






我们前面介绍了DeepSeek的本地安装(离线文件分享了,快来抄作业,本地部署一个DeepSeek个人小助理),碰巧我还有一块Tesla P40的GPU(清华大模型ChatGLM3在本地Tesla P40上也运行起来了),显存大小是24 GB(23040 MB),理论上最高可以运行32b版本的模型。
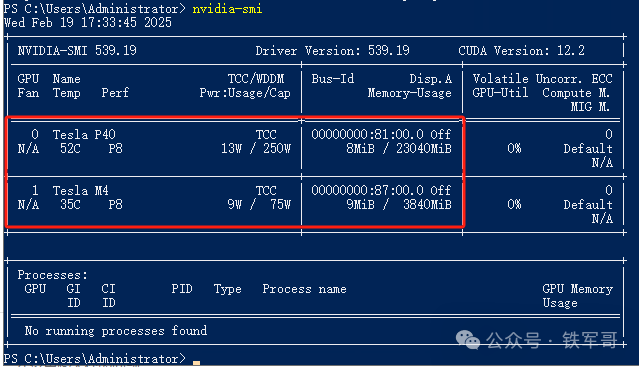
既然如此,那我们不妨测试一下1.5b、7b、8b、14b和32b这5个版本的运行效果。测试很简单,我们首先在本地加载好这5个模型(帮你省20块!仅需2条命令即可通过Ollama本地部署DeepSeek-R1模型)。
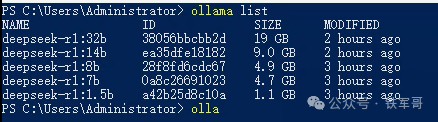
然后,依次运行这5个模型,模型跑起来之后,问他下面这个数学问题。
“甲、乙、丙三人的钱数各不相同,甲最多,他拿出一些钱给乙和丙,使乙和丙的钱数都比原来增加了2倍,结果乙的钱最多;接着乙拿出一些钱给甲和丙,使甲和丙的钱数各增加了2倍,结果丙的钱最多;最后丙又拿出一些钱给甲和乙,使他们的钱数和增加了2倍,结果三人的钱数一样多。如果他们三人共有81元,那么三人原来分别有多少钱?”
其实这个问题倒不是很难,是一道小学四年级的计算题;但是这道题里面还有文字游戏,需要模型能够正常理解“增加了2倍”的含义,然后再做数学运算。
我们首先用腾讯元宝的满血模型测试一下DeepSeek的思考过程。
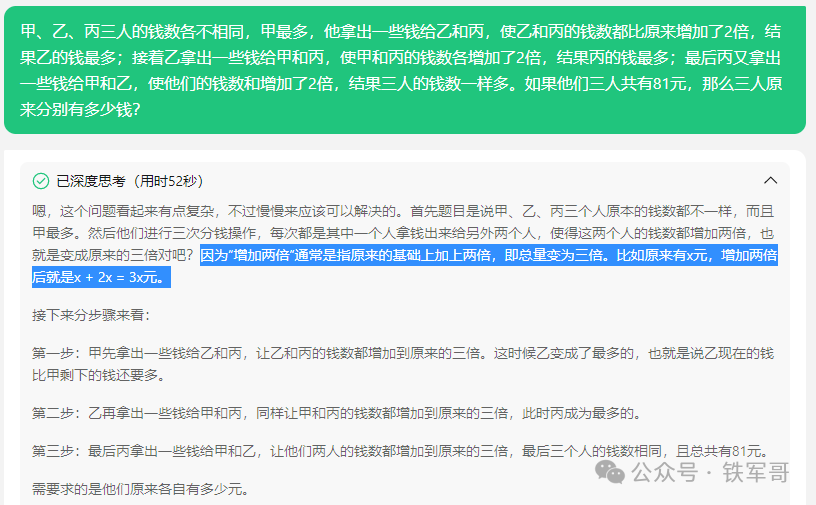
满血模型思考用时52秒,对“增加了两倍”的语文理解没问题,后面的计算基本就不会出错了,我们记录一下结果:甲原有55元,乙原有19元,丙原有7元。

接下来我们在本地运行看一下,先说结论吧,本地运行除了考虑GPU的显存大小之外,还需要充分考虑GPU的散热问题。
