




 本文详细介绍Hadoop伪分布式集群的搭建步骤与配置方法,包括环境准备、软件安装及配置等核心内容,并提供了常见问题解决方案。
本文详细介绍Hadoop伪分布式集群的搭建步骤与配置方法,包括环境准备、软件安装及配置等核心内容,并提供了常见问题解决方案。
hadoop伪分布式集群
概述
伪分布式是指单机条件下,模拟分布式集群运行环境,包括:各种Java守护进程对不同Hadoop节点任务的模拟,和HDFS的交互。
守护进程:NameNode, DataNode, JobTracker, TaskTracker。
用途
适用于本地开发使用,常用来开发测试hadoop程序的执行。
在研究hadoop的过程中,当然需要部署hadoop集群,如果想要在本地简单使用hadoop,但是没有那么多服务器使用,那么伪分布式hadoop环境是最好的选择。
环境搭建
目标:搭建有主从两个节点的伪分布式集群
系统环境
虚拟机安装Ubuntu16.4 64位
系统配置:
- 配置ssh免登录
- 修改主机的名称vi /etc/hostname:
# 修改内容为: master
tancan@master:/usr/soft/hadoop-3.0.3/sbin$ cat /etc/hostname
master- 域名和主机映射对应的关系 vi /etc/hosts:
# 修改内容为: 192.168.0.111 master
tancan@master:/usr/soft/hadoop-3.0.3/sbin$ cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 ubuntu
192.168.0.111 master
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
tancan@master:/usr/soft/hadoop-3.0.3/sbin$ - 安装JDK
过程略。
安装hadoop
安装过程同单机版安装,请参考:
https://blog.youkuaiyun.com/goodmentc/article/details/80821626
但是,配置是不一样的! 具体配置请看后面。
hadoop安装目录:
/usr/soft/hadoop-3.0.3系统环境变量:
tancan@master:/usr/soft/hadoop-3.0.3$ cat /etc/environment
JAVA_HOME=/usr/soft/jdk1.8.0_111
HADOOP_INSTALL=/usr/soft/hadoop-3.0.3
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/usr/soft/jdk1.8.0_111/bin:/usr/soft/hadoop-3.0.3/bin:/usr/soft/hadoop-3.0.3/sbin"
我这里安装的是Hadoop3.0.3版本,最新版本,使用过程也遇到了一些小问题。 最新版本有一些限制。
配置Hadoop
1.编辑“/usr/soft/hadoop-3.0.3/etc/hadoop/”下的core-site.xml文件,将下列文本粘贴进去,并保存。
core-site.xml:
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.0.3/tmp</value>
</property>2.编辑“/usr/soft/hadoop-3.0.3/etc/hadoop/”目录下的hdfs-site.xml,粘贴以下内容并保存。
hdfs-site.xml:
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3.编辑“/usr/soft/hadoop-3.0.3/etc/hadoop/”目录下的mapred-site.xml(如果不存在将mapred-site.xml.template重命名为mapred-site.xml)文件,粘贴一下内容并保存。
mapred.site.xml:
<!-- 指定mr运行在yarn上 -->2 <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.编辑“/usr/soft/hadoop-3.0.3/etc/hadoop/”目录下的yarn-site.xml文件,粘贴以下内容并保存。
yarn-site.xml;
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
5.编辑“/usr/soft/hadoop-3.0.3/etc/hadoop/”目录下的hadoop-env.cmd文件,加入JAVA_HOME的路径,然后保存。
export JAVA_HOME=${JAVA_HOME} 修改第六个配置文件:vi slaves
修改的内容即是自己的主机名称:master
关闭防火墙
查看一下ubuntu下面的防火墙的状态和关闭开启防火墙:
sudo ufw status
sudo ufw disable 初始化namenode
hadoop namenode -format执行格式化命令后看到successfully表示格式化成功:
......
INFO util.GSet: capacity = 2^16 = 65536 entries
2018-07-01 08:24:58,011 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1445631544-127.0.1.1-1530458698004
2018-07-01 08:24:58,035 INFO common.Storage: Storage directory /usr/soft/hadoop-3.0.3/tmp/dfs/name has been **successfully** formatted.
2018-07-01 08:24:58,045 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/soft/hadoop-3.0.3/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2018-07-01 08:24:58,129 INFO namenode.FSImageFormatProtobuf: Image file /usr/soft/hadoop-3.0.3/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 391 bytes saved in 0 seconds .
