









 本文探讨了回归算法在宝可梦CP值预测中的应用,通过梯度下降法寻找最佳模型,讨论了过拟合问题及解决策略,如正则化和考虑更多特征。
本文探讨了回归算法在宝可梦CP值预测中的应用,通过梯度下降法寻找最佳模型,讨论了过拟合问题及解决策略,如正则化和考虑更多特征。
目录
回归(Regression)的应用场景

- 股票预测:输入股市的历史数据,输出明天股市的预测值;
- 无人驾驶:输入图片,输出方向盘的角度;
- 产品推荐:输入使用者和商品,输出该使用者购买该商品的可能性;
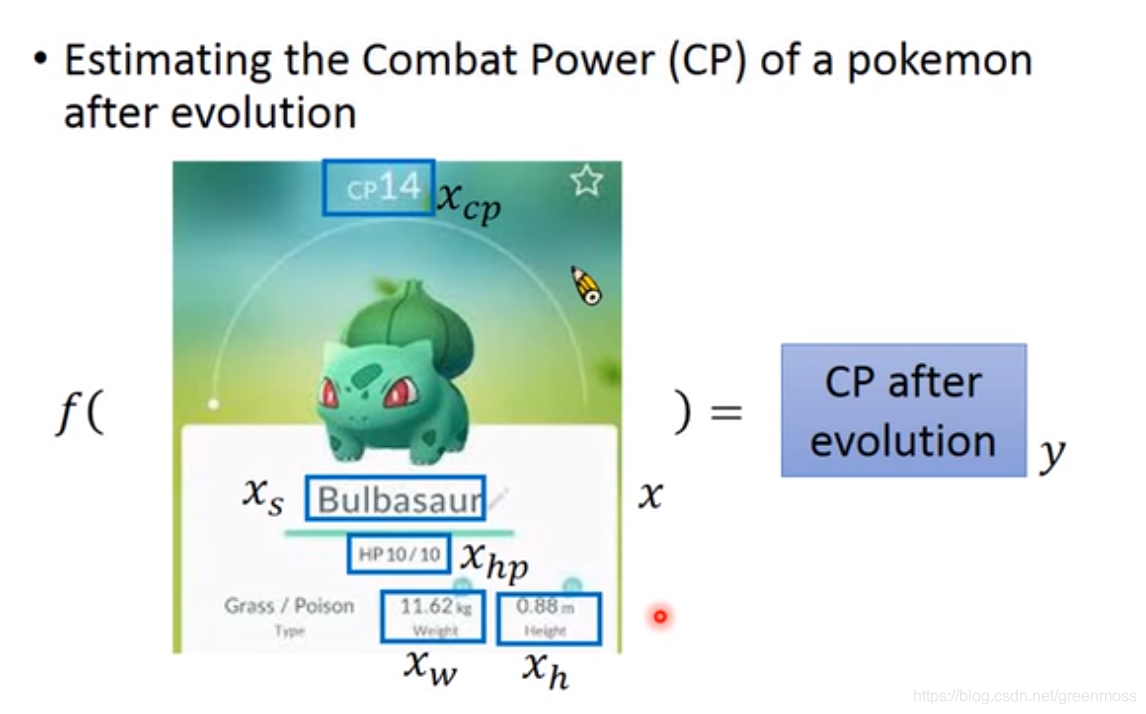
- 预测宝可梦(pokemon)进化后的CP(Combat Power)值;
- xcp:进化前的CP值;
- xs:属于哪一种物种;
- xhp:生命值;
- xw:重量;
- xh:高度;
Step1:Model-确定模型

