




 HDFS(Hadoop Distributed File System)是一种分布式文件系统,适用于大规模数据处理。其主要特点是将大文件分成块进行存储,每个块有多个副本以保证容错性。NameNode作为目录节点管理命名空间和元数据,DataNode负责数据的存储和读取。HDFS不支持低延迟访问和多用户写入,适合批量读写操作。数据存放策略以机柜为基础,确保高可用性和带宽利用。写入时采用流水线复制策略,读取时根据机柜ID选择最近的数据节点。HDFS通过心跳检测、副本策略和简单的一致性模型确保可靠性。
HDFS(Hadoop Distributed File System)是一种分布式文件系统,适用于大规模数据处理。其主要特点是将大文件分成块进行存储,每个块有多个副本以保证容错性。NameNode作为目录节点管理命名空间和元数据,DataNode负责数据的存储和读取。HDFS不支持低延迟访问和多用户写入,适合批量读写操作。数据存放策略以机柜为基础,确保高可用性和带宽利用。写入时采用流水线复制策略,读取时根据机柜ID选择最近的数据节点。HDFS通过心跳检测、副本策略和简单的一致性模型确保可靠性。
HDFS
局限性
- 不适合低延迟数据的访问
- 无法高校存储大量的小文件
- 不支持多用户写入以及任意修改文件
块
- HDFS分布式文件系统中的文件被分成快进行存储,“块”是文件处理的逻辑单元
- 默认块是64MB,比文件系统的快大得多
- 使用抽象块的好处:
可以存储任意大的文件,而不会受网络中任意单个节点磁盘大小限制;
使用抽象块作为操作单元,可以简化存储系统;
块有利于复制容错的实现
目录节点
目录节点 NameNode 是集群中的主节点,负责管理整个HDFS的命名空间和元数据,是客户端访问HDFS系统的入口,目录节点保存文件系统的三种元数据
- 命名空间:整个系统的目录结构
- 数据块与文件名的映射表
