




一:事务控制演进
我们知道,mysql 事务有ACID特性。 在多事务并发时候,会出现一系列问题: 脏读,幻读,不可重复读等问题。 那么,针对事务的控制,mysql经历以下几种演进
- 排他锁(互斥锁): 读写都加锁
- 读写锁:读和读不互斥,其他互斥: 读不加锁,写加锁
- MVCC多版本控制:写和写互斥,其他不互斥,在RC和RR两种隔离级别下起作用。
- 原理:读不加锁,写加锁。 但是写的时候,会将修改前的记录保存快照版本,在commit前,其他事务读取快照版本。
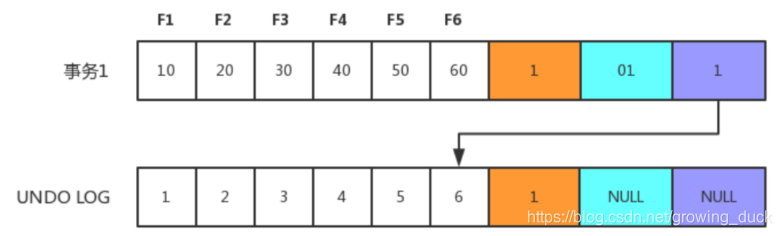
- 示例:假如现在新插入一条数据如下(前面为数据,后面分别为:隐藏行id,当前正在操作数据的事务id,当前事务指向的回滚版本)
- 事务1修改数据锁定该行,记录redo log;拷贝上面数据为快照记录到undo log; 修改当前值,填写事务编号,回滚指针指向undo log中修改前的行。
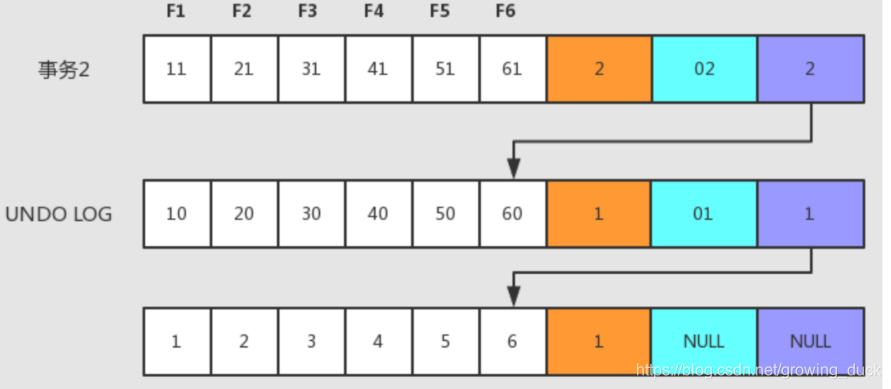
- 事务2也修改(如果事务1还未提交释放锁,那就只能先等待),过程如上
如上,undo log中便会存在多个快照版本,这多个快照版本可能都在被其他读事务使用(新来的读事务会读最近一次快照版)。 此外,后台purge线程会定期清除没有活跃事务操作的早期快照版本。
- MVCC已经实现了读读、读写、写读并发处理,如果想进一步解决写写冲突,可以采用两种方案:
- 乐观锁 悲观锁

二: 事务隔离级别
基于上述演进的解决方式,mysql实际体现是通过事务隔离级别:
- Read Uncommitted 读未提交:可能发生脏读现象
