




 本文深入探讨了数组这一基本数据结构,详细阐述了其底层原理,包括内存的连续性及相同类型数据的存储。讨论了ArrayList的操作,如查询与修改的时间复杂度为O(1),而插入和删除在最坏情况下的时间复杂度为O(n)。此外,还介绍了适用场景,强调了数组在查询和修改上的高效性,但插入和删除的低效。
本文深入探讨了数组这一基本数据结构,详细阐述了其底层原理,包括内存的连续性及相同类型数据的存储。讨论了ArrayList的操作,如查询与修改的时间复杂度为O(1),而插入和删除在最坏情况下的时间复杂度为O(n)。此外,还介绍了适用场景,强调了数组在查询和修改上的高效性,但插入和删除的低效。
| 主文章(数据结构的索引目录—进不去就说明我还没写完) |
|---|
| https://blog.youkuaiyun.com/grd_java/article/details/122377505 |
| 模拟数据结构的网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html |
|---|
| 源码(码云):https://gitee.com/yin_zhipeng/data_structures_and_algorithms_in_java.git |
|---|
| 数组 |
|---|
- 一种线性数据结构,内存地址连续
- 由于java无法直接操作内存,但是我们需要理解数组的底层原理
| 面试点,ArrayList |
|---|
- 面试常问ArrayList,说明它的优势和缺点,我们可能都知道,它查询修改快,插入删除慢,为什么呢?
