 Greenplum峰会:联邦分析与数据融合实战
Greenplum峰会:联邦分析与数据融合实战




了解更多Greenplum相关内容,欢迎访问Greenplum中文社区网站
Greenplum峰会精彩继续
Greenplum峰会精彩仍在继续,因为时差无法观看直播的小伙伴可以在VMware学习专区(http://vmwarelearningzone.vmware.com/)观看活动视频。第二周的专题内容是“联邦分析”。联邦分析可以满足用户对来自多个数据源的分析的需求,帮助用户解决业务挑战。让本文带你回顾一下峰会第二周主题的精华内容吧!
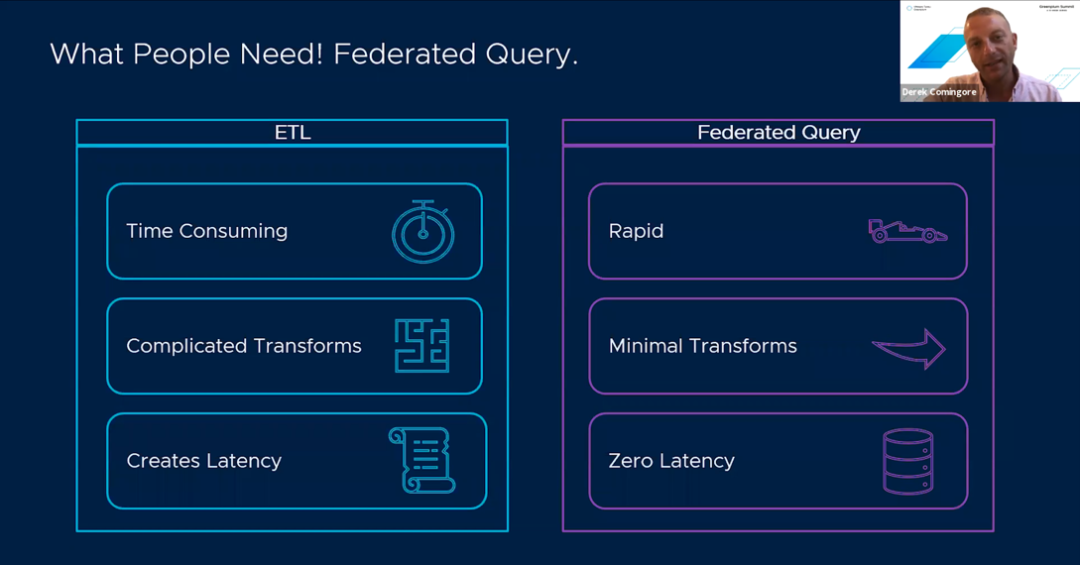
1. 有的时候你需要使用标准ETL加载数据,有的时候轻量级的数据集成可以更加灵活的操作和查询外部系统中的数据
第二周的第一个主题中,Derek Comingore介绍了Greenplum处理外部数据的不同方式:
-
标准 ETL…使用所有Greenplum segment节点来进行并行读取操作
-
流式接收…使用Greenplum Stream Server并行订阅多个Kafka主题
-
Spark集****成…Greenplum segment和Spark执行程序之间的JDBC或HTTP连接
-
联合查询…用于提取部分数据集而不是完整的ETL操作
这种灵活性使查询位于数据湖中的冷数据成为可能。 此外,你可以集成其他类型的数据(例如交易数据)以进行交互式查询和即席查询。 这样,你不再需要依靠更大的批处理操作来进行数据移动。
在演讲的最后,Derek用一组示例查询,展示了使用简单的SQL语句访问外部系统中的数据是非常方便和容易的。这些示例说明了Greenplum对数据联邦已经有了良好的支持。
2. 联邦分析释放了分布在外部系统的数据的价值
在Derek的演讲后的第二个主题更深入地讲解了联邦查询的奥秘。将数据加载到数据仓库(ETL)是一个众所周知的过程,然后使用批处理的方式可以很好的生成基础报表时。但是在《PXF:现代企业的查询联合引擎》主题演讲中,Ashuka Xue解释道,标准ETL对于快速查询和分析来自外部数据源的数据来说太慢了。而联邦查询可以让你更方便的获取多个位置的数据(数据湖,对象存储,SQL,NoSQL,私有云,公共云)。Greenplum为联邦查询专门构建了框架PXF。PXF使用数据源专用插件来并行访问各种数据源。