- Read Committed 读已提交:可能发生不可重复读现象,一个事务多次读取过程中,别的事务修改并提交了数据。
- Repeatable Read(默认) 可重复读:可能发生幻读, 一个事务多次读取的过程中,别的事务插入或删除了数据。
- Serializable 串行化:所有的增删改查串行执行。它通过强制事务排序,解决相互冲突,这个级别可能导致大量的超时现象的和锁竞争,效率低下。
三:锁机制和实战
事务隔离级别的实现,就是通过底层锁机制 + log(redo log 和 undo log)实现。 有表锁和行锁,下面来看看innodb引擎下的行锁机制:
行锁原理:
- 行锁是通过对索引页的记录加锁实现,有3种算法:
- RecordLock: 锁定单个索引行记录(记录锁,在RC, RR级别下都支持)
- GapLock: 锁定索引行之间的间隙(范围锁,RR下支持)
- Next-key Lock: 前两种组合,同时锁住索引记录,以及相邻索引之间的间隙(记录+范围锁,RR下支持)
mysql的默认隔离级别是RR,InnoDB对于操作记录的加锁,都是先使用Next-key Lock,如果当前sql有唯一索引,则降级为RecordLock。 下面看看几种sql下的情况:
- select ... from 语句: 普通的查询语句,采用MVCC机制实现非阻塞读,不加锁。
- select ... from lock in share mode语句: 使用Next-Key Lock锁住相关索引记录及之间的间隙,如果扫描发现唯一索引,降级为RecordLock。
- select ... from for update语句:追加了排他锁,InnoDB会使用Next-Key Lock锁进行处理,如果扫描发现唯一索引,降级为RecordLock。
