




 本文详细介绍了Greenplum数据库排序算法,包括内排序的快速排序和堆排序,外排序的归并算法,以及Greenplum特有的多键排序。讨论了如何在内存限制下生成大顺串、高效比较最小值和减少IO次数。此外,文章还探讨了排序在Greenplum中的应用,如分组聚集、归并连接、Distinct聚集和Sorted Motion。
本文详细介绍了Greenplum数据库排序算法,包括内排序的快速排序和堆排序,外排序的归并算法,以及Greenplum特有的多键排序。讨论了如何在内存限制下生成大顺串、高效比较最小值和减少IO次数。此外,文章还探讨了排序在Greenplum中的应用,如分组聚集、归并连接、Distinct聚集和Sorted Motion。
了解更多Greenplum技术干货,欢迎访问Greenplum中文社区网站
引言
在《深入浅出Greenplum内核》系列直播的第六场中,Greenplum内核研发张桓为大家详细介绍了Greenplum排序算法,相关视频已上传Greenplum中文社区B站频道。相关PPT请点击链接前往Greenplum中文社区网站(cn.greenplum.org)的下载页面获取。现在让我们通过这篇“万字长文”回顾一下活动精华吧!

排序在数据库执行器中扮演了重要的角色,除了显示的ORDER BY语句,数据库的聚集、窗口函数中都存在排序算法的身影。今天,我们将从4个方面来为大家讲解Greenplum排序算法。
-
内排序算法
-
外排序算法
-
Greenplum排序的底层模块—— TupleSort
-
排序在Greenplum中的应用
一、内排序算法
首先,我们来讲讲内排序算法。相信很多数据库从业者都对内排序算法耳熟能详,比如冒泡排序、插入排序、快速排序、堆排序、基数排序等。Greenplum使用的是快速排序和堆排序,为什么会选择两种排序算法呢?
大家在日常工作中常常遇到一些使用场景需要使用TopK查询,例如当SQL语句中的order by后跟了一个limit的语句时,我们就可以切换到TopK查询,堆排序对于TopK查询的性能会更好。这也是为什么Greenplum在快速排序之外还使用了堆排序的原因。
接下来我们逐一介绍这两种常见的排序算法:
1.快速排序
快速排序是最常用的排序算法,由Tony Hoare在1959年发明。顾名思义,快速排序的特点就是“快”。我们来看一下它是如何实现“快”的。
快速排序算法(简称快排)分为三个步骤:
-
步骤1:挑选基准值;从数列中挑选出一个基准元素,称为pivot;
-
步骤2:分割;重新排序数组,所有比基准元素小的元素排放到基准元素之前;所有比基准元素大的元素排放到基准元素之后。分割完成后,我们就完成了对基准元素的排序,基准元素在数组中的位置将不再改变;
-
步骤3:递归排序子序列;递归地将小于基准元素的子序列和大于基准元素的子序列分别进行排序;
快速排序算法每次选取一个基准元素,把比基准元素小的排到基准元素左边,比基准元素大的排到基准元素的右边,从而将待排序数组分成两个子集。下面我们通过一个例子来展示一下快排的过程。
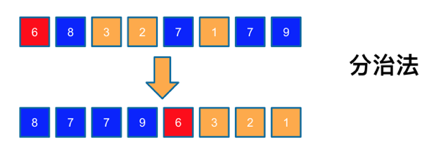
在上图中的例子中,首先我们选取一个基准元素(pivot),假设通过随机选取后,选取的元素是6,我们将所有比6大的元素——8、7、7、9排到6之前,所有比6小的元素——3、2、1都排在6之后,再分别对蓝色和橘色这两个子序列,递归的调用快排算法。
大家可以看到其实快排本质的核心思想是一个“分而治之”的策略。下面是快排的一个伪代码。作为一个递归的算法,代码有两个部分:
-
第一个部分是递归的终止条件:当排序只剩下一个元素的时候,递归终止。
-
第二部分是把问题划分成若干子问题:即前文提到的选取基准元素,划分子序列,在子序列上分而治之,递归调用QuickSort算法的过程。

2.堆排序
Greenplum在排序中对于TopK查询使用的是堆排序。堆排序也是最常用的排序算法之一,由J.Williams在1964年发明。
要理解堆排序,首先我们需要理解什么是堆。堆是一种近似完全二叉树的结构,最大值堆要求每个子节点的键值总是小于父节点。最小值堆相反,要求每个子节点的键值总是大于父节点。
堆排序算法的实际过程分成三步:
-
步骤1:建立最大值堆,最大元素在堆顶;
-
步骤2:重复将堆顶元组移除并插入到排序数组,更新堆使其保持堆的性质;
-
步骤3:当堆的元素个数为零时,数组排序完毕;
下面我们同样通过一个例子来帮助大家理解堆排序。待排序数组是下图中的数组9、5、8、1、3、6、2。首先,我们建立了这样一个堆,保证每一个父节点大于子节点。
接着我们进行排序。我们先移除堆顶元素9,和最后一个元素2进行交换,9就排序好了,而2已经不满足堆的性质,因此我们需要做一个操作,让其满足堆的性质,即将其和8、6进行交换。
然后我们迭代的进行排序,把此时的堆顶元素8移除,和2进行交换。为了让新的数组满足堆的性质,再将2和6进行交换。接着再把堆顶元素6弹出来,重新交换3和5,保持堆的性质…
这样一系列的操作后,最终只剩下一个堆顶元素,最后把堆顶元素弹出,即完
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2542
2542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