2018-07-01 08:24:58,142 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2018-07-01 08:24:58,147 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1 启动Hadoop
- 先启动HDFS,执行命令:sbin/start-dfs.sh,启动成功会看到三个进程:
tancan@master:/usr/soft/hadoop-3.0.3/sbin$ start-dfs.sh
Starting namenodes on [master]
Starting datanodes
Starting secondary namenodes [master]- 再启动YARN,执行命令:sbin/start-yarn.sh,启动成功会看到两个进程:
tancan@master:/usr/soft/hadoop-3.0.3/sbin$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers - 查看启动状态:jps,启动成功会看到五个进程(不算jps):
tancan@master:/usr/soft/hadoop-3.0.3/sbin$ jps
4115 NameNode
4487 SecondaryNameNode
4249 DataNode
5340 Jps
4956 NodeManager
4830 ResourceManager
tancan@master:/usr/soft/hadoop-3.0.3/sbin$ 在window访问集群的web服务
HDFS和YARN集群都有相对应的WEB监控页面。
HDFS:http://ip:50070
YARN:http://ip:8088
ip:换成自己虚拟机的ip。192.168.0.111是我安装的虚拟机IP。
DHFSWEB监控页面
在浏览器输入http://192.168.0.111:50070,正常会显示如下图:
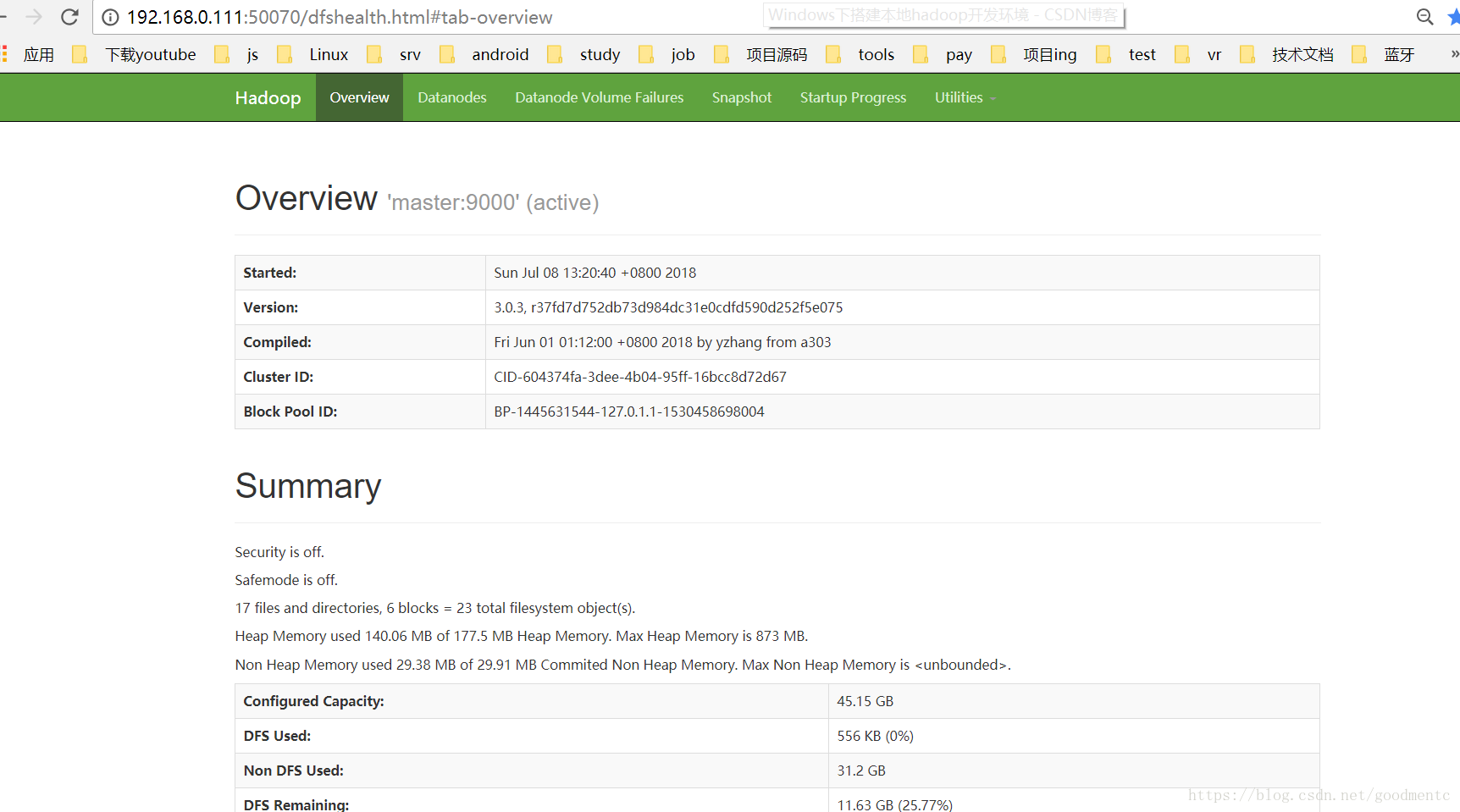
切换到该界面导航栏的Datanodes,会看到如下图:
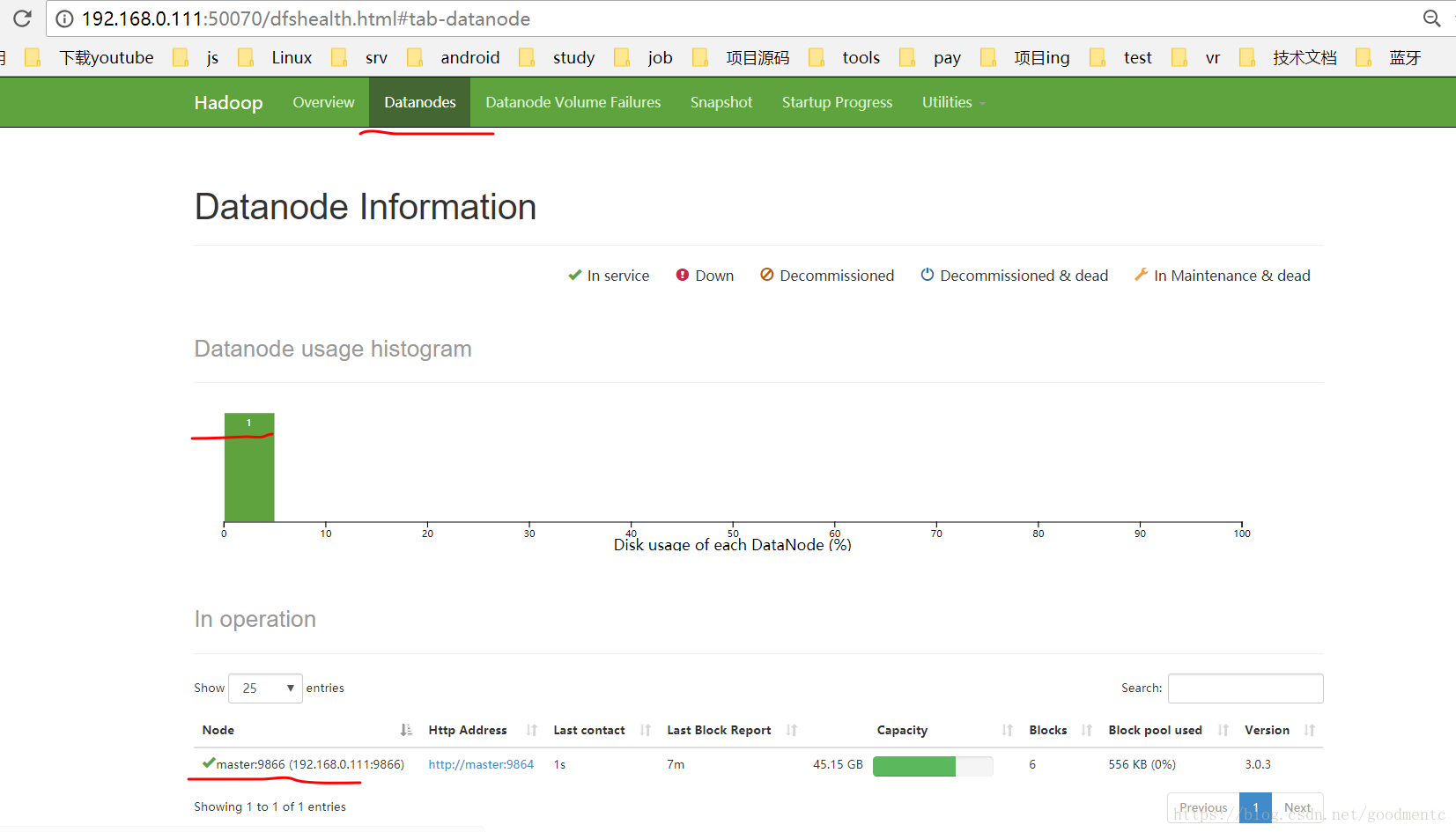
因为成功启动了一个节点,图中会显示该节点信息。
YARN WEB监控页面
浏览器输入:http://192.168.0.111:8088,正常会显示如下图:
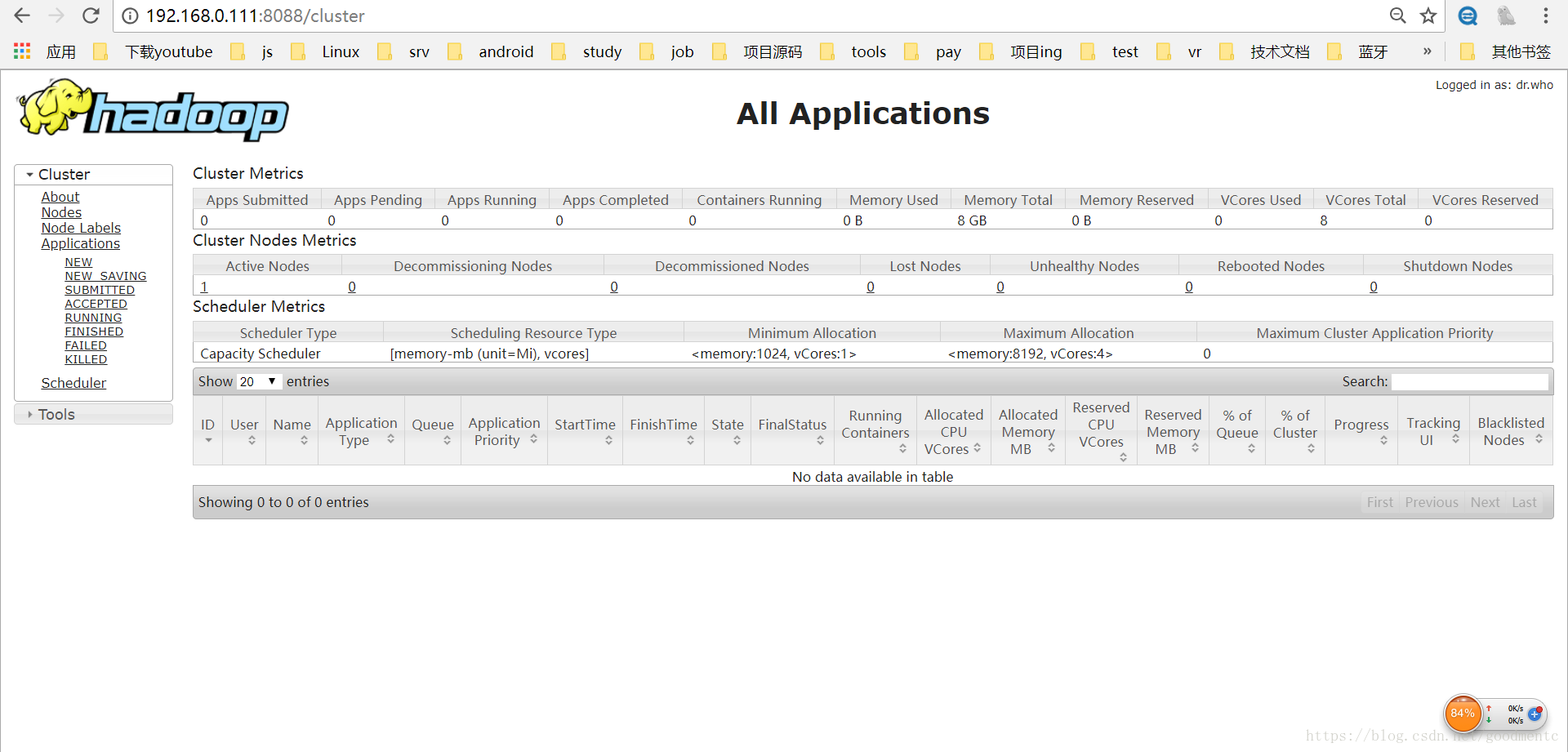
图中会显示Cluster Nodes Metrics,即所有节点情况,这里显示有一个活动节点。
HDFS简单操作命令
hdfs dfs -ls /
tancan@ubuntu:/usr/soft/hadoop-3.0.3$ hdfs dfs -ls /
Found 1 items
drwx------ - tancan supergroup 0 2018-06-29 21:20 /tmp
tancan@ubuntu:/usr/soft/hadoop-3.0.3$ hdfs dfs -mkdir