- 每个数据块副本的位置信息,每个数据块都默认有3个副本。“副本因子”,保存多少分副本,也在目录节点中
数据节点
数据节点一般就是集群中的一台机器,复杂数据的存储和读取
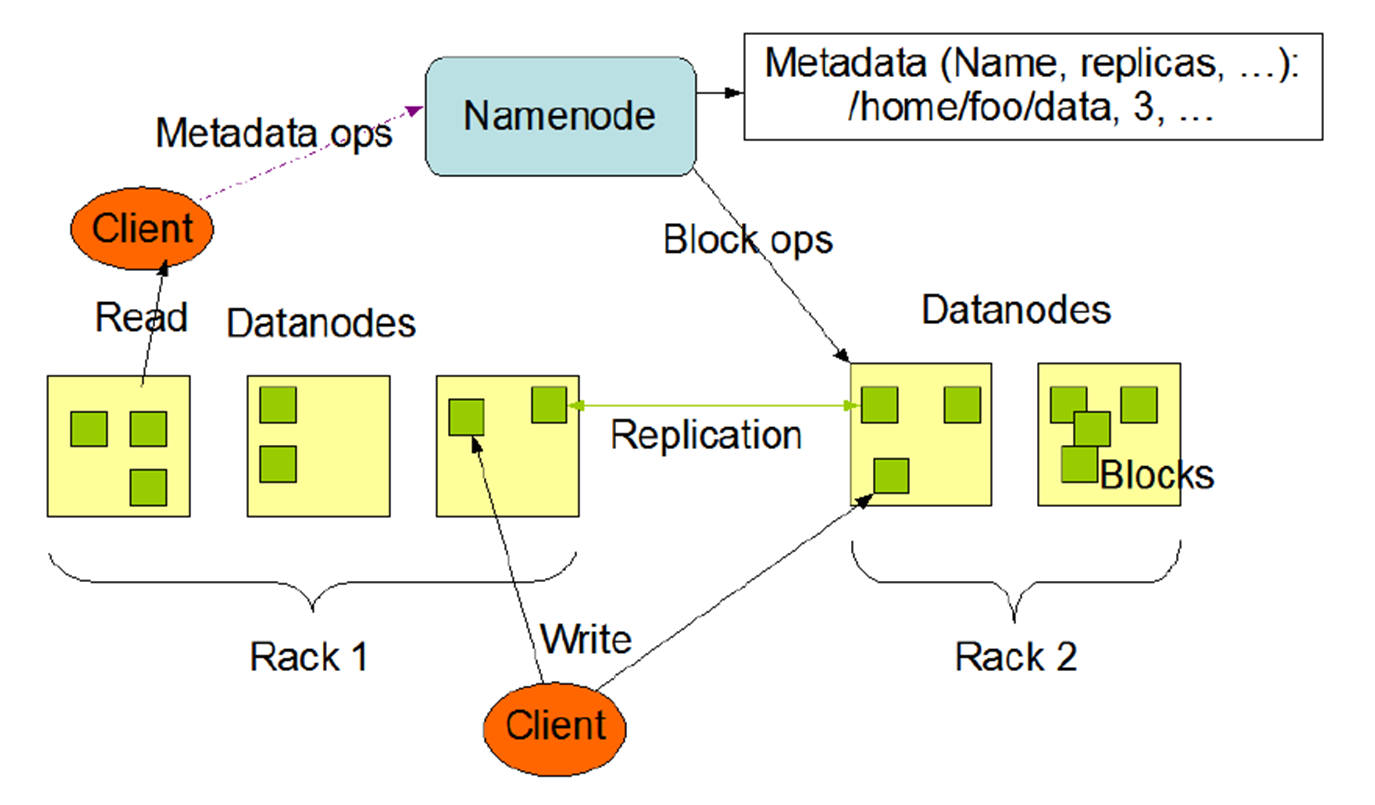
- 写入的时候,由目录节点分配数据块的保存,客户端直接写入到对应的数据节点
- 读取时,客户端从目录节点获得数据块的映射关系,直接到对应的数据接待你读取数据
- 数据节点要根据目录节点的命令创建、删除数据块和进行副本复制
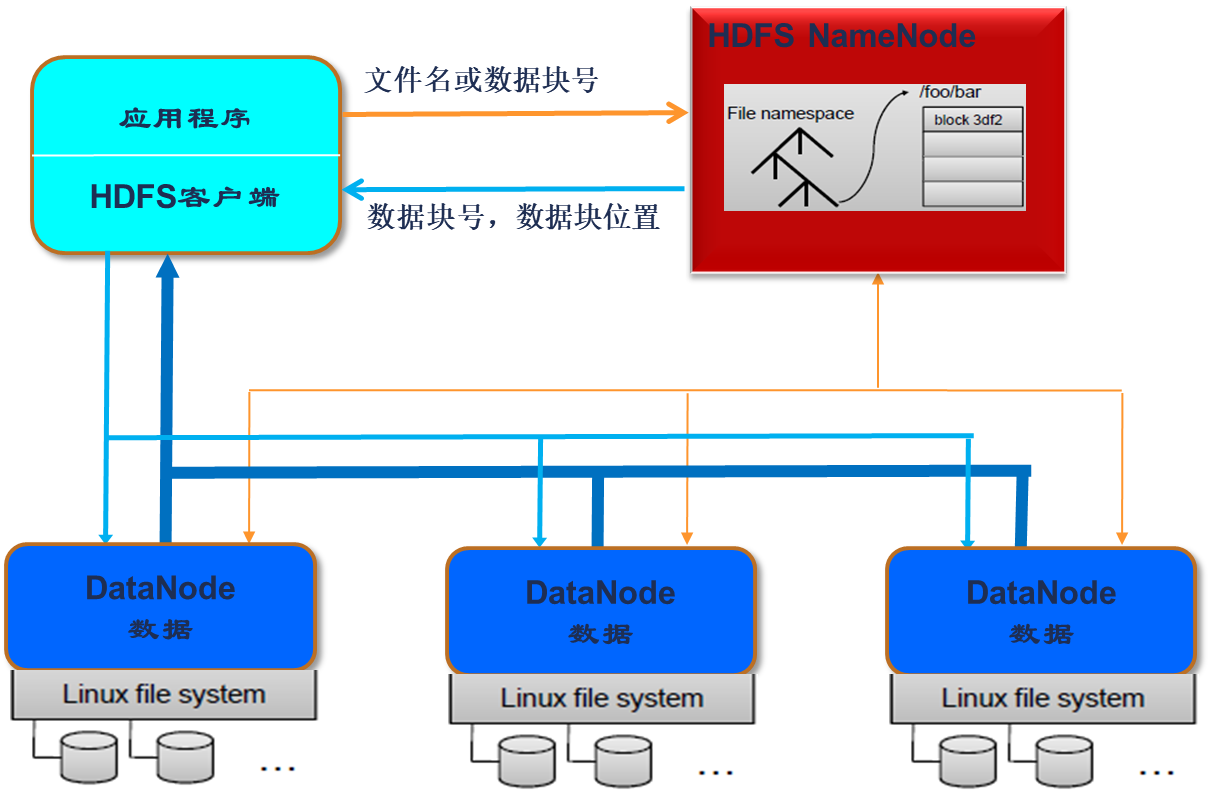
HDFS 是不能直接访问各个datanode 的Linux文件系统的
HDFS 命名空间
- Hadoop 文件命名遵循了传统的 “目录/子目录/文件”格式,通过命令行或者API创建目录,创建、删除文件等
- 命名空间由目录节点管理,对命名空间的变动都会被HDFS记录下来
HDFS 存储策略
副本数据
- 文件分成固定大小的块,每个数据块都冗余存储
- 数据节点定期发送心跳信号和数据列表给目录节点,心跳信号使目录节点直到该数据节点还是有效的。而数据块列表包括了该数据节点上面所有数据块的编号
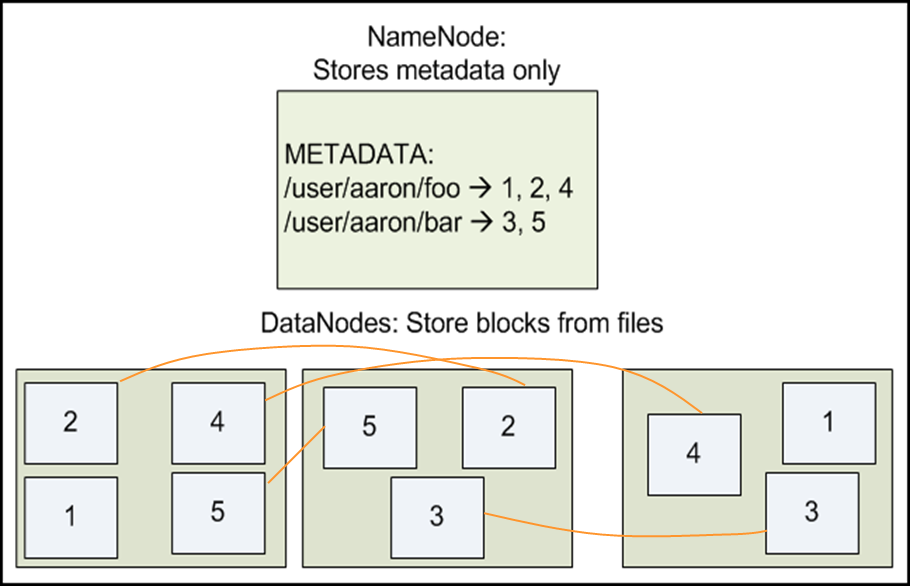
数据存取策略
数据存放
- hadoop采用以机柜为基础的数据存放策略,提高数据可靠性和充分利用网络带宽
- 默认副本因子是3,一块数据有3个地方存放,两份在同一个rack id的不同机器上,一份放在不同rack id的机器上。也就是说 2/3数据在同一个机柜的不同机器上,1/3在另一个机柜
- 计科一进行数据恢复,又能提高读写性能
数据读取
- 读取数据时,如果又块数据和客户端的机柜id一样,优先选择该数据节点,客户端直接和数据节点建立连接,读取数据
- 如果没有,可以随机选择数据节点
数据复制
- 采用流水线复制策略
当客户端要在HDFS上写一个文件:
- 首先将这个文件写在本地