- ArrayList底层就是数组,所以下面介绍的原理,操作,优缺点,都是ArrayList的特点
1. 数组底层原理(Basic principles of Array)
| 1. 数组用一组连续内存空间,存储一组具有相同类型的数据 |
|---|
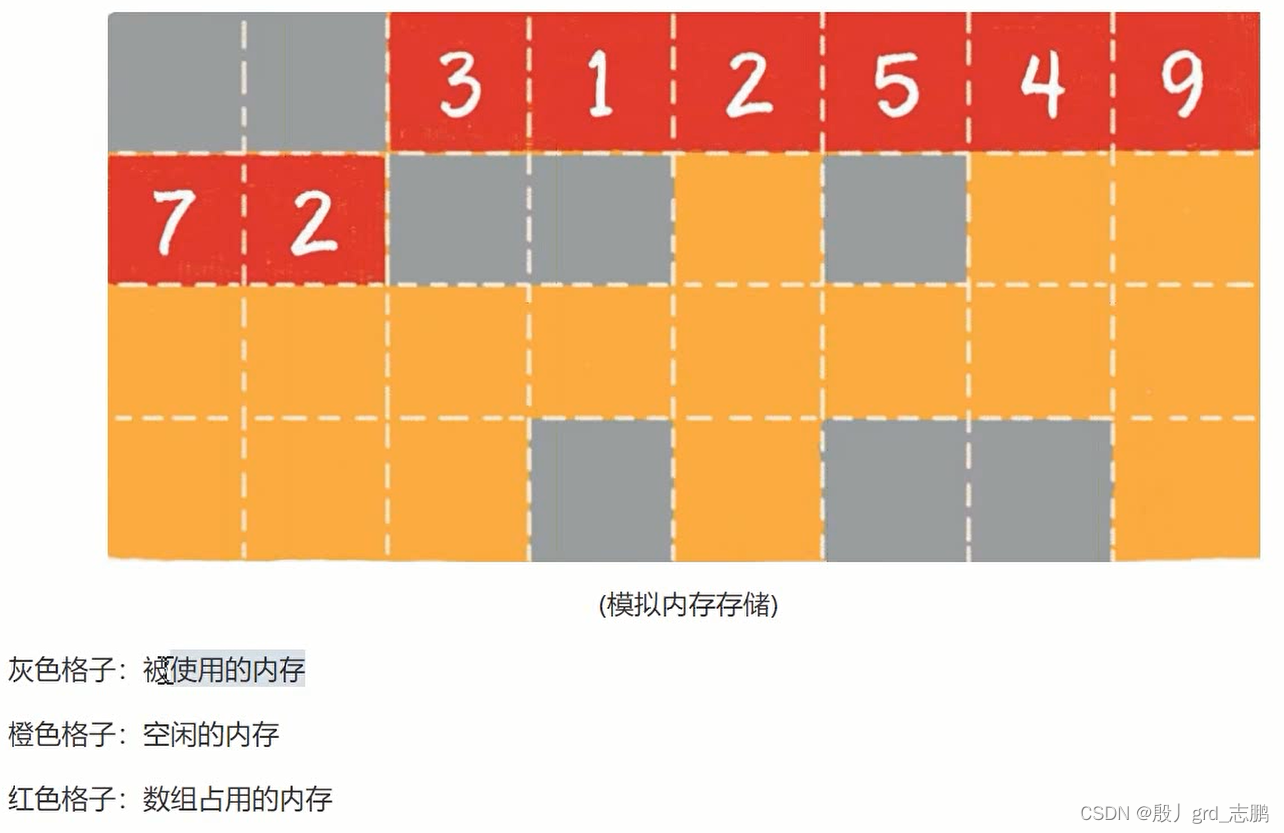
- 一组连续内存空间
- 假设上图为内存区,那么必须保证红色格子连续,中间不能有灰色或橙色的格子
- 假设最后一个红色格子2,是灰色的格子。那么数组的内存区域不能放在这里,而是整个向下用第三行的橙色格子。必须保证内存空间连续
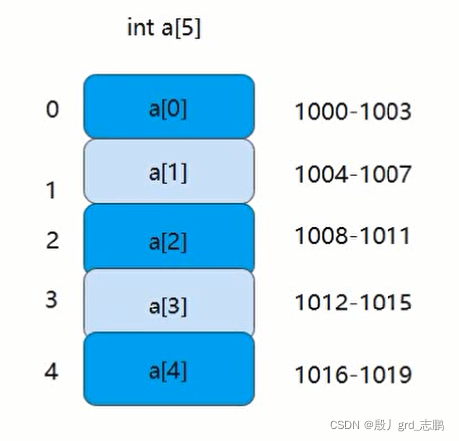
- 存储一组相同类型数据,假设int a[] = new int[5];起始空间为1000, int类型占4字节,那么内存空间如下分配
- 实际上内存存储的是位,int 4字节 = 32位
| 如何寻址 |
|---|
- 我们知道内存空间是连续的,并且每个数组元素分配的空间,和存储数据类型有关,所以,寻址时,通过首地址1000,向后推算即可
- 随机元素寻址
a[i]_address=a[0]_address+(i*4)
- 所以,下标从0开始
- 连续性分配
- 数组元素类型相同
2. 操作原理,时间复杂度
| 读取和更新 |
|---|
- int n = arr[2]; 操作原理为,首地址1000+2*4 = 1008,直接获取1008地址数据