tancan@ubuntu:/usr/soft/hadoop-3.0.3$ hdfs dfs -mkdir -p /user/tc
tancan@ubuntu:/usr/soft/hadoop-3.0.3$ hdfs dfs -ls /
Found 2 items
drwx------ - tancan supergroup 0 2018-06-29 21:20 /tmp
drwxr-xr-x - tancan supergroup 0 2018-07-01 06:46 /user
tancan@ubuntu:/usr/soft/hadoop-3.0.3$ 更多操作命令请看:
https://blog.youkuaiyun.com/goodmentc/article/details/80954993
YARN集群的操作—-提交任务/作业
计算圆周率
tancan@ubuntu:/usr/soft/hadoop-3.0.3$ yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar pi 4 100 命令参数说明:
后面2个数字参数的含义:
第1个4指的是要运行4次map任务,
第2个数字100指的是每个map任务,要投掷100次,
2个参数的乘积就是总的投掷次数。
投掷次数越多,结果越准确。
任务成功后会看到打印日志:
Number of Maps = 4
Samples per Map = 100
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Starting Job
2018-07-07 22:44:06,383 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.0.111:8032
2018-07-07 22:44:07,171 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/tancan/.staging/job_1531027347990_0001
2018-07-07 22:44:07,336 INFO input.FileInputFormat: Total input files to process : 4
2018-07-07 22:44:07,398 INFO mapreduce.JobSubmitter: number of splits:4
2018-07-07 22:44:07,442 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2018-07-07 22:44:07,560 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1531027347990_0001
2018-07-07 22:44:07,562 INFO mapreduce.JobSubmitter: Executing with tokens: []
