







java泛型
java泛型是J2 SE1.5中引入的一个新特性,其本质是参数化类型,把所操作的数据类型指定为一个参数(type parameter),这种参数类型可以用在类、接口、和方法的创建中,分别称为泛型类、泛型接口、泛型方法。
ArrayList list = new ArrayList();
新建了一个动态数组,可以往里面存东西。但这个动态数组默认的接受类型是Object,在java中所有的类都继承了Object,也就是Object是所有的类的父类。子类转父类必然是可以的,这样就导致了一个问题,所有类型的东西都可以往这个动态数组里面放,所以get(0) 返回的类型是Object。这样我们把里面的对象取出来用的话,或许往往需要转型。
在写代码的过程中,能记得那个是那个,还是可以的。但数据量很大的时候,怕是很困难,往往类型转换的时候会弄错类型。泛型的加入解决了这个问题。
使用泛型
泛型的用法是在容器后面添加,Type可以是类,抽象类,接口。泛型表示这种容器,只能存放这个类型的,如果放错了,编译是通不过的。
泛型的简写
为了不使编译器出现警告,需要前后都使用泛型,像这样:
ArrayList<Hero> heros = new ArrayList<Hero>();
不过JDK7提供了一个可以略微减少代码量的泛型简写方式
ArrayList<Hero> heros2 = new ArrayList<>();
后面的泛型可以用<>来代替,聊胜于无吧
java类型擦除
java类型擦除说的是,泛型在编译前,是存在的,在编译过后是不存在的。是为了兼容以前的JVM版本,因为1.5版本之前的JVM并不知道泛型是个什么东西。
ArrayList和HashMap查找的快慢
ArrayList,动态数组。对元素增删的实现是通过对数组的复制。
查找一个元素,在我们不知道这个元素的位置的时候,只能通过遍历的方法。所以时间复杂度是O(n)。
HashMap也是一种数据存储结构,元素以键值对的方式存储,并且允许使用null键和null值。key不允许重复,因此只能有一个键为null,另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。
HashMap由数组和链表来实现对数据的存储。
HashMap采用Entry数组来存储key-value对,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Entry实体,以此来解决Hash冲突的问题。

从下图可以发现数据结构由数组+链表组成,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key.hashCode())%len获得,也就是元素的key的哈希值对数组长度取模得到。比如下述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。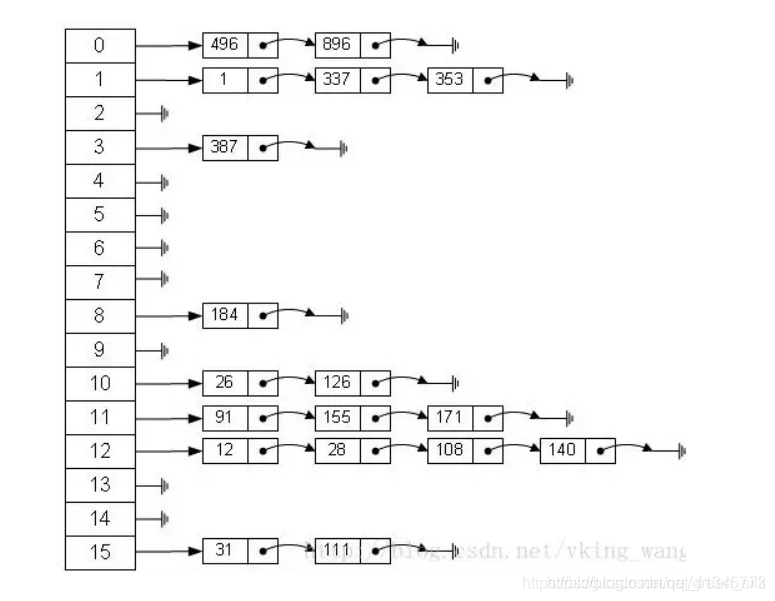
而HashMap寻找元素为什么这么快呢,看看这个函数的源代码
// An highlighted block
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
(暂时没看懂)
总的来说就是它首先获得的是这个key的hash值,然后在一个table里去遍历,找到符合条件的entry,这里的table应该指的是链表的头结点+链表。
时间复杂度一般是O(1)。
java的函数式编程
看来看去,说的是,好像Lambda表达式就是java的函数式编程。
Lambda表达式说白了就是匿名类的简写。
具体用法:

















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