- 对文件进行分块,64M一块
- 每个数据块都对HDFS目录节点发起写请求
- 目录节点选择一个数据节点列表(副本位置),返回给客户端
- 客户端把数据写入第一台数据节点,并把列表传给数据节点
- 当数据节点收到4KB数据时,写入本地,并发起连接到下一个数据节点,把4K传过去,形成一条流水线
- 最后当文件写完的时候,数据复制也同时完成
HDFS通讯协议
- HDFS通讯协议在TCP/IP基础上开发
- 客户端使用Client协议和目录节点通讯
- 目录节点和数据节点使用Datanode协议
- 客户端和数据节点的交互通过远程过程调用(RPC,Remote Rocedure Call)
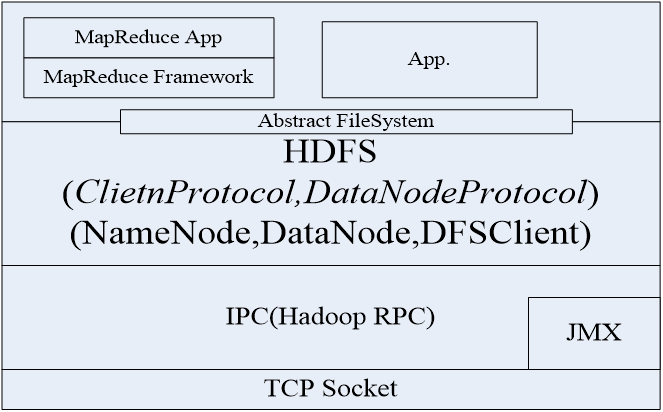
HDFS可靠性设计
- HDFS要在应产出措施保证目标可靠




分布式文件系统的设计需求
- 透明性
- 并发控制
- 客户端对文件的读写不应该影响其他客户端对通过一个文件的读写
- HDFS机制非常简单,任何时间都只允许一个写的客户端,问肩颈创建并写入之后不再改变,一次写多次读。
-
文件复制功能:HDFS 默认有3个副本
-
硬件和操作系统的异构性:HDFS由JAVA实现,可以在不同操作系统和计算机上实现相同的客户端和服务成序
-
容错能力:心跳检测,检测文件快的完整性,集群负载均衡,为何多个Fslmage 和 Editlog 的拷贝
-
安全性问题:HDFS安全性弱,只有文件续可控制
HDFS基本特征
- 顺序式文件访问:HDFS对数虚度写作了忧患,执行大量数据的顺序读出,对于随机访问的负载较高
- 简单的一致性模型(一次写入多次读)支持在文件尾部添加新的数据
- 数据库存储模式: 基于块的文件存储,多副本数据块形式存储

















 4029
4029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