2018-07-07 22:44:08,054 INFO conf.Configuration: resource-types.xml not found
2018-07-07 22:44:08,054 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2018-07-07 22:44:08,678 INFO impl.YarnClientImpl: Submitted application application_1531027347990_0001
2018-07-07 22:44:08,824 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1531027347990_0001/
2018-07-07 22:44:08,825 INFO mapreduce.Job: Running job: job_1531027347990_0001
2018-07-07 22:44:26,110 INFO mapreduce.Job: Job job_1531027347990_0001 running in uber mode : false
2018-07-07 22:44:26,113 INFO mapreduce.Job: map 0% reduce 0%
2018-07-07 22:44:39,417 INFO mapreduce.Job: map 100% reduce 0%
2018-07-07 22:44:45,474 INFO mapreduce.Job: map 100% reduce 100%
2018-07-07 22:44:45,492 INFO mapreduce.Job: Job job_1531027347990_0001 completed successfully
2018-07-07 22:44:45,620 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=94
FILE: Number of bytes written=1011446
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1048
HDFS: Number of bytes written=215
HDFS: Number of read operations=21
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=4
Launched reduce tasks=1
Data-local map tasks=4
Total time spent by all maps in occupied slots (ms)=40252
Total time spent by all reduces in occupied slots (ms)=3906
Total time spent by all map tasks (ms)=40252
Total time spent by all reduce tasks (ms)=3906