-
y
=
b
+
w
x
c
p
y = b + wx_{cp}
y=b+wxcp
- y y y为进化后的CP值
- b , w b,w b,w为参数,可以为任意值
- x c p x_{cp} xcp为进化前的CP值
Step2:Goodness of Function-评估模型的好坏
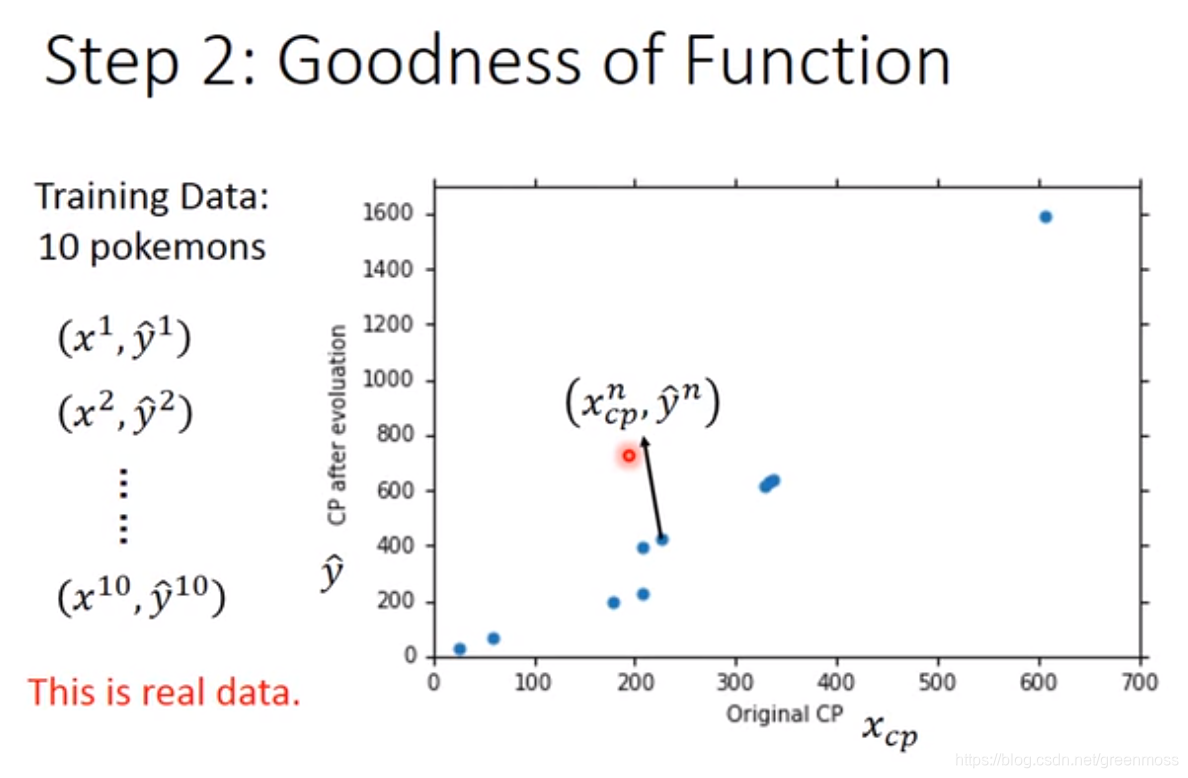
- x c p n x_{cp}^n xcpn表示第n只宝可梦进化前的CP值, y ^ n \hat y^n y^n表示第n只宝可梦进化后实际的CP值, y n y^n yn表示根据方程预测出的宝可梦进化后的CP值。

