



YOLOv8 相关环境安装
使用 conda 创建虚拟环境,然后安装 ultralytics 相关环境,测试下 yolo 命令,主要是为后面使用 airockchip/ultralytics_yolov8 导出模型创建环境。也可以直接跳到后面模型导出小结,拉取airockchip/ultralytics_yolov8,然后根据 requirements.txt 安装环境。
# 使用 conda 创建虚拟环境
conda create -n yolov8 python=3.8
conda activate yolov8# 安装 pytorch 等等
# 安装 YOLOv8 ,直接使用命令安装
pip install ultralytics -i https://mirror.baidu.com/pypi/simple# 或者通过拉取仓库然后安装
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e .
# 安装成功后,使用命令 yolo 简单看下版本
(yolov8) llh@anhao:/$ yolo version
8.0.206
安装之后,就可以直接使用 yolo 命令 或者编写 python 程序 进行模型训练等等操作。
TACO 数据集
TACO 是一个包含在不同环境下(室内、树林、道路和海滩)拍摄的垃圾图像数据集,这些图像中的垃圾对象被精细地用方框和多边形进行了标注,标注信息采用与 COCO 数据集一样的格式,总共有 60 个类别,不过有的类别标注得很少甚至没有(建议训练数据集可以减少类别)。
下载数据集:
git clone https://github.com/pedropro/TACO.git
cd TACO# 运行脚本下载图像数据,默认下载官方数据集( annotations.json )是 1500 张,也可以指定下
载非官方的数据( annotations_unofficial.json )
python3 download.py
下载失败可以重新运行命令,如果还是下载失败,也可以到配套例程网盘下载数据集,然后解压到 TACO/data 目录下。
TACO 数据集中有很多程序,可以查看数据集的相关信息:
列表 1: example/garbage_detection/taco/dataset_info.py
# 参考 demo.ipynb ,查看官方数据集整体信息
import json
import numpy as np
dataset_path = './data'
anns_file_path = dataset_path + '/' + 'annotations.json'
# Read annotations
with open(anns_file_path, 'r') as f:
dataset = json.loads(f.read())
categories = dataset['categories']anns = dataset['annotations']
imgs = dataset['images']
nr_cats = len(categories)
nr_annotations = len(anns)
nr_images = len(imgs)
# Load categories and super categories
cat_names = []
super_cat_names = []
super_cat_ids = {}
super_cat_last_name = ''
nr_super_cats = 0
for cat_it in categories:
cat_names.append(cat_it['name'])
super_cat_name = cat_it['supercategory']
# Adding new supercat
if super_cat_name != super_cat_last_name:
super_cat_names.append(super_cat_name)
super_cat_ids[super_cat_name] = nr_super_cats
super_cat_last_name = super_cat_name
nr_super_cats += 1
print('Number of super categories:', nr_super_cats)
print('Number of categories:', nr_cats)
print('Number of annotations:', nr_annotations)
print('Number of images:', nr_images)
python data.py
# 运行程序输出
Number of super categories: 28
Number of categories: 60Number of annotations: 4784
Number of images: 1500
官方数据集总共 1500 张图像,有 60 个类别,4784 个标注。
数据集处理
TACO 数据集标注信息和 COCO 格式一样,我们将使用 COCO 数据集的 API 来处理 TACO 数据集,将数据集划分。要使用 Yolov8-seg 训练,还需要并将其转换成 yolo 格式。利用 TACO 仓库提供的 detector/split_dataset.py,我们将 TACO 数据集的标注信息 annotations.json划分成三份 train, val, test,生成对应的 json 文件。
# 在 TACO 工程目录下执行 detector/split_dataset.py 划分数据集 ,--dataset_dir 指定
json 路径, --test_percentage 设置测试集