- arr[2] = 10; 操作原理为,首地址1000+2*4 = 1008,直接将1008地址数据,修改为10
- 因此,时间复杂度都是O(1)
| 插入元素 |
|---|
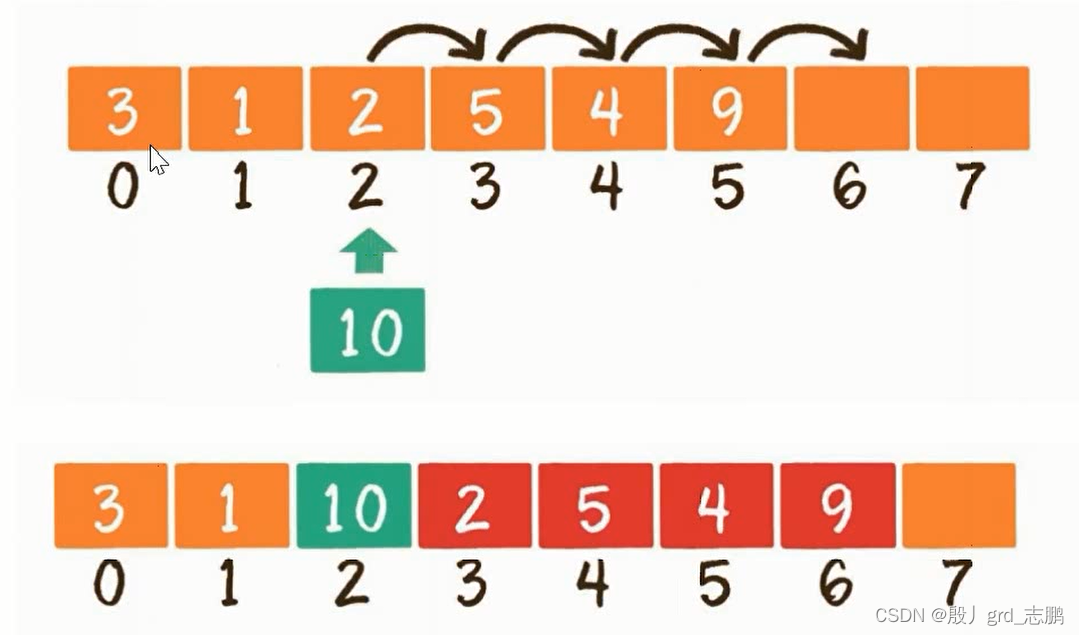
- 尾部插入,数据实际元素数量小于数组长度情况下,直接把插入元素放在数组末尾空闲位置,等同于更新元素操作。例如arr[6] = 8;,时间复杂度O(1)
- 中间插入,数据实际元素数量小于数组长度,数组每一元素都有固定下标,需要把插入位置和后面元素后移,再把插入元素放在对应位置上,时间复杂度O(n)
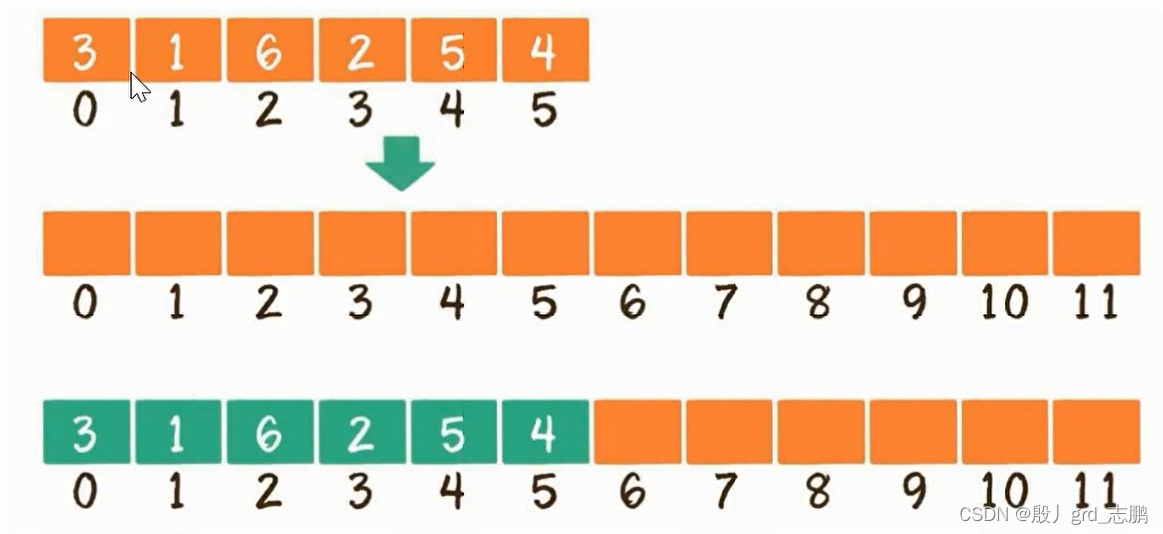
- 超范围插入,当前数组已满,还想插入,需要进行数组扩容,例如创建新数组,长度是原来2倍,再把旧数组元素复制过去

| 删除 |
|---|
- 和插入正好相反,如果删除中间的,后面的元素需要前挪
- 一般考虑效率,会采用标记算法,标记要删除的,一次性批量删除,然后往前挪。而不是一个个删除,每删一个,往前挪一次。时间复杂度O(n)
| 时间复杂度只考虑最坏情况 |
|---|
- 所以按最坏情况考虑,插入和删除,都需要涉及元素移动,时间时间复杂度是O(n)
- 而查询和修改,时间复杂度都是O(1)
| 适用场景 |
|---|
- 因此,数组这种数据结构,查询和修改效率高
- 插入和删除效率低


















 1843
1843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