- 损失函数(Loss Function):采用最小二乘法,评估方程的好坏;
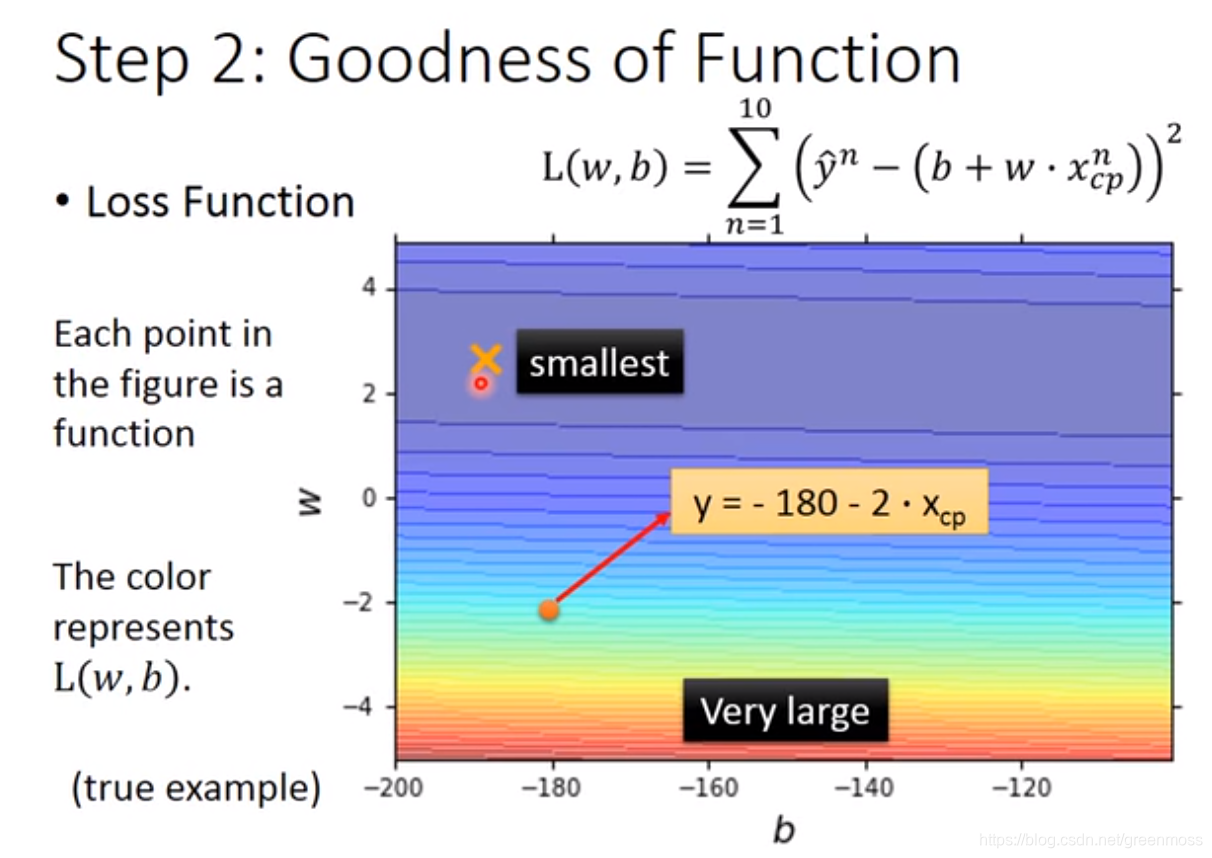
- 越偏红色,代表方程越不好;越偏蓝色,代表方程越好,误差越小;
Step3:Best Function-选出最佳模型
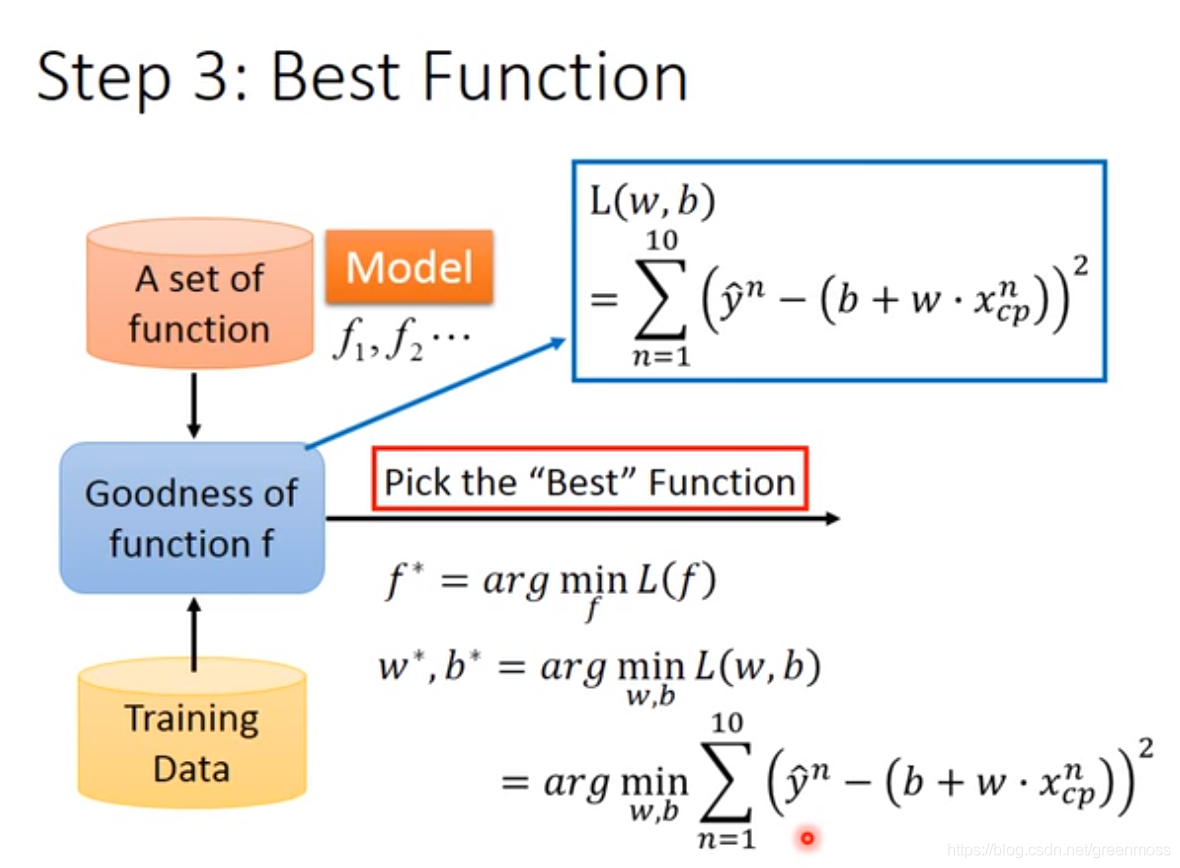
- arg是变元argument的缩写;
1).Gradient Descent-梯度下降
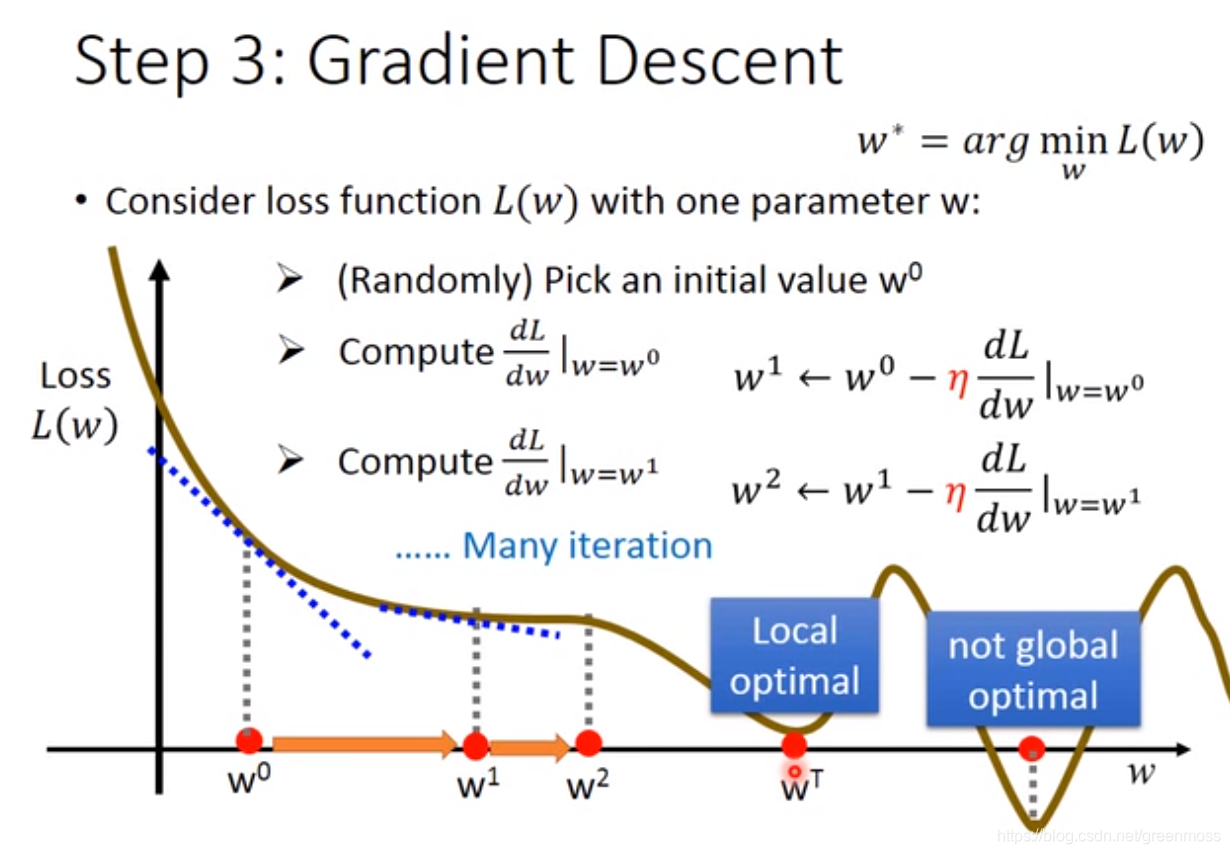
- 前提:需要损失函数Loss Function是可微分的;
- 上图以仅有一个参数的损失函数 L ( w ) L(w) L(w)为例,说明如何寻找 w w w使函数值最小;
- 随机选择一个初始值 w 0 w^0 w0,计算该点的微分值,如果为负数,则需要增加 w 1 w^1 w1的值;否则,减少 w 1 w^1 w1的值;故 η \eta η前面为负号;
- 每个step的大小取决于两点:现在所处位置的微分值;常数项 η \eta η,称为learning rate;
- 经过多次迭代后,可得到局部最优解(local optimal),即微分值为零的点;线性函数得到局部最优解就是全局最优解(global optimal),非线性函数的局部最优解可能不等同于全局最优解;

