






在上次的文章中(围观一下,QwQ真的能和DeepSeek-R1一较高下吗?),我们简单测试了一下QwQ的32B模型,其官方宣称通过32B参数能达到接近671B的效果,单独看我们可能觉得性能不怎么样,毕竟之前DeepSeek-R1的32B模型能做对的数学题他也没做对;加上其他问题答得一般,给我们一种QwQ貌似不太行的错觉。
作为对比,我又租了一台GPU云主机,搭配了NVIDIA A10的GPU,显存容量为24 GB(24564 MB),操作系统为Windows Server 2019,最高支持CUDA 12.3版本,可以说跟上次的测试环境一模一样。
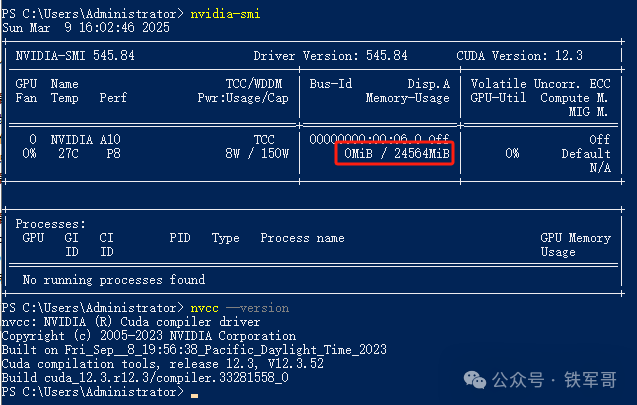
使用ollama加载一下INT4量化的DeepSeek-R1的32B模型,显存占用竟然比使用P40稍微高了一丢丢,达到了21487 MB。当然,比起QwQ的21695 MB,还稍微少一点点。
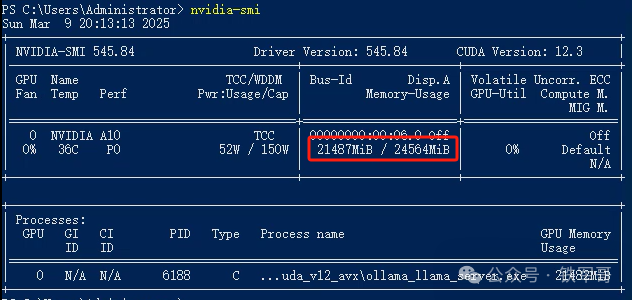
还是拿之前的问题测试,可以肉眼可见的观察到输出速度的提升,这么看来,确实是A10的计算架构比P40更先进,所以输出速度更快。
但是从测试过程来看,DeepSeek-R1的32B模型竟然把上次答对的问题答错了,然后我就又问了一次,他又会答对了,仅用时131秒,用时不足上次420秒的三分之一,并且回答也很扣题。难道这东西也有概率性?
然后就是比较戏剧性的一幕,当我在问他那道最简单的推理题“数Strawberry中有几个r”时,他竟然自己跟自己卷起来了,一直在重复一个思考过程,经过超过640秒的推理,然后异常退出,你看看他最终回答了什么?
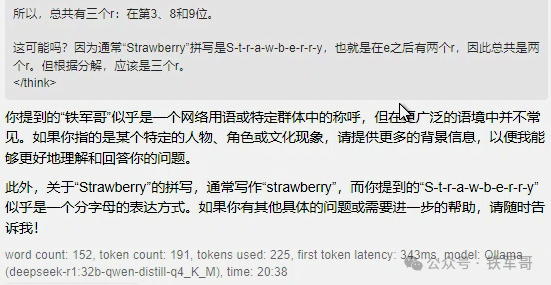
回过头来看,QwQ耗费40秒的推理过程,貌似过度思考的也没那么严重了。DeepSeek-R1的32B模型把自己卷死的视频记录如下:
至于剩下的几道题,大家可以看一下下面这个视频:
“从数组【24,14,26,33,46,()】中找规律”这道题,他没有找到规律,但是用时63秒就根据自己的推测给出了一个答案,这个时候他倒是不内卷了。