Total vcore-milliseconds taken by all map tasks=40252
Total vcore-milliseconds taken by all reduce tasks=3906
Total megabyte-milliseconds taken by all map tasks=41218048
Total megabyte-milliseconds taken by all reduce tasks=3999744
Map-Reduce Framework
Map input records=4
Map output records=8
Map output bytes=72
Map output materialized bytes=112
Input split bytes=576
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=112
Reduce input records=8
Reduce output records=0
Spilled Records=16
Shuffled Maps =4
Failed Shuffles=0
Merged Map outputs=4
GC time elapsed (ms)=2975
CPU time spent (ms)=3320
Physical memory (bytes) snapshot=1536417792
Virtual memory (bytes) snapshot=6434537472
Total committed heap usage (bytes)=1403256832
Peak Map Physical memory (bytes)=425193472
Peak Map Virtual memory (bytes)=1291177984
Peak Reduce Physical memory (bytes)=161067008
Peak Reduce Virtual memory (bytes)=1285955584
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=472
File Output Format Counters
Bytes Written=97
Job Finished in 39.411 seconds
Estimated value of Pi is 3.17000000000000000000
tancan@master:/usr/soft/hadoop-3.0.3/sbin$ 使用hadoop自带的mapreduce程序来测试mapreduce的效果
hadoop jar hadoop-mapreduce-examples-3.0.3.jar pi 5 100
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ hadoop jar hadoop-mapreduce-examples-3.0.3.jar pi 5 100执行结果:
......
