







环境准备
- java环境
- kafka环境
- kafka-clients jar包
或者依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
Kafka API
Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。所以 offset 的维护是 Consumer 消费数据是必须考虑的问题。
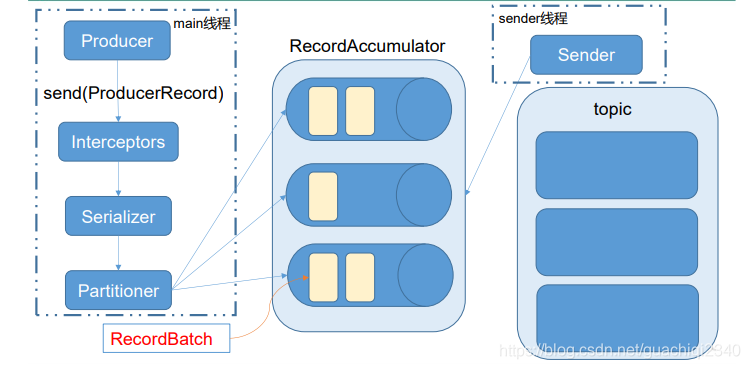
需要用到的类:
KafkaConsumer:需要创建一个消费者对象,用来消费数据。
ConsumerConfig:获取所需的一系列配置参数。
ConsuemrRecord:每条数据都要封装成一个 ConsumerRecord 对象。
小试牛刀
package com.huazai.kafka.example.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* @author pyh
* @date 2021/8/2 23:18
*/
public class CustomConsumer {
private final static String TOPIC = "test_topic";
public static void main(String[] args) {
Properties properties = new Properties();
// kafka连接地址,多个地址用“,”隔开
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.64.132:9092,192.168.64.132:9093,192.168.64.132:9094");
// 定义消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");
// 开启自动提交事务
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交offset间隔时间,单位毫秒(只有开启自动提交事务后此配置才生效)
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "500");
// 反序列化key所用到的类
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 反序列化value所用到的类
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
// 订阅主题,如果是第一次订阅该主题,则该主题之前的消息消费不到
kafkaConsumer.subscribe(Collections.singleton(TOPIC));
while (true) {
int consumedCount = 0;
// 拉取消费记录
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofMillis(1000));
// 遍历解析消费记录
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
int partition = consumerRecord.partition();
String key = consumerRecord.key();
String value = consumerRecord.value();
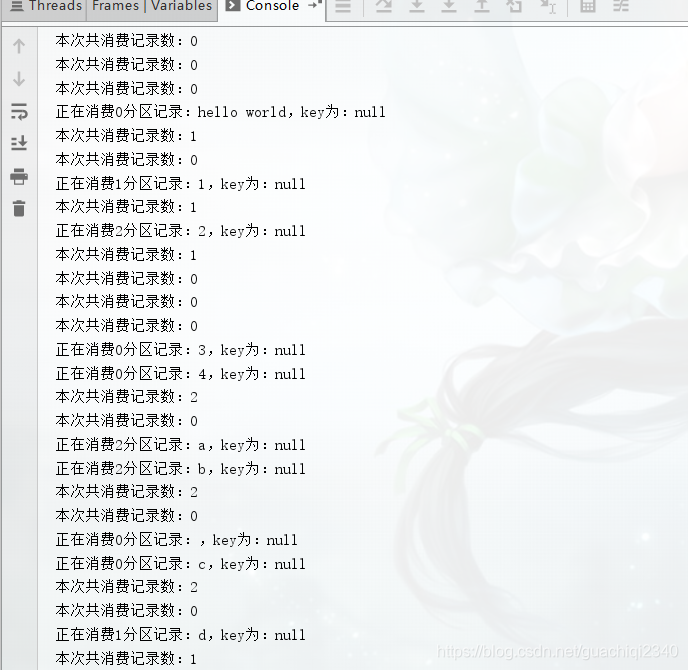
System.out.println("正在消费" + partition + "分区记录:" + value + ",key为:" + key);
consumedCount++;
}
//kafkaConsumer.commitAsync();
System.out.println("本次共消费记录数:" + consumedCount);
}
}
}
启动消费者程序后,向主题test_topic生产消息然后观察程序消费情况。此处只演示使用命令生成消息,java api生产消息参考:7.Kafka生产者API
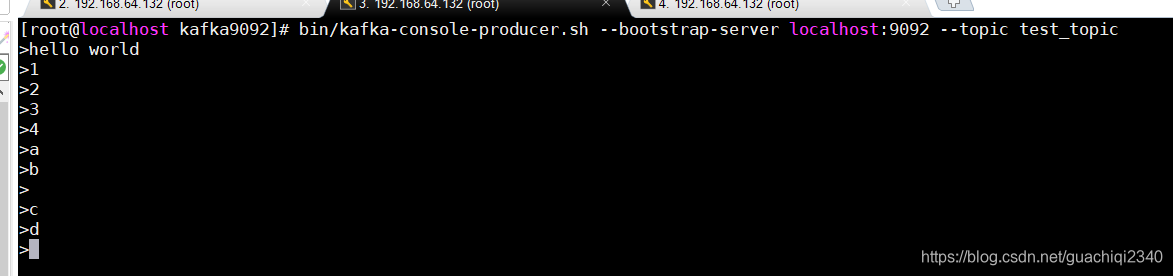
程序控制台输出如下:
自动提交offset
offset记录每个消费者组上一次消费的位置,以便下一次消费的时候从该offset之后的数据继续消费。
为了使我们能够专注于自己的业务逻辑,Kafka 提供了自动提交 offset 的功能。自动提交 offset 的相关参数如下:
enable.auto.commit:是否开启自动提交 offset 功能。
auto.commit.interval.ms:自动提交 offset 的时间间隔(开启自动提交offset之后此选项才生效)。
手动提交offset
虽然自动提交 offset 十分简介便利,但由于其是基于时间提交的,开发人员难以把握offset 提交的时机。比如设置了自动提交的时间是10s,消费者拿到数据经过一系列运算并将运算后的数据持久化到数据库,此时还要多需要5秒钟等待kafka提交offset,如果到第6秒的时候kafka挂了,重启消费者服务时候,由于没有提交offset,消费者重复消费到已经消费的数据,并再一次将数据持久化到数据库;如果将自动提交时间设置较短,kafka提交了offset之后,此时客户端出现异常或者挂了,没有将运算的数据持久化到数据库,由于offset已经提交,客户端恢复后无法拿到未处理完的数据。因此 Kafka 还提供了手动提交 offset 的 API。