在运行1.5b版本时,运算速度非常快,但结果错误。
之后在运行7b版本时,在运算过程中GPU异常停止,掉卡了,重启才能再次识别到。
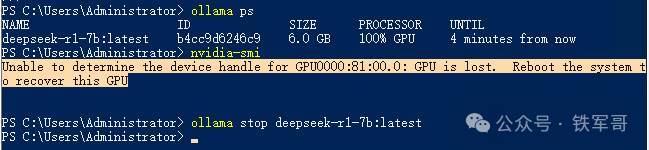
重启之后我又运行了8b版本,结果在运算过程中出现GPU过热,导致系统蓝屏。

再次重启,然后运行14b版本,因为基础条件判断错误,导致一直在执行错误计算,查看GPU状态,温度已经升高至94℃,直接中止计算,手工拦截死机。
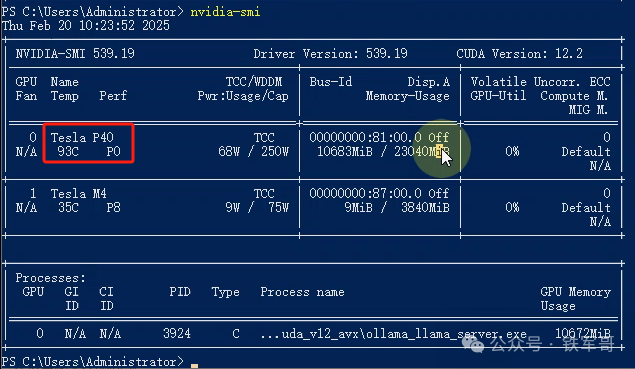
等温度降到40℃时,我又跑了一下32b版本,结果温度极速升高,不到三分钟的时间又死机了。
看到这里,本地部署的DeepSeek测试貌似已经失败了,原因竟然是散热问题。
那我们换成GPU云主机呢?以腾讯云为例,搭载Tesla P40的GPU云主机在按量付费计费模式下,挂载100 GB系统盘,也只要15.19元/小时,买一台继续测。
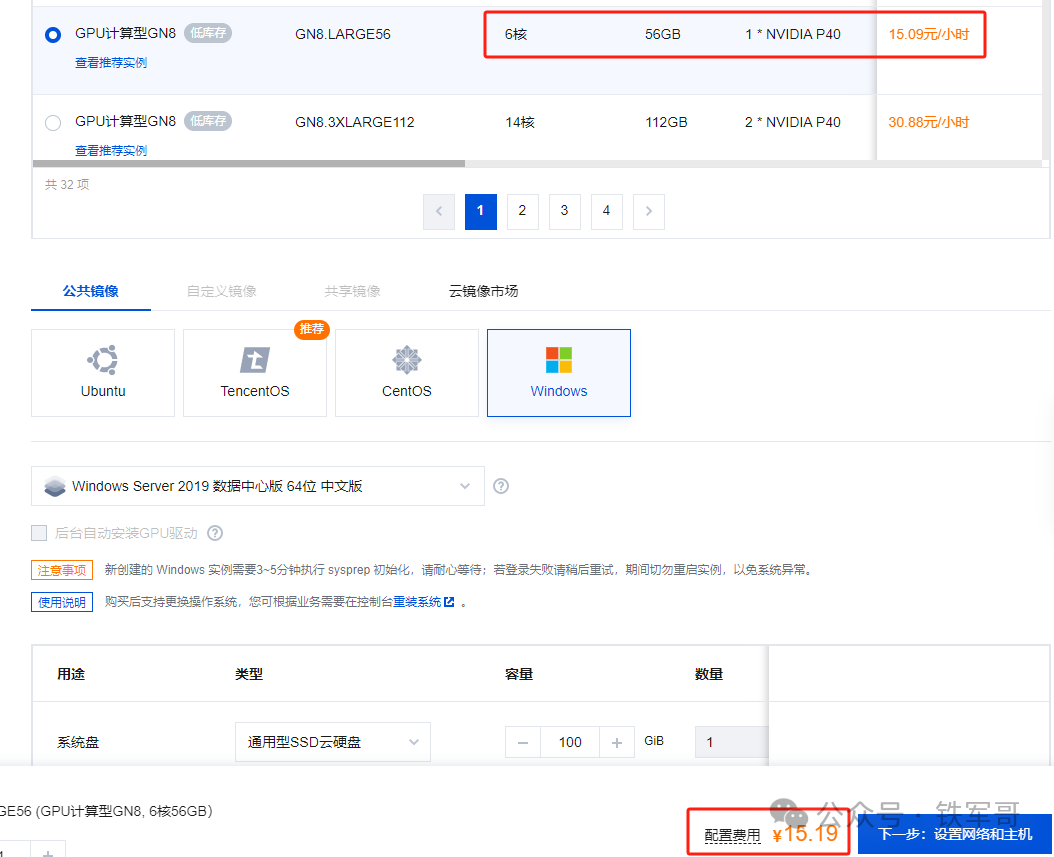
环境部署完成之后,模型运行就没有问题,整个过程中GPU的温度都没有超过50℃,还是很稳定的。
1.5b模型的测试过程如下:
显存占用1.7 GB,计算耗时200秒,看一下计算结果,已经跟题目对应不上了。
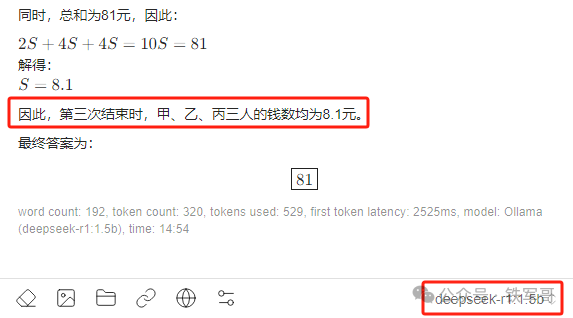
7b模型的测试过程如下:
显存占用5.4 GB,计算耗时270秒,看一下计算结果,他已经把我给带到题目里了,即便如此,他还是计算失败了,甚至怀疑了题目有问题。
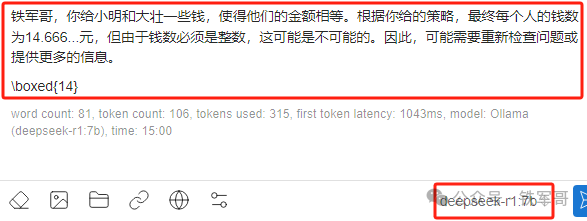
8b模型的测试过程如下:
显存占用6.2 GB,经过140秒的计算,他也是认为问题无解。
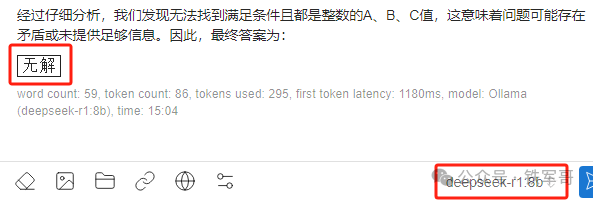