- 损失函数有两个参数的情况;
- 上图中,最下面一行的下标写错了, w 2 w^2 w2和 b 2 b^2 b2应该是根据点 ( w 1 , b 1 ) (w^1,b^1) (w1,b1)的微分值得到的;
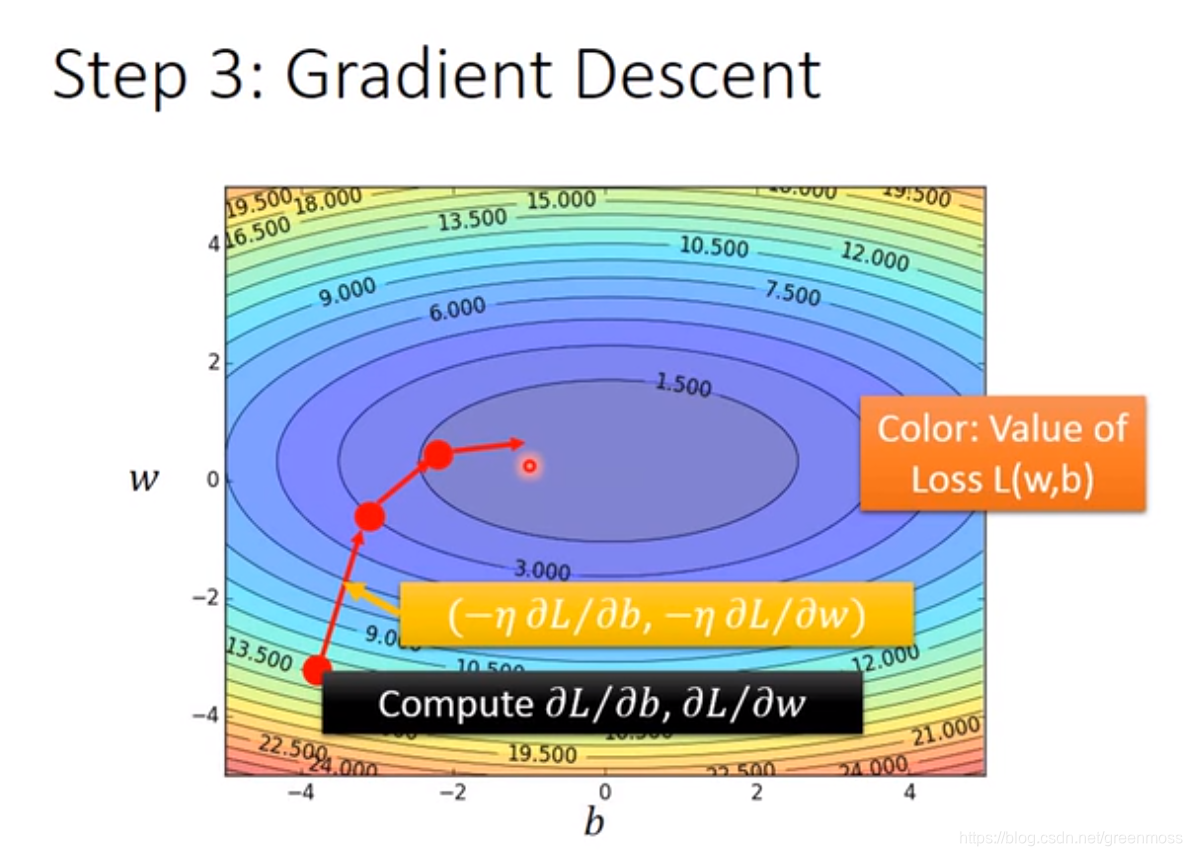
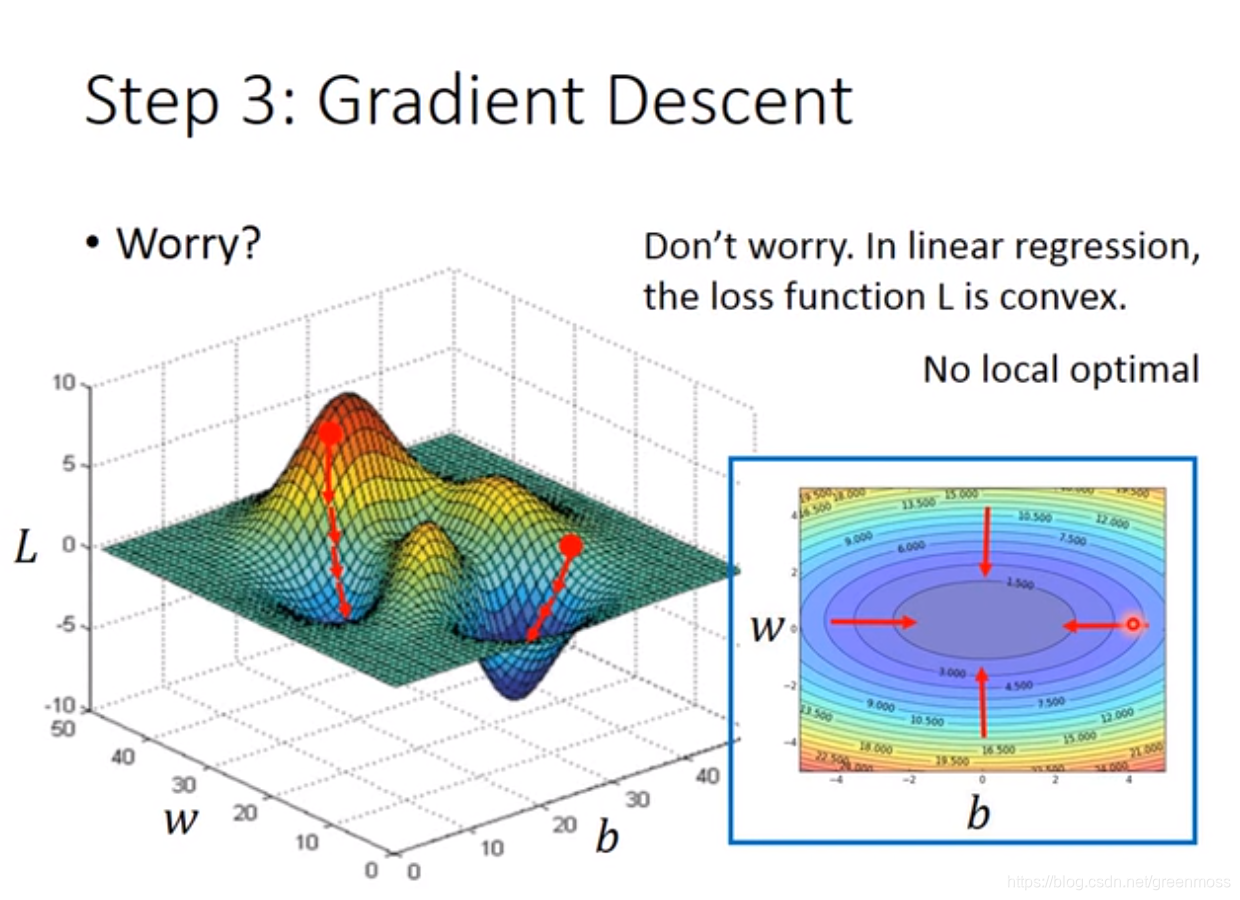
- 梯度下降的过程如上图所示;
- 在线性回归中,损失函数是凸函数(convex),局部最优解即为全局最优解;

