 使用Greenplum与pgvector及OpenAI构建大规模AI搜索引擎
使用Greenplum与pgvector及OpenAI构建大规模AI搜索引擎





 本文介绍了如何在Greenplum中利用pgvector扩展存储和查询向量嵌入,结合OpenAI实现大规模的AI搜索引擎。通过嵌入技术,可以进行高效相似性搜索,创建个性化推荐系统。文章还展示了如何构建一个基于产品文档的AI助手,利用GPT进行智能回答。
本文介绍了如何在Greenplum中利用pgvector扩展存储和查询向量嵌入,结合OpenAI实现大规模的AI搜索引擎。通过嵌入技术,可以进行高效相似性搜索,创建个性化推荐系统。文章还展示了如何构建一个基于产品文档的AI助手,利用GPT进行智能回答。

概述
过去一年中,一些先进的 AI 模型如 ChatGPT 在自然语言处理领域取得了显著的突破。这些 AI 模型的飞速发展引起了很多公司和单位的兴趣,他们都希望能够利用生成式 AI 和大型语言模型(LLMs)的潜力来充分挖掘和利用他们的非结构化数据(包括文本、图 像和视频)。通过将这些先进的技术整合到他们的业务流程中,他们可以实现更高级别的自动化、智能化的处理,提高工作效率,发现隐藏在数据中的洞察力,并为用户提供更优质的产品和服务。 Greenplum 是一个强大的关系型数据库管理系统,专为处理大规模数据集而设计。它的MPP (Massively Parallel Processing) 架构使其能够同时处理大量数据,并具有出色的性能和可伸缩性。pgvector 是 Greenplum 的一个扩展,它提供了向量数据类型和高性能的向量操作功能。借助 pgvector 的向量相似性搜索功能,我们可以在大规模文本数据中快速找到与查询向量最相似的文档或数据点。这使得我们能够进行高效的语义搜索、相似性匹配和聚类分析等任务。 同时,Greenplum 还可以结合 OpenAI 模型的能力,将文本数据转化为向量表示。OpenAI 的模型如 GPT 可以理解文本的语义和上下文,并生成高质量的文本表示。通过将这些向量表示存储在 Greenplum 中,并利用 pgvector 的向量操作功能,我们可以在 Greenplum 数据仓库中进行高效的向量相似性搜索。结合 Greenplum pgvector 和 OpenAI 模型的优势,我们可以在 Greenplum 的大规模数据集中提取有价值的发现。无论是通过相似性搜索找到相关文档,还是通过聚类分析发现文本数据的模式和趋势,我们可以利用这些技术来揭示数据中的隐藏信息,并支持决策和创新。 在本文中,您将学习如何利用 Greenplum 数据仓库中的 pgvector 扩展的向量相似性搜索功能,以及如何与 OpenAI 模型进行结合,并充分利用 Greenplum 强大的 MPP 架构,从而在 Petabytes 级的大规模文本数据中提取有价值的知识和发现。 
什么是嵌入(embeddings)
嵌入(Embeddings)是指将数据或复杂对象(如文本、图像或音频)转换为高维空间中的向量。 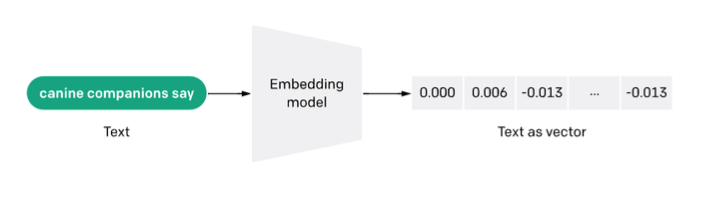
嵌入技术在许多机器学习(ML)和深度学习(DL)算法中被广泛应用,它能够捕捉/理解数据的含义和上下文(语义关系),以及对数据中复杂关系和模式的掌握(句法关系)。
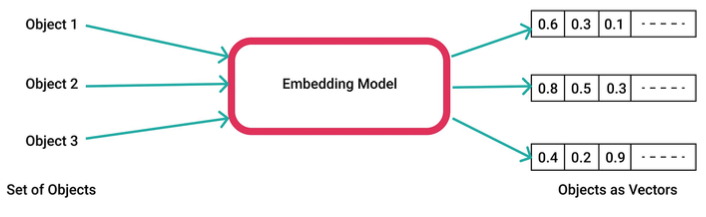
您可以将生成的向量表示用于各种应用,例如信息检索、图像分类、自然语言处理等。
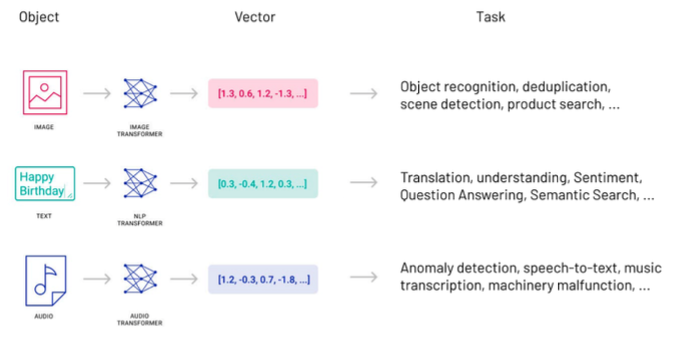
来源: https://dev.to/josethz00/vector-databases-5df
下面的图表以二维空间直观地展示了词嵌入的情况。
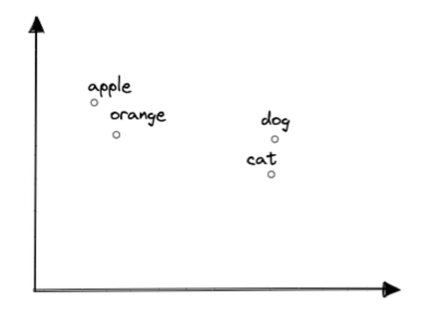
来源: https://neon.tech/blog/building-an-ai-powered-chatbot-using-vercel-openai-and-postgres
您可以注意到,在嵌入空间中,语义相似的单词彼此靠近。例如,"apple"(苹果)这个词 与"orange"(橙子)比与"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









