Accurate Object Detection” shares a similar purpose (i.e., to suppress low-quality predictions) with different approaches. IoUNet trains a separate network to predict the IoU score between predicted bounding-boxes and ground-truth boxes. Center-ness, as a part of our detector, only has a single layer and is trained jointly with the detector, thus being much simpler. Moreover, “center-ness” does not take as input the predicted bounding-boxes. Instead, it directly accesses the location’s ability to predict high-quality bounding-boxes.
Jiang等人的中心性和经验。“获取精确目标检测的定位置信度”与不同的方法具有相似的目的(即抑制低质量的预测)。IoUNet训练一个单独的网络来预测 预测的边界盒和真实边界框之间的IoU得分。中心度,作为我们的探测器的一部分,只有一个层,并与检测器联合训练,因此要简单得多。此外,“中心性”并不以预测的边界框作为输入。相反,它直接访问该位置预测高质量边界框的能力。
BPR in Section 4.1 and ambiguity analysis
We do not aim to compare “recall by specific IoU” with “recall by pixel within box”. The main purpose of Table 1 is to show that the upper bound of recall of FCOS is very close to the upper bound of recall of anchor-based RetinaNet (98.4% vs. 99.23%). BPR by other IoU thresholds are listed as those are used in the official code of RetinaNet.
Moreover, no evidence shows that the regression targets of FCOS are difficult to learn because they are more spreadout. FCOS in fact yields more accurate bounding-boxes. During training, we deal with the ambiguity at the same FPN level by choosing the ground-truth box with the minimal area. When testing, if two objects A and B with the same class have overlap, no matter which one object the locations in the overlap predict, the prediction is correct and the missed one can be predicted by the locations only belonging to it. In the case that A and B do not belong to the same class, a location in the overlap might predict A’s class but regress B’s bounding-box, which is a mistake. That is why we only count the ambiguity across different classes. Moreover, it appears that this ambiguity does not make FCOS worse than RetinaNet in AP, as shown in Table 8.
我们的目的不是比较“特定IoU召回率”和“框内像素召回率”。表1的主要目的是表明FCOS的召回率上界非常接近anchor-based RetinaNet召回率上界(98.4% vs. 99.23%)。其他IoU阈值的BPR被列为在RetinaNet的官方代码中使用的BPR。此外,没有证据表明FCOS的回归目标很难学习,因为它们更容易扩展。FCOS实际上可以产生了更精确的边界框。
在训练过程中,我们通过选择具有最小面积的GTBox来处理在相同的FPN水平上的不确定性。在测试时,如果两个具有相同类的目标A和B有重叠,无论该重叠位置预测哪种目标,预测是正确的,遗漏的一个可以由只属于它的位置预测。在A和B不属于同一类的情况下,重叠部分中的一个位置可以预测A的类,但会回归B的边界盒,这是一个错误的。这就是为什么我们只计算不同类之间的不确定性。此外,这种歧义似乎并没有使AP中的FCOS比RetinaNet更差,如表8所示。
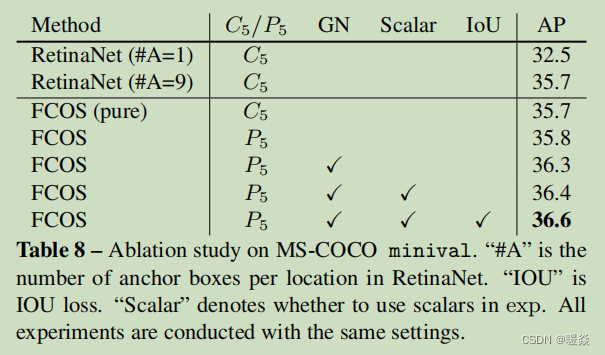
表8
Additional ablation study
As shown in Table 8, a vanilla FCOS performs on par with RetinaNet, being of simpler design and with ∼ 9× less network outputs. Moreover, FCOS works much better than RetinaNet with single anchor. As for the 2% gain on test-dev, besides the performance gain brought by the components in Table 8, we conjecture that different training details (e.g., learning rate schedule) might cause slight differences in performance.
如表8所示,普通FCOS的性能与视网膜网络相当,设计更简单,网络输出更少为∼9×。此外,FCOS比单anchor的RetinaNet工作得要好得多。对于test-dev的2%的增益,除了表8中的组件带来的性能增益外,我们推测不同的训练细节(如学习率计划)可能会导致性能的性能差异。
RetinaNet with Center-ness
Center-ness cannot be directly used in RetinaNet with multiple anchor boxes per location because one location on feature maps has only one center-ness score but different anchor boxes on the same location require different “center-ness” (note that center-ness is also used as “soft” thresholds for positive/negative samples).
For anchor-based RetinaNet, the IoU score between anchor boxes and ground-truth boxes may serve as an alternative of “center-ness”.
中心度不能在每个位置有多个anchor boxes的RetinaNet中直接使用,因为特征地图上的一个位置只有一个中心度得分,但同一位置上的不同anchor box需要不同的“中心度”(注意,中心度也被用作正/负样本的“软”阈值)。
对于anchor-based RetinaNet,anchor boxes 和GTBoxes之间的IoU得分可以作为“中心性”的替代方法。
Positive samples overlap with RetinaNet
We want to highlight that center-ness comes into play only when testing. When training, all locations within ground-truth boxes are marked as positive samples. As a result, FCOS can use more foreground locations to train the regressor and thus yield more accurate bounding-boxes.