- update ... where 语句:InnoDB会使用Next-Key Lock锁进行处理,如果扫描发现唯一索引,可以降级为RecordLock锁。
- delete ... where 语句:InnoDB会使用Next-Key Lock锁进行处理,如果扫描发现唯一索引,可以降级为RecordLock锁。
- insert语句:InnoDB会在将要插入的那一行设置一个排他的RecordLock锁。
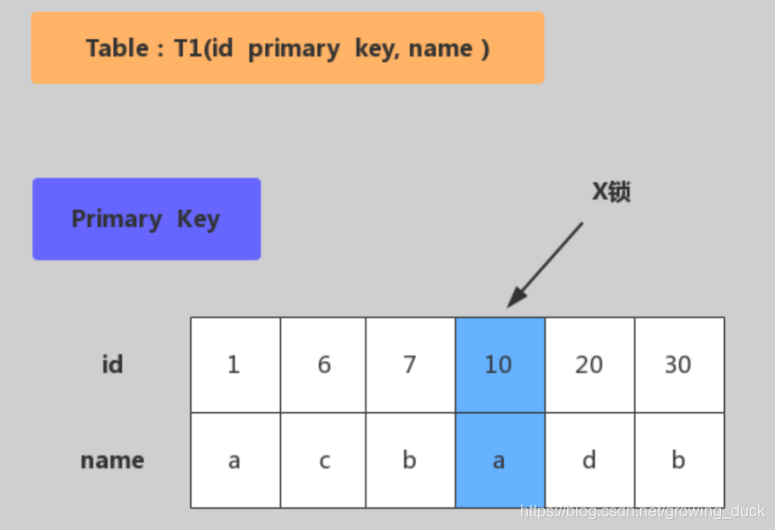
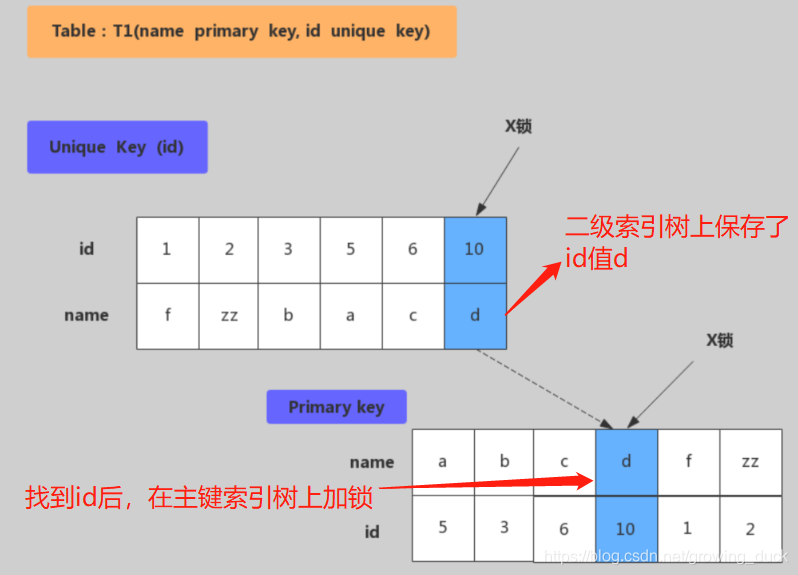
下面看一下实际例子:update t1 set name=‘XX’ where id=10
如果id是主键: 主键加锁, 在主键的索引树上,锁住10这一行记录(主键索引是覆盖索引,也包含了其他data数据)
如果id是唯一索引,name才是主键: 先在id的二级索引树上加锁,通过id找到主键name,再到主键索引树上加锁
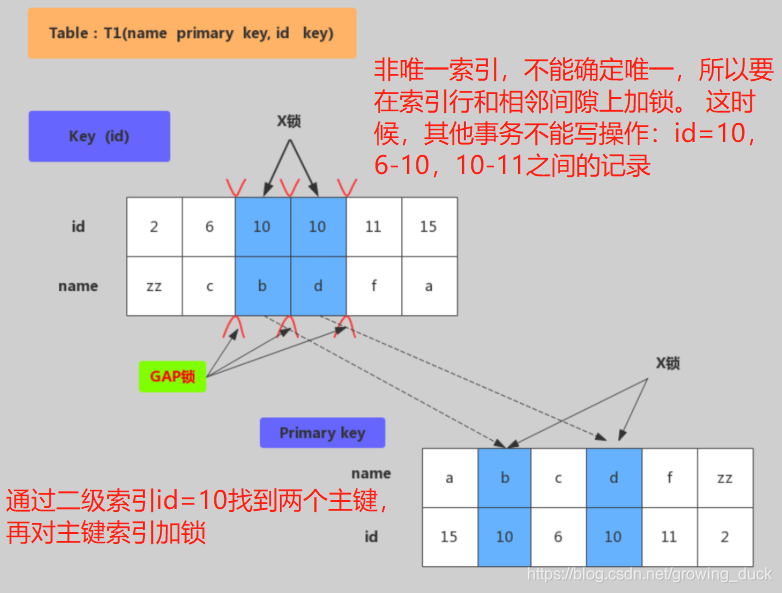
name是主键,id是非唯一索引:先在二级索引树上加锁,再到主键索引树加锁
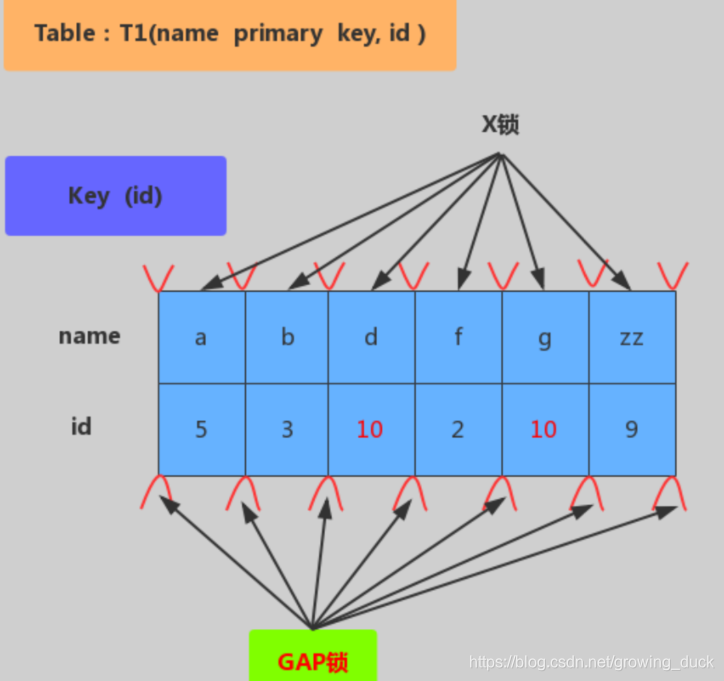
如果id没有索引:不能确定操作哪一条索引,那么所有的索引和间隙都会被上锁,也就是表锁(这也是我们强调要尽量创建索引的原因)
悲观锁和乐观锁,这里就不再说了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