# --val_percentage 设置验证集, --nr_trials 设置份数
python detector/split_dataset.py --dataset_dir ./data --test_percentage 5 --val_percentage 10 --nr_trials 1
将在 data 目录下生成 annotations_0_train.json,annotations_0_val.json,annotations_0_test.json 三个文件,并且划分测试集占 5%,评估数据占 10%,剩下的是训练集数据。
yolo 的数据集分为一个图像目录和一个标签目录,一幅图像的所有标注信息放在一个与图像同名的 txt 文件中,YOLOv8 分割模型训的标注格式如下:
<id> <x_1> <y_1> ... <x_n> <y_n>
一个对象的标注信息放在一行,一行的开始是类别 id,之后是接着将多边形各点像素坐标的 x 和y 值依次排列,而且 x 和 y 的值需要分别除以图像的宽度和高度进行归一化。具体的形式,可以参考 yolov8-seg 测试数据 COCO8-Seg 数据集 。
使用配套例程的程序,读取前面将划分的数据集的 json 文件,然后转换成 yolo 数据集要求的格
式:
from pycocotools.coco import COCO
import numpy as np
import tqdm
import argparse
import shutil
import os
if __name__ == '__main__':
parser = argparse.ArgumentParser('code by cb')
parser.add_argument('--annotation_path', type=str,
default='./data/annotations_0_val.json')
# 生成的txt文件保存的目录
parser.add_argument('--subset', type=str, default='test')
parser.add_argument('--save_path', type=str, default='./data/')
args = parser.parse_args()annotation_path = args.annotation_path
subset = args.subset
save_path = args.save_path
yolo_label_path = "./data/label/{}".format(subset)
yolo_image_path = "./data/image/{}".format(subset)
print(f'label_path: {yolo_label_path}')
print(f'image_path: {yolo_image_path}')data_source = COCO(annotation_file=annotation_path)
catIds = data_source.getCatIds()
categories = data_source.loadCats(catIds)
categories.sort(key=lambda x: x['id'])# 保存类别
class_path = args.save_path + 'classes.txt'
with open(class_path, "w") as file:
for item in categories:
file.write(f"{item['id']}: {item['name']}\n")# 遍历每张图片
img_ids = data_source.getImgIds()
for index, img_id in tqdm.tqdm(enumerate(img_ids)):
img_info = data_source.loadImgs(img_id)[0]
file_name = img_info['file_name'].replace('/', '_')
save_name = file_name.split('.')[0]
height = img_info['height']
width = img_info['width']
save_label_path = yolo_label_path + '/' + save_name + '.txt'
with open(save_label_path, mode='w') as fp:
annotation_id = data_source.getAnnIds(img_id)
if len(annotation_id) == 0:
print("1111111111111111111111111111111111111111")
fp.write('')
shutil.copy('data/{}'.format(img_info['file_name']), os.path.join(yolo_image_path, file_name))
continue
annotations = data_source.loadAnns(annotation_id)
for annotation in annotations:
category_id = annotation["category_id"]
seg_labels = []
for segmentation in annotation["segmentation"]:
points = np.array(segmentation).reshape((int(len(segmentation) / 2), 2))