2018-07-07 23:08:22,984 INFO mapreduce.Job: Job job_1531027347990_0002 completed successfully
2018-07-07 23:08:23,076 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=116
FILE: Number of bytes written=1213743
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1305
HDFS: Number of bytes written=215
HDFS: Number of read operations=25
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=5
Launched reduce tasks=1
Data-local map tasks=5
Total time spent by all maps in occupied slots (ms)=54215
Total time spent by all reduces in occupied slots (ms)=2405
Total time spent by all map tasks (ms)=54215
Total time spent by all reduce tasks (ms)=2405
Total vcore-milliseconds taken by all map tasks=54215
Total vcore-milliseconds taken by all reduce tasks=2405
Total megabyte-milliseconds taken by all map tasks=55516160
Total megabyte-milliseconds taken by all reduce tasks=2462720
Map-Reduce Framework
Map input records=5
Map output records=10
Map output bytes=90
Map output materialized bytes=140
Input split bytes=715
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=140
Reduce input records=10
Reduce output records=0
Spilled Records=20
Shuffled Maps =5
Failed Shuffles=0
Merged Map outputs=5
GC time elapsed (ms)=1323
CPU time spent (ms)=3030
Physical memory (bytes) snapshot=1497513984
Virtual memory (bytes) snapshot=7735386112
Total committed heap usage (bytes)=1399586816
Peak Map Physical memory (bytes)=270938112
Peak Map Virtual memory (bytes)=1294159872
Peak Reduce Physical memory (bytes)=165556224
Peak Reduce Virtual memory (bytes)=1291239424
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=590
File Output Format Counters
Bytes Written=97
Job Finished in 25.53 seconds
Estimated value of Pi is 3.16000000000000000000
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ 统计单词个数
- 创建一个count.txt用于测试里面的单词重复的次数:
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ vi count.txt
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ cat count.txt
hello li
hello ming
hello zhao
hello sun
hello qian
hello- 上传数据
因为数据是在集群上面跑的,所以文件要放到集群上面;
首先需要创建一个文件夹,用于存放文件:
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ hadoop fs -mkdir /wordcount
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ hadoop fs -mkdir hdfs://master:9000/wordcount/input
创建好的文件夹可以在web服务器里面查看,如下图所示:
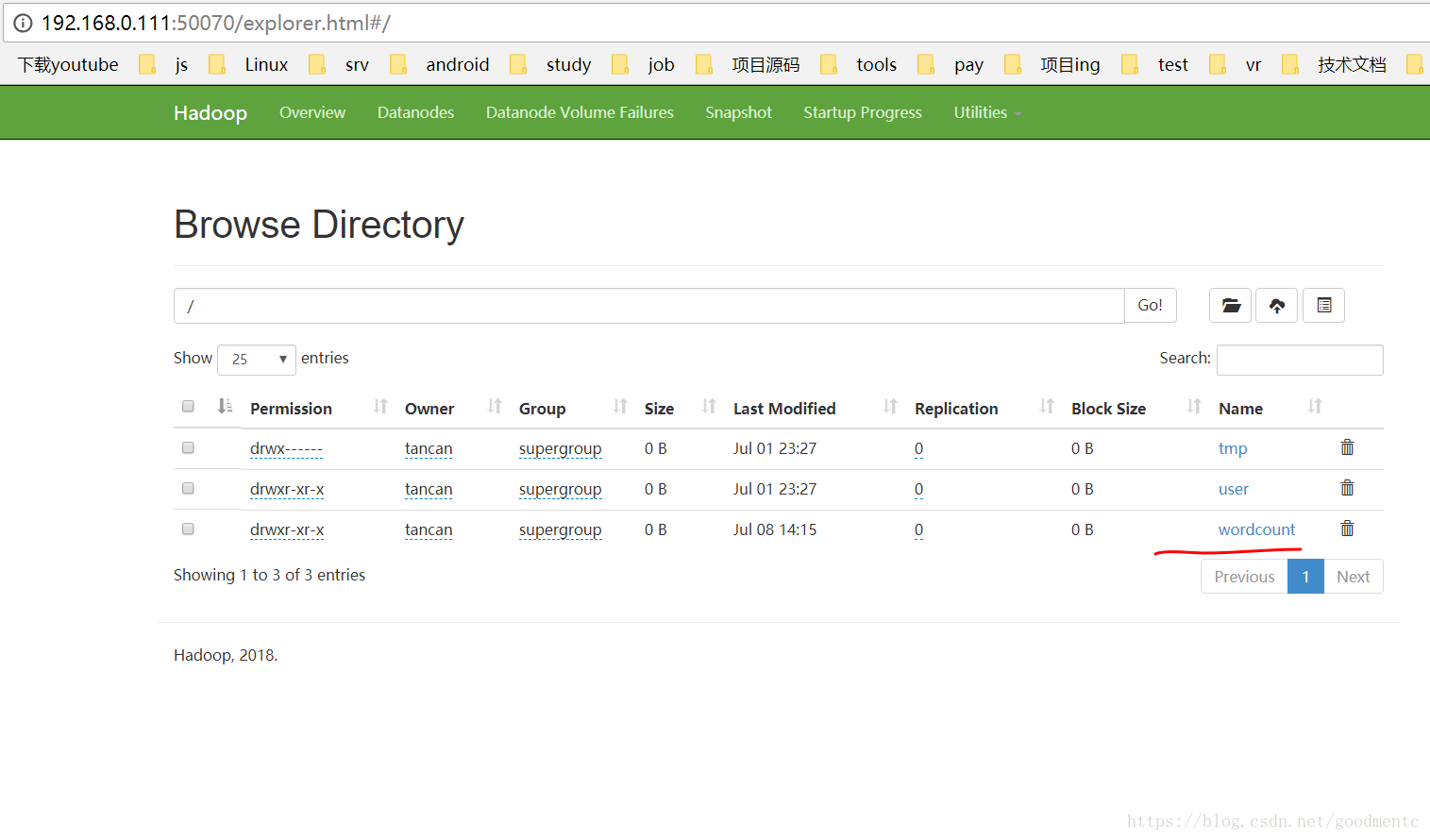
将新建的count.txt文件上传到input文件夹里面,如下图所示:
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ hadoop fs -put count.txt /wordcount/input