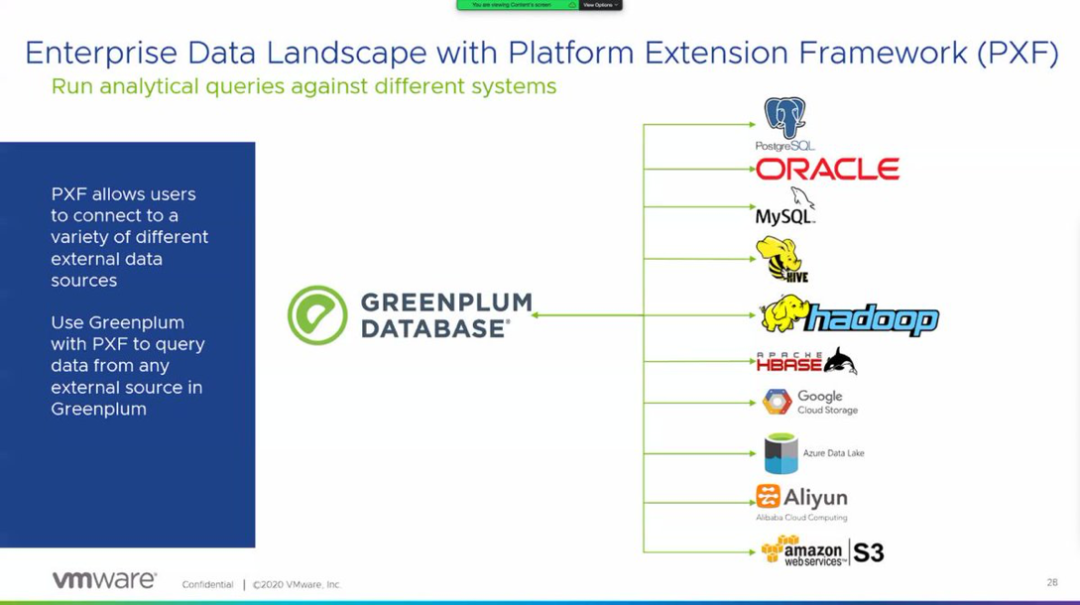
借助PXF,Greenplum可以快速访问和分析各种来源和格式的数据,无需进行转换,且延迟低。这意味着你可以快速组合和分析更多种类的数据,以处理日益复杂的场景,包括图数据分析,文本分析和深度学习。
是什么联邦查询成为可能?在演讲中,Francisco Guerrero解释了Greenplum是如何在整个集群中分配查询,PXF是如何管理并行化的数据读写操作。为了提高性能,PXF具有谓词下推的功能,可过滤远程系统上的查询结果。
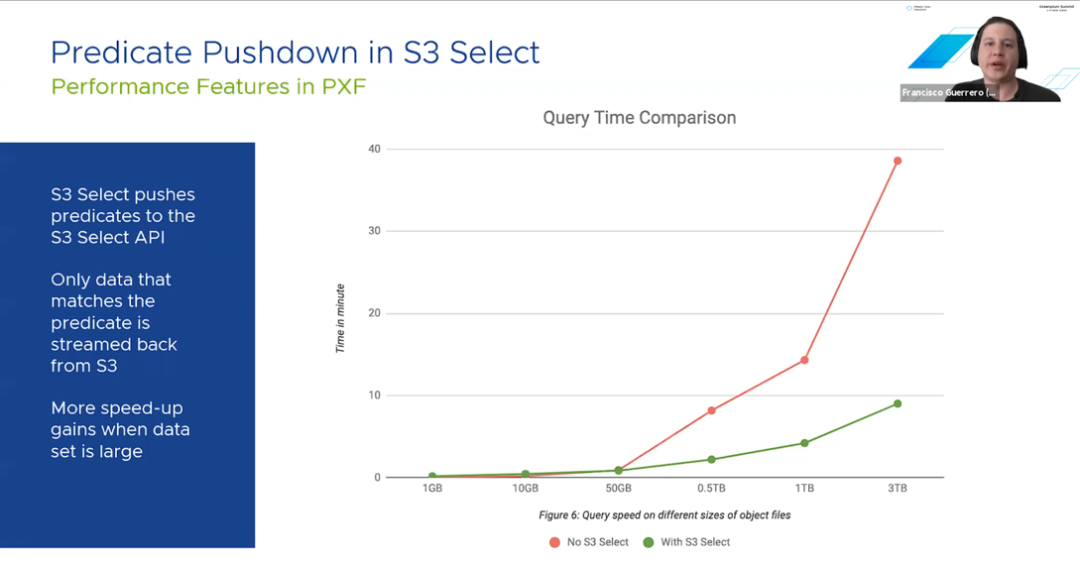
这意味着查询将仅基于过滤后的数据而不是完整的数据集(如通过PXF S3 Select插件返回查询结果)。此外,这些功能均可以从ANSI SQL,Python,R和Java等通用语言进行访问。阅读这篇文章(https://tanzu.vmware.com/content/blog/greenplum-pxf-for-federated-queries-gets-data-quickly-from-diverse-sources)了解详情。
3. Greenplum的联邦查询框架可以与机器学习结合使用,可以在多种场景下为用户提供更好的业务结果
A42 Labs(https://www.a42labs.io/)是美国的一家人工智能和机器学习软件和服务公司,它使用Greenplum进行所有工作,从生成报表和BI到包括基于大数据集的分布式机器学习等复杂应用场景。A42 Labs的数据科学家Michiel Shortt在演讲中讲述了一个案例:金融服务客户希望标记电子邮件中的不合规行为,并进行的审核和审计工作。机器学习对合规性应用的好处之一是使追踪误报的繁琐工作自动化。

Michiel详细解释了他们是如何使用文档数据和元数据提取软件提供软件的Nuix将数据发送到S3,并使用Greenplum的PXF S3插件进行提取。将数据发送到S3可使他们仅在有数据要提取时才运行Greenplum,从而节省了云计算成本。使用Google BERT作为自然语言处理(NLP)工作台,A42能够创建基于NLP的分类系统,该系统可以通过标记误报节省大量成本。通过Greenplum和PXF,使处理文本文件或JSON文档变得非常容易。但是有一些事情要考虑:
-
你必须根据文件是否具有多行,或者多个JSON对象或者一行中是否有断点,从而正确设置查询参数。
-
PXF允许用户限制JSON文件中接受的错误数。但如果你不知道数据是否包含无效的JSON,就会因为这个限制发生处理错误。
-
可以使用PL / Python和Python JSON库验证JSON的有效性,从而避免上述错误。
-
PXF支持将存储和计算分开,以节省运行成本。
如果你想了解更多,欢迎前往链接(https://tanzu.vmware.com/content/blog/making-sense-of-text-analytics-with-pivotal-greenplum-and-the-new-gptext)阅读查看。
4. 需要分析流数据?Greenplum来帮你
Apache NiFi是一种用于自动化企业系统之间的数据流动和数据分发的系统。通过NiFi从源到接收器的数据流的跟踪能力,用户通过参数配置合适的数据丢失率和数据传输延迟。Greenplum开发Greenplum-NiFI连接器与NiFi系统集成。在讲座中,Alexander Denissov向我们介绍了NiFi的体系结构(https://vmwarelearningzone.vmware.com/oltpublish/site/openlearn.do?dispatch=previewLesson&playlistId=7287e94f-d599-11ea-9f48-0cc47adeb5f8&id=49d14b9b-e7cb-11ea-9f48-0cc47adeb5f8),并向用户展示了如何提取数据并通过NiFi数据管道导入到Greenplum Processor中。
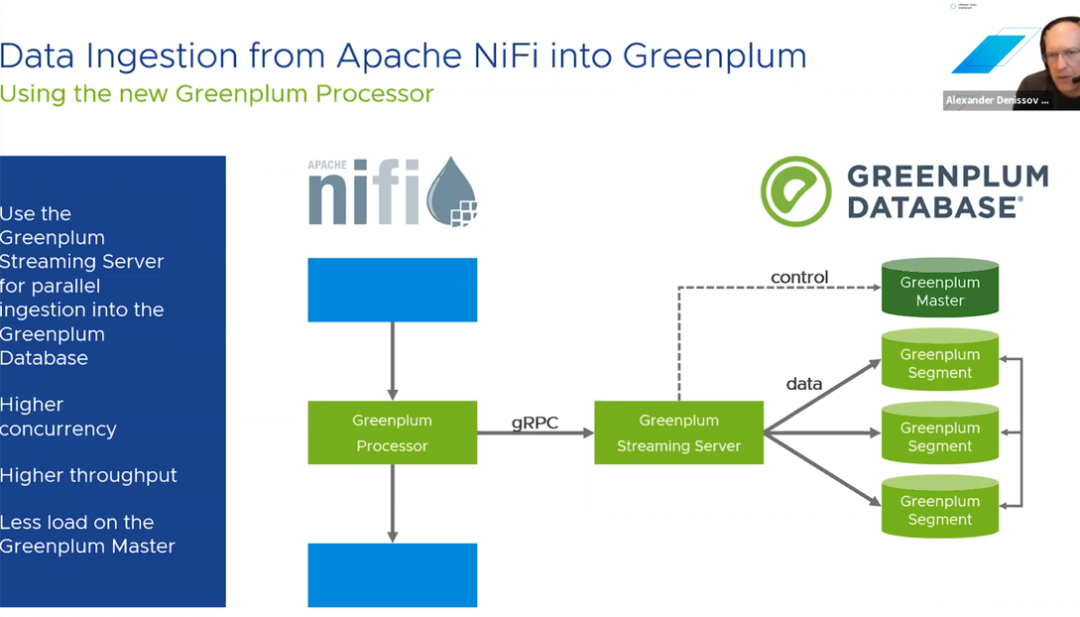
Greenplum Processer与Greenplum Streaming Server一起使用现有的NiFi记录读取器读取多种格式的数据(例如CSV,Avro,Parquet,JSON和XML)并且解析传入的文件并将NiFi记录转换为Greenplum元组。当然,所有这些都利用了Greenplum的大规模并行数据加载功能来实现高吞吐量。这是Greenplum在灵活处理来自各种外部源(包括NiFi和Apache Kafka等流传输系统)的数据的又一个示例。