for point in points:
x = point[0] / width
y = point[1] / height
seg_labels.append(x)
seg_labels.append(y)
fp.write(str(category_id) + " " + " ".join([str(a) for a in seg_labels]) + "\n")
shutil.copy('data/{}'.format(img_info['file_name']), os.path.join(yolo_image_path, file_name))
在 TACO 工程目录下执行程序:
# 测试集数据,运行程序将生成 label 文件和复制图像到对应目录下,转换为 YOLO 格式
python taco2yolo.py --annotation_path ./data/annotations_0_test.json --subset test
# 评估集
python taco2yolo.py --annotation_path ./data/annotations_0_val.json --subset val
# 训练集python taco2yolo.py --annotation_path ./data/annotations_0_train.json --subset train
程序会将 TACO 数据图像复制到指定的目录,并在对应目录下生成对应的标签文件以及类别和名称文件
YOLOv8 目标检测
目标检测简单测试
简单测试下环境,先从官网获取需要的权重文件(也可以不下载,使用 yolo 命令指定官方预训练权重时会自动下载),然后使用模型进行预测。
# 创建一个目录,然后获取官方仓库的权重( https://github.com/ultralytics/ultralytics/tree/main ),
# 或者不手动下载,后面使用 yolo 命令会自动下载。
wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt
# 获取测试图片,可以下面位置获取,可能会失败,也可以从配套例程获取
wget https://ultralytics.com/images/bus.jpg
然后使用 yolo 命令进行测试:
# 第一个参数是指任务 [detect, segment, classify], 这里测试目标检测是 detect ,该参数
是可选的;
# 第二个参数是模式 [train, val, predict, export, track)] ,是选择进行训练、评估或者
推理等等;
# 其他参数, model 设置模型, source 指定要预测的图片路径, imgsz 指定图像尺寸等等,更多参
数具体参考下: https://docs.ultralytics.com/usage/cfg/
# 简单目标检测
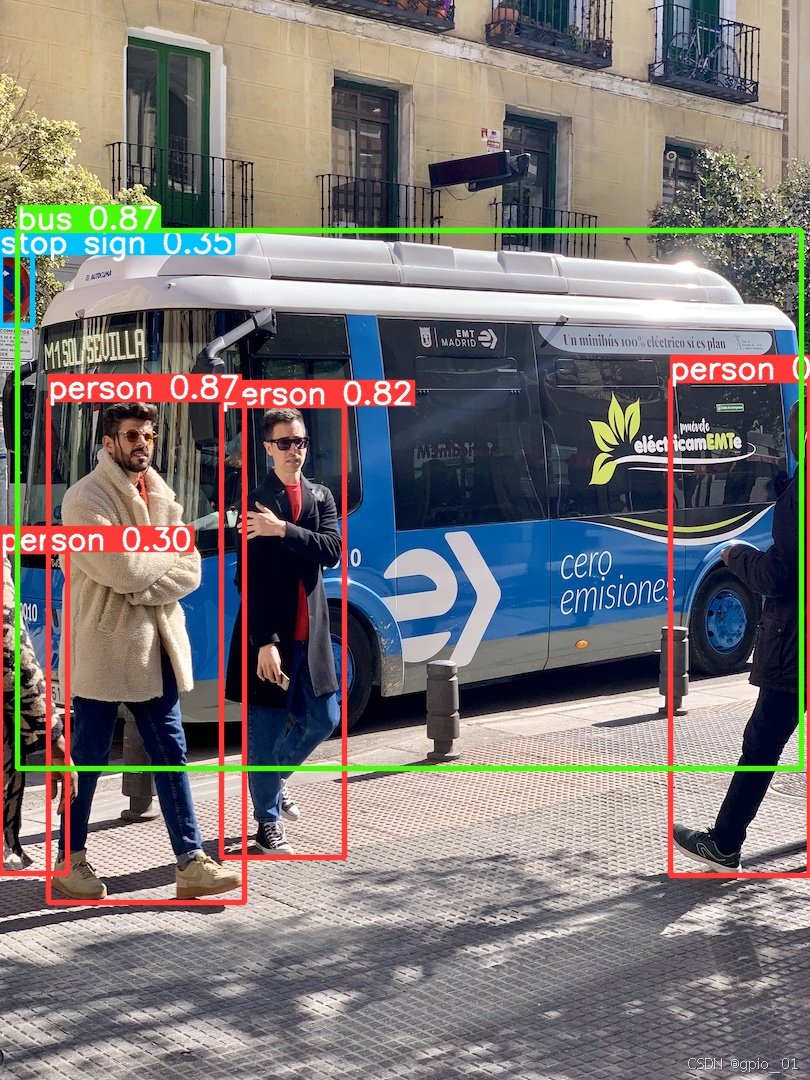
(yolov8) llh@anhao: yolo detect predict model=./yolov8n.pt source=./bus.jpg
Ultralytics YOLOv8.0.206 ? Python-3.8.18 torch-2.1.0+cu121 CUDA:0 (NVIDIA GeForce RTX 3060 Laptop GPU, 6144MiB)
YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPsimage 1/1 /yolov8/bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 81.8ms
Speed: 2.9ms preprocess, 81.8ms inference, 3.3ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs/detect/predict
Learn more at https://docs.ultralytics.com/modes/predict
# 预测图片结果保存在当前 runs 目录下,具体路径是 ./runs/detect/predict/bus.jpg
测试结果:
模型训练
Yolov8 训练模型,需要创建一份数据集配置文件和一个模型配置文件。
复制 ultralytics/cfg/datasets/coco8-seg.yaml 修改一份数据集配置文件,名称为 taco-seg.yaml,内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license # COCO128 dataset https://www.kaggle.com/datasets/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics # Documentation: https://docs.ultralytics.com/datasets/detect/coco/ # Example usage: yolo train data=coco128.yaml # parent # ├── ultralytics # └── datasets # └── coco128 ← downloads here (7 MB) # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] path: taco # dataset root dir train: images/train # train images (relative to 'path') 128 images val: images/val # val images (relative to 'path') 128 images test: images/test # test images (optional) # Classes names: 0: Aluminium foil 1: Battery 2: Aluminium blister pack 3: Carded blister pack 4: Other plastic bottle 5: Clear plastic bottle 6: Glass bottle 7: Plastic bottle cap 8: Metal bottle cap 9: Broken glass 10: Food Can 11: Aerosol 12: Drink can 13: Toilet tube 14: Other carton 15: Egg carton 16: Drink carton 17: Corrugated carton 18: Meal carton 19: Pizza box 20: Paper cup 21: Disposable plastic cup 22: Foam cup 23: Glass cup 24: Other plastic cup 25: Food waste 26: Glass jar 27: Plastic lid 28: Metal lid 29: Other plastic 30: Magazine paper 31: Tissues 32: Wrapping paper 33: Normal paper 34: Paper bag 35: Plastified paper bag 36: Plastic film 37: Six pack rings 38: Garbage bag 39: Other plastic wrapper 40: Single-use carrier bag 41: Polypropylene bag 42: Crisp packet 43: Spread tub 44: Tupperware 45: Disposable food container 46: Foam food container 47: Other plastic container 48: Plastic glooves 49: Plastic utensils 50: Pop tab 51: Rope & strings 52: Scrap metal 53: Shoe 54: Squeezable tube 55: Plastic straw 56: Paper straw 57: Styrofoam piece 58: Unlabeled litter 59: Cigarette # Download script/URL (optional) #download: https://github.com/ultralytics/assets/releases/download/v0.0.0/coco128.zip
需要根据实际的数据集存放目录修改,类别 id 和类别名称复制前面数据集处理生成的 classes.txt
文件。
复制一份 ultralytics/cfg/models/v8/yolov8-seg.yaml, 然后修改模型配置文件,名称为 yolov8n-seg-
taco.yaml(将默认使用 n 尺寸的模型),如果将名称改成 yolov8s-seg-taco.yaml 将会使用 s 尺寸
大小的模型。
# Ultralytics YOLO 🚀, AGPL-3.0 license # YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment # Parameters nc: 60 # number of classes scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n' # [depth, width, max_channels] n: [0.33, 0.25, 1024] s: [0.33, 0.50, 1024] m: [0.67, 0.75, 768] l: [1.00, 1.00, 512] x: [1.00, 1.25, 512] # YOLOv8.0n backbone backbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 3, C2f, [128, True]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 6, C2f, [256, True]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 6, C2f, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 3, C2f, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 # YOLOv8.0n head head: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 3, C2f, [512]] # 12 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 3, C2f, [256]] # 15 (P3/8-small) - [-1, 1, Conv, [256, 3, 2]] - [[-1, 12], 1, Concat, [1]] # cat head P4 - [-1, 3, C2f, [512]] # 18 (P4/16-medium) - [-1, 1, Conv, [512, 3, 2]] - [[-1, 9], 1, Concat, [1]] # cat head P5 - [-1, 3, C2f, [1024]] # 21 (P5/32-large) - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
模型训练可以使用命令,或者 python 程序,教程测试使用 yolo 命令。将前面修改的配置文件放