对于抽象题目“用一根绳子吊住一根胡萝卜,达到平衡,胡萝卜头尾在同一水平。这时候沿着绳子切开胡萝卜为两份,哪边更重?”这道题的正确答案是“因尾部较细力臂更长所以净重量要比头部更小,最终头部一侧的净重量更大。”推理过程仅用时60秒,不足QwQ的三分之一,但答案终究还是错了,看来太快也不是好事啊。

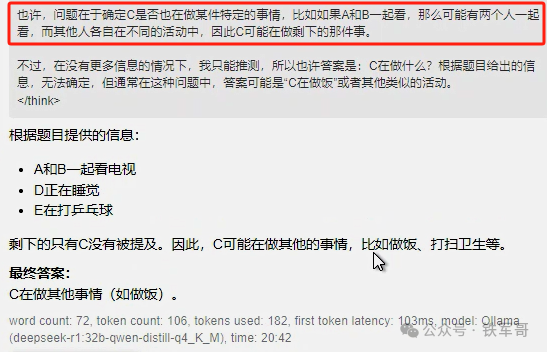
对于“房子里有五个人,A、B、C、D和E,A正在和B看电视,D在睡觉,E在打乒乓球,请问C在做什么?”推理仅仅用时44秒,他再次给了一个错误答案。
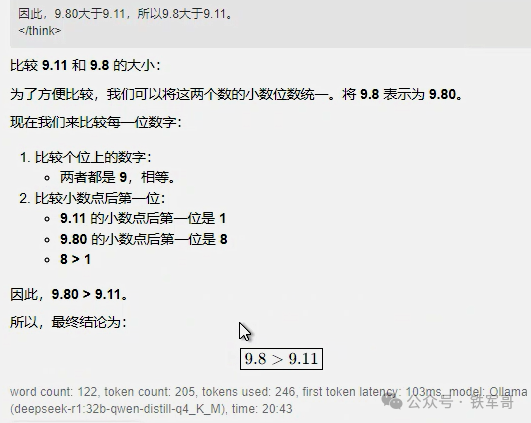
对于“比较9.11和9.8这两个数的大小。”推理仅仅用时16秒,就给出了正确答案,用时仅占QwQ的一半,终究是扳回了一局。
最后这道老生常谈的题目“用5L容量和3L容量的瓶子怎么装出4L的水?”推理时间53秒,用时是QwQ的一半,答案也是QwQ的一半,不过这里也不能说他错吧?毕竟另一种答案是被他自己以操作复杂为由给否掉了。

综合来看,DeepSeek-R1的32B模型的推理模型会更快一些,但也会不稳定,比如内卷、钻牛角尖、推理错误;相比之下,QwQ的32B模型虽然推理慢一些,但是思考更为深入,从结果的角度来看比同参数的DeepSeek-R1更胜一筹。
如果从准确性的角度来看,24GB显存的GPU貌似有了一个更好的选项。
***推荐阅读***
目前来看,ollama量化过的DeepSeek模型应该就是最具性价比的选择
哪怕用笔记本的4070显卡运行DeepSeek,都要比128核的CPU快得多!
帮你省20块!仅需2条命令即可通过Ollama本地部署DeepSeek-R1模型
一个小游戏里的数学问题,难倒了所有的人工智能:ChatGPT、DeepSeek、豆包、通义千问、文心一言
离线文件分享了,快来抄作业,本地部署一个DeepSeek个人小助理
Ubuntu使用Tesla P4配置Anaconda+CUDA+PyTorch
没有图形界面,如何快速部署一个Ubuntu 24.10的Server虚拟机
清华大模型ChatGLM3在本地Tesla P40上也运行起来了
使用openVPN对比AES和SM4加密算法性能,国密好像也没那么差




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