手动提交 offset 的方法有两种:分别是 commitSync(同步提交)和 commitAsync(异步提交)。两者的相同点是,都会将本次 poll 的一批数据最高的偏移量提交;不同点是,commitSync 阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而 commitAsync 则没有失败重试机制,故有可能提交失败。
package com.huazai.kafka.example.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* @author pyh
* @date 2021/8/2 23:18
*/
public class CustomConsumer {
private final static String TOPIC = "test_topic";
public static void main(String[] args) {
Properties properties = new Properties();
// kafka连接地址,多个地址用“,”隔开
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.64.132:9092,192.168.64.132:9093,192.168.64.132:9094");
// 定义消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");
// 关闭自动提交事务
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 自动提交offset间隔时间,单位毫秒(只有开启自动提交事务后此配置才生效)
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "500");
// 反序列化key所用到的类
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 反序列化value所用到的类
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
// 订阅主题,如果是第一次订阅该主题,则该主题之前的消息消费不到
kafkaConsumer.subscribe(Collections.singleton(TOPIC));
while (true) {
int consumedCount = 0;
// 拉取消费记录
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofMillis(1000));
// 遍历解析消费记录
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
int partition = consumerRecord.partition();
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println("正在消费" + partition + "分区记录:" + value + ",key为:" + key);
consumedCount++;
}
// 同步提交offset
// kafkaConsumer.commitSync();
//异步提交offset
kafkaConsumer.commitAsync();
System.out.println("本次共消费记录数:" + consumedCount);
}
}
}
虽然在大部分情况下都使用异步提交offset,但是如果业务要求一定按照顺序消费,则由于异步提交offset拉取第一批数据之后提交offset由于没有阻塞,继续拉取第二批数据,则会存在提交了消费第二批数据的offset之后才提交消费第一批数据的offset。而如果是同步提交offset,则第一批数据的offset没提交完之前,则阻塞而不能继续拉取下一批数据。
如果消费者组没有开启自动提交offset,也没有手动提交offset,则下一次重新消费者,则会继续消费到重复的数据(最新提交的一次offset到最后一条范围内的数据)。
自动重置offset
自动重置offset配置:auto.offset.reset
有以下两个可选的值:
latest(默认):自动重置到最新一条数据的offset
earliest:自动重置到最早一条还没过期数据的offset
log.retention.hours指定消息过期时间,单位小时,默认为168小时,即7天
触发自动重置offset需要满足以下两个条件:
1、指定消费者组第一次消费该topic的数据,即指定的消费者组对该topic还没有初始化过offset。
2、当前消费者组的offset对应的数据已过期,即消费者组的offset对应的过期数据已不能消费。
面试题:如何重新消费到最新的数据?
将auto.offset.reset的值配置为earliest,并且重新换一个新的消费者组消费。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