到同一个目录下,在 yolov8 环境下,然后执行下面命令:
# 第一个参数是指任务 [detect, segment, classify], 这里测试目标检测是 detect ,该参数
是可选的;
# 第二个参数是模式 [train, val, predict, export, track)] ,是选择进行训练、评估或者
推理等等;
# 其他参数 data 指定数据集配置文件, model 指定修改的模型配置文件路径
(yolov8) xxx$ yolo segment train data=taco-seg.yaml model=yolov8n-seg-taco. yaml epochs=100 batch=16 imgsz=640
以上只是简单训练了一个 yolov8n-seg 模型,训练输出文件保存在 runs/segment/train 目录下,最终模型保存在 runs/segment/train/weights/best.pt。
对训练的模型进行评估:
(yolov8) xxx$ yolo segment val model=xxx/runs/segment/train/weights/last.pt
输出文件保存在 runs/segment/val 下,以上训练的模型效果和精度较差,可以测试修改训练策略、添加和优化数据集训练、使用其他尺寸的模型训练等等。
模型转换(*.pt->*.onnx->*.rknn)
经过训练的 yolov8n-seg 模型,要在鲁班猫板卡上推理部署,还行需要进行一些优化修改,我们
使用 airockchip/ultralytics_yolov8 仓库程序导出适合部署到 rknpu 上的模型。
拉取仓库程序:
# 在当前目录下,拉取 airockchip/ultralytics_yolov8 , main 分支
git clone https://github.com/airockchip/ultralytics_yolov8.git
cd ultralytics_yolov8
修改 ultralytics/cfg/default.yaml 文件:
# 修改 ultralytics/cfg/default.yaml 中 model 文件路径,可以修改为前面训练出的模型
# Train settings -------------------------------------------------------------------------------------------------------
model: xxxxx/runs/segment/train/weights/best.pt # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: # (str, optional) path to data file, i.e. coco128.yaml
epochs: 100 # (int) number of epochs to train for
执行程序,导出 onnx 模型:
# 执行 python ./ultralytics/engine/exporter.py 导出模型
(yolov8) llh@anhao:~/ultralytics_yolov8$ export PYTHONPATH=./
(yolov8) llh@anhao:~/ultralytics_yolov8$ python ultralytics/engine/exporter.py
Ultralytics YOLOv8.0.151 ? Python-3.8.18 torch-2.1.0+cu121 CPU ()
YOLOv8n-seg-taco summary (fused): 195 layers, 3269764 parameters, 0 gradients, 12.0 GFLOPs
导出的 onnx 模型保存在 best.pt 模型路径下,名称为 best.onnx,使用 Netron 查看下该模型的输出.
onnx->*.rknn可通过rknn_model_zoo(ubuntu)进行转换
cd rknn_model_zoo/examples/yolov8_seg/python
python convert.py best.onnx rk3588 i8 best.rknn
#生成例子
将生成的best.rknn拷贝到rknn_model_zoo/examples/yolov8_seg/model
cd rknn_model_zoo
./build-linux.sh -t rk3588 -a aarch64 -d yolov8_seg
在knn_model_zoo/install/rk3588_linux_aarch64/rknn_yolov8_seg_demo会生成板子运行的例子拷贝到板子就可以进行测试了


















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