- 求导得到偏微分


- 用一组数据训练(training data),再用另一组数据做测试数据(testing data);
- 测试数据中得到的average error可能会比训练数据得到的average error更大一点;

- 尝试更加复杂的模型,增加一个二次项,如上图所示,可以看到得到的训练数据和测试数据的average error都更小,说明模型更好;
- 图中,右上角为训练数据,右下角为测试数据;

- 同理,考虑三次方的情况,可以看到训练数据和测试数据的average error都更小了一点;


- 考虑四次方的时候,可以看到训练数据得到的average error为14.9,比之前的更小,但测试数据的average error变大了,变为28.8;
- 考虑五次方的时候,得到的结果更加糟糕;


- 比较不同模型的结果;
- 因为高次方包含低次方的结果(将前面的系数设为零即可),所以在训练数据中的得到的average error随着次数的增大越来越小;
- 在训练数据中得到比较好的结果,在测试数据中得到不好的结果,这种现象叫做过拟合(overfitting);


- 当宝可梦数量达到60只的时候,显然不是上述的函数关系,进化后的CP值与宝可梦的物种有关;
- 将不同的物种用不同的颜色表示,如上图,所以需要重新设计模型;
2).根据不同物种重新设计模型


- 同一个模型的不同写法,第二种是写成线性函数;

- 采用上述模型,得到的结果如图所示;
- 有些地方不是拟合得很好,上述模型可以进一步优化吗?

- 修改模型,并将宝可梦的hp值考虑进去;
- 根据得到的结果,训练数据的average error为1.9,测试数据的average error为102.3,过拟合了;


- y = b + ∑ w i x i y=b+\sum w_ix_i y=b+∑wixi,考虑不同物种情况下,将模型写成线性函数的形式;
- 正则化(regularization),增加一项 λ ∑ ( w i ) 2 \lambda\sum (w_i)^2 λ∑(wi)2(惩罚项), λ \lambda λ是一个常数;
- w i w_i wi越小,表示函数越平滑,对输入值x不敏感;
- λ \lambda λ越大,表示 λ ∑ ( w i ) 2 \lambda\sum (w_i)^2 λ∑(wi)2在损失函数中的影响力越大,找到的函数越平滑;
- 在训练数据中, λ \lambda λ越大,越倾向于考虑w的值,减少考虑training error的值,得到的error越大;
- 在测试数据中, λ \lambda λ越大,得到的error先减小,后增大;我们喜欢平滑的函数,这样对输入值不敏感,但是又不能太平滑(例如,最平滑的情况就是一条水平线);所以需要调整 λ \lambda λ,来得到比较理想的函数,图中 λ = 100 \lambda=100 λ=100时比较理想;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