5. 对于数字媒体巨头Epsilon-Conversant,Greenplum在大规模数据分析上起到了关键作用
峰会的第2周的最后一个主题是Greenplum全球总裁Jacque和Epsilon-Conversant(https://www.conversantmedia.com/)数据仓库副总裁Sean Litt的对话。Conversant是全球最大的数字媒体公司之一。它为客户提供了个性化的广告营销解决方案,广告业务覆盖了数百万人。数字广告平台也必然会产生大量需要快速分析的数据。以下是Sean与社区分享的一些统计信息:
-
Conversant 每天将超过3000亿个广告事件加载到Greenplum中
-
Greenplum中的万亿行表并不少见
-
普通的Greenplum集群每个节点拥有1 PB的原始数据,不久将增加到2 PB。
-
其中一个集群有200个节点
-
有200位分析师在使用Greenplum,一次运行数千个查询。
Conversant有如此大量的数据需要处理和分析!那么,为什么要在基础架构中考虑Greenplum?Sean说,“便捷的工具为Greenplum带来了强大的可扩展性和灵活性,Conversant可以根据业务需求定制化Greenplum集群,以便更好的和业务场景集成”。无论Conversant试图做什么,“ Greenplum永远不会拖后腿。” 通过链接了解有关Conversant的案例的更多详情(https://tanzu.vmware.com/customers/conversant)。
2020 Greenplum 峰会精彩继续!赶紧注册吧!
9月23: AI,神经网络,和分析的未来 (注册链接:https://connect.tanzu.vmware.com/greenplum-summit-september-23)

本文分享自微信公众号 - Greenplum中文社区(GreenplumCommunity)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









