




创新点
利用LLM 以及文本知识和记忆来创建我的世界中的通用智能体。
相比于强化学习方法,获取钻石任务成功率高 ,通用性可泛化性好,训练成本低。能处理长周期、复杂的任务并应对开放世界中的不确定性。
RL的缺点
- 训练的步数太多
- 面对新任务时,泛化性太差。
- 将要获取的目标硬编码进模型的weights中,对于训练好的RL模型改变目标时较为困难
由于上述两点,RL面对获取所有物品的任务时,所需要的训练步骤非常多。
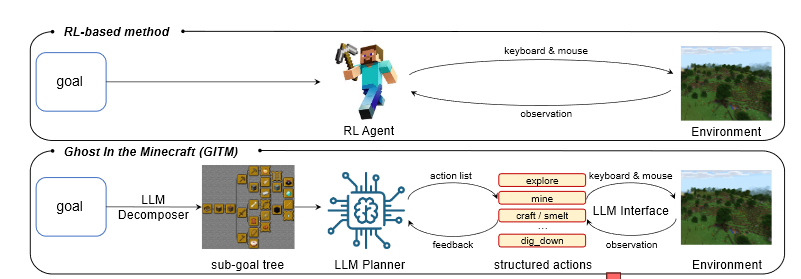
RL agent 需要考虑如何将长周期的复杂任务映射为键鼠操作,难度大。
LLM-based agent 考虑分层处理的方式,将目标分解为多个子目标,然后转化为结构化动作,最终转化为键鼠操作。
这种处理的方式和人类思考的过程很像,通过文本知识和记忆,可以获得发更好的泛化性和训练性能。
架构
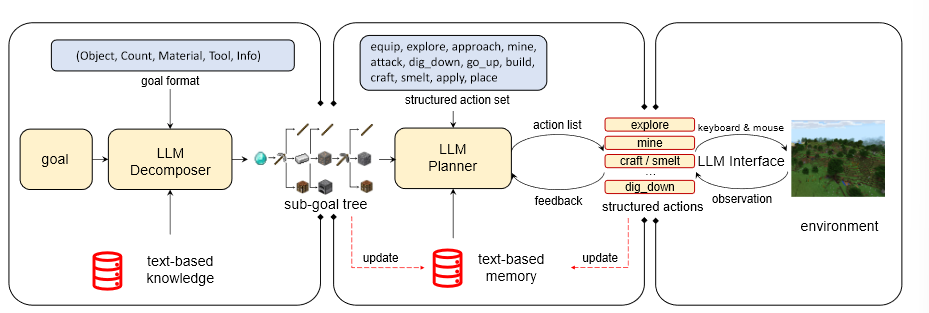
LLM Decomposer
将goal 分解为 sub-goal

- 将goal输入LLM Decomposer,会将goal递归分解,构成一个sub-goal
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