我们想强调,只有在测试时才会发挥作用。在训练时,GTBoxes内的所有位置都被标记为正样本。因此,FCOS可以使用更多的前景位置来训练回归器,从而产生更准确的边界框。
Acknowledgments
We would like to thank the author of [1] for the tricks of center sampling and GIoU. We also thank Chaorui Deng for HRNet based FCOS and his suggestion of positioning the center-ness branch with box regression.
确认。我们要感谢[1]的作者对中心采样和GIoU的技巧。我们也感谢邓卓瑞基于HRNet的FCOS,以及他关于用box回归定位中心性分支的建议。
References
[1] https://github.com/yqyao/FCOS_PLUS, 2019.
[2] Lokesh Boominathan, Srinivas SS Kruthiventi, and R Venkatesh Babu. Crowdnet: A deep convolutional network for dense crowd counting. In Proc. ACM Int. Conf. Multimedia, pages 640–644. ACM, 2016.
[3] Yu Chen, Chunhua Shen, Xiu-Shen Wei, Lingqiao Liu, and Jian Yang. Adversarial PoseNet: A structure-aware convolutional network for human pose estimation. In Proc. IEEE Int. Conf. Comp. Vis., 2017.
[4] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 248–255. IEEE, 2009.
[5] Cheng-Yang Fu, Wei Liu, Ananth Ranga, Ambrish Tyagi, and Alexander Berg. DSSD: Deconvolutional single shot detector. arXiv preprint arXiv:1701.06659, 2017.
[6] Ross Girshick. Fast R-CNN. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 1440–1448, 2015.
[7] Ross Girshick, Ilija Radosavovic, Georgia Gkioxari, Piotr Doll´ar, and Kaiming He. Detectron. https://github. com/facebookresearch/detectron, 2018.
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 770–778, 2016.
[9] Tong He, Chunhua Shen, Zhi Tian, Dong Gong, Changming Sun, and Youliang Yan. Knowledge adaptation for efficient semantic segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., June 2019.
[10] Tong He, Zhi Tian, Weilin Huang, Chunhua Shen, Yu Qiao, and Changming Sun. An end-to-end textspotter with explicit
alignment and attention. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 5020–5029, 2018.
[11] Jonathan Huang, Vivek Rathod, Chen Sun, Menglong Zhu, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 7310–7311, 2017.
[12] Lichao Huang, Yi Yang, Yafeng Deng, and Yinan Yu. Densebox: Unifying landmark localization with end to end object detection. arXiv preprint arXiv:1509.04874, 2015.
[13] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In Proc. Eur. Conf. Comp. Vis., pages 734–750, 2018.
[14] Tsung-Yi Lin, Piotr Doll´ar, Ross Girshick, Kaiming He,Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 2117–2125, 2017.
[15] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 2980–2988, 2017.
[16] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and Lawrence Zitnick. Microsoft COCO: Common objects in context. In Proc. Eur. Conf. Comp. Vis., pages 740–755. Springer, 2014.
[17] Fayao Liu, Chunhua Shen, Guosheng Lin, and Ian Reid. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell., 2016.
[18] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. SSD: Single shot multibox detector. In Proc. Eur. Conf. Comp. Vis., pages 21–37. Springer, 2016.
[19] Yifan Liu, Ke Chen, Chris Liu, Zengchang Qin, Zhenbo Luo, and Jingdong Wang. Structured knowledge distillation for semantic segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., June 2019.
[20] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 3431–3440, 2015.
[21] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 779–788, 2016.
[22] Joseph Redmon and Ali Farhadi. YOLO9000: better, faster, stronger. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 7263–7271, 2017.
[23] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
[24] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proc. Adv. Neural Inf. Process. Syst., pages 91–99, 2015.
[25] Abhinav Shrivastava, Rahul Sukthankar, Jitendra Malik, and Abhinav Gupta. Beyond skip connections: Top-down modulation for object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
[26] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019.
[27] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander A Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proc. National Conf. Artificial Intell., 2017.
[28] Zhi Tian, Tong He, Chunhua Shen, and Youliang Yan. Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 3126–3135, 2019.
[29] Yuxin Wu and Kaiming He. Group normalization. In Proc. Eur. Conf. Comp. Vis., pages 3–19, 2018.
[30] Saining Xie, Ross Girshick, Piotr Doll´ar, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 1492–1500, 2017.
[31] Wei Yin, Yifan Liu, Chunhua Shen, and Youliang Yan. Enforcing geometric constraints of virtual normal for depth prediction. In Proc. IEEE Int. Conf. Comp. Vis., 2019.
[32] Jiahui Yu, Yuning Jiang, Zhangyang Wang, Zhimin Cao, and Thomas Huang. Unitbox: An advanced object detection network. In Proc. ACM Int. Conf. Multimedia, pages 516–520. ACM, 2016.
[33] Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He, and Jiajun Liang. EAST: an efficient and accurate scene text detector. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 5551–5560, 2017.
[34] Chenchen Zhu, Yihui He, and Marios Savvides. Feature selective anchor-free module for single-shot object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., June 2019.

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