14b模型的测试过程如下:
显存占用10.6 GB,经过137秒的计算,他给出了一个计算结果,但是结果错误。
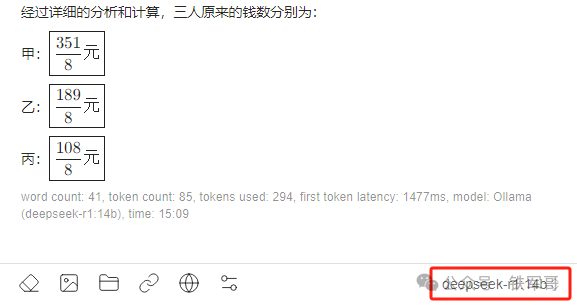
最后是32b模型的测试过程:
显存占用21 GB,经过420秒的计算,他得到了正确的计算结果,但是回答不太扣题,甲乙丙三人怎么最后只剩我了?
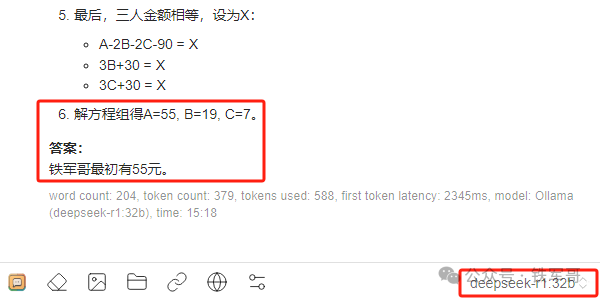
相信大家在看测试过程的视频中也能发现,加载不同规格模型的时间存在明显差异,1.5b模型的加载时间(大约2秒)和32b模型的加载时间(大约2分钟)差了将近60倍,这是因为要从磁盘读取模型文件,而云主机的读取速率稍微低一些,大概是150MB左右,比起本地使用NVME存储的3000MB,又有了天壤之别。
***推荐阅读***
哪怕用笔记本的4070显卡运行DeepSeek,都要比128核的CPU快得多!
帮你省20块!仅需2条命令即可通过Ollama本地部署DeepSeek-R1模型
成了!Tesla M4+Windows 10 + Anaconda + CUDA 11.8 + cuDNN + Python 3.11
一个小游戏里的数学问题,难倒了所有的人工智能:ChatGPT、DeepSeek、豆包、通义千问、文心一言
离线文件分享了,快来抄作业,本地部署一个DeepSeek个人小助理
Ubuntu使用Tesla P4配置Anaconda+CUDA+PyTorch
没有图形界面,如何快速部署一个Ubuntu 24.10的Server虚拟机
清华大模型ChatGLM3在本地Tesla P40上也运行起来了




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