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ 在WEB界面查看该文件,
http://192.168.0.111:50070/explorer.html#/wordcount/input:
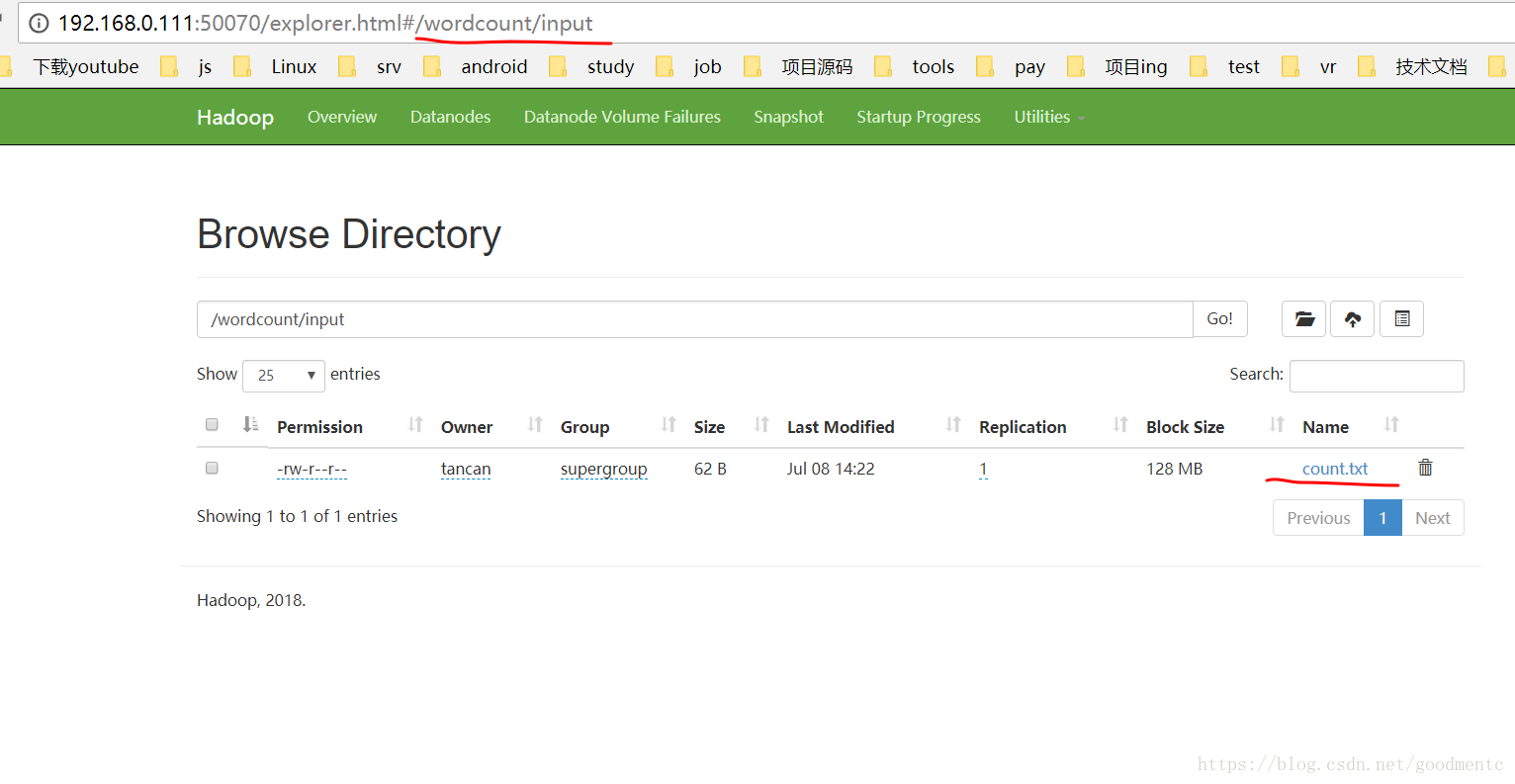
- 使用mapreduce的自带案例进行单词重读测试:
an@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ hadoop jar hadoop-mapreduce-examples-3.0.3.jar wordcount /wordcount/input /wordcount/output - 查询执行之后的结果:
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ hadoop fs -ls /wordcount/output
Found 2 items
-rw-r--r-- 1 tancan supergroup 0 2018-07-07 23:25 /wordcount/output/_SUCCESS
-rw-r--r-- 1 tancan supergroup 40 2018-07-07 23:25 /wordcount/output/part-r-00000
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ hadoop fs -cat /wordcount/output/part-r-00000
hello 6
li 1
ming 1
qian 1
sun 1
zhao 1
tancan@master:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$
也可以到WEB界面进行查看,
http://192.168.0.111:50070/explorer.html#/wordcount/output:
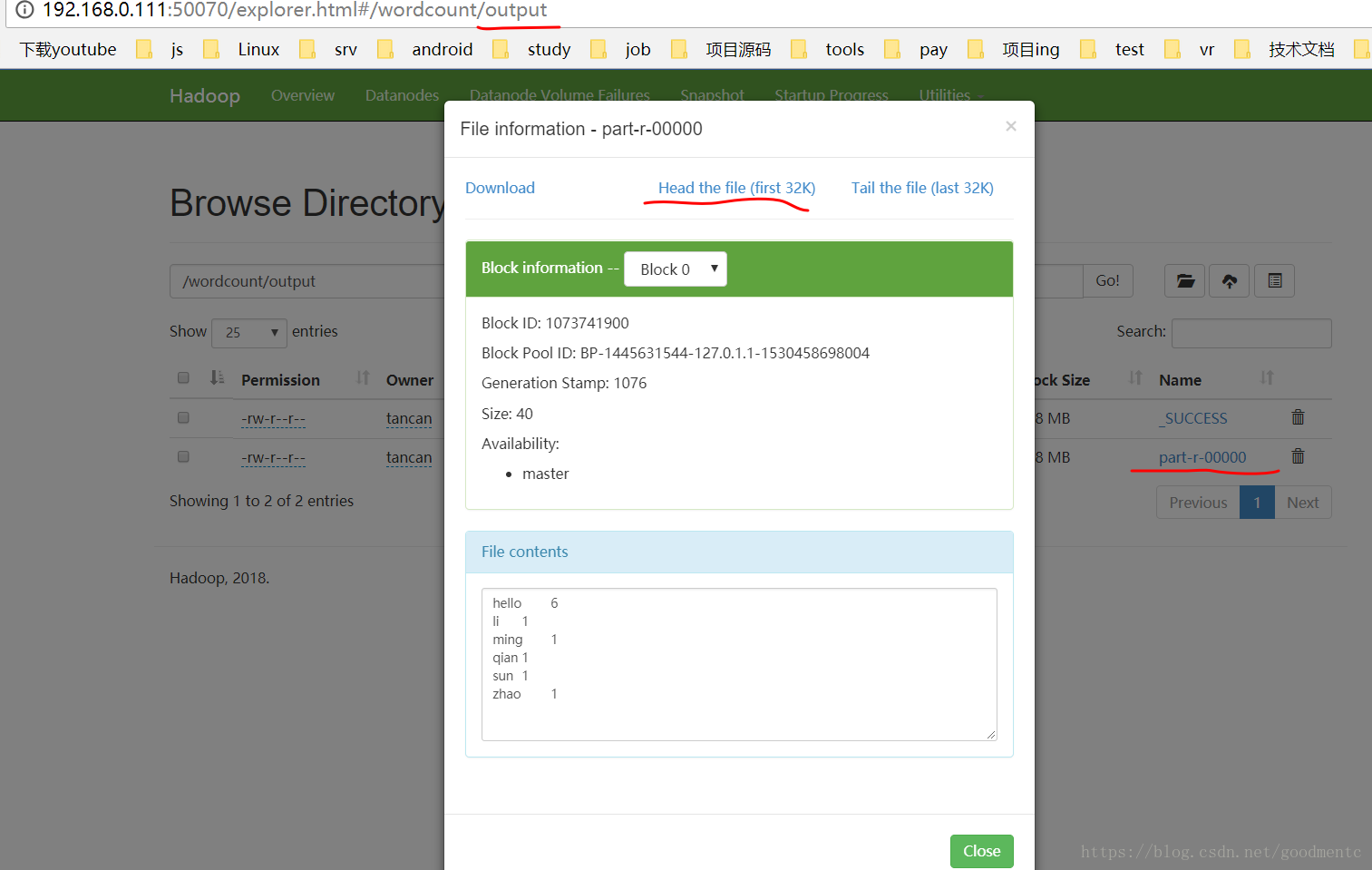
- 结果说明:
hadoop返回的结果是<key,value>的键值对的形式。
所以结果也就是把单词以及单词的个数返:
hello 6
li 1
ming 1
qian 1
sun 1
zhao 1上传文件到dfs
两种方法:命令方式和界面操作。
命令方式
tancan@ubuntu:/usr/soft/hadoop-3.0.3/tmp$ hadoop fs -put /home/tancan/source/hadoop/core-site.xml hdfs://master:9000/打开web管理界面查看:Utilities-Browse the file system,可以看到刚刚上传的文件core-size.xml:
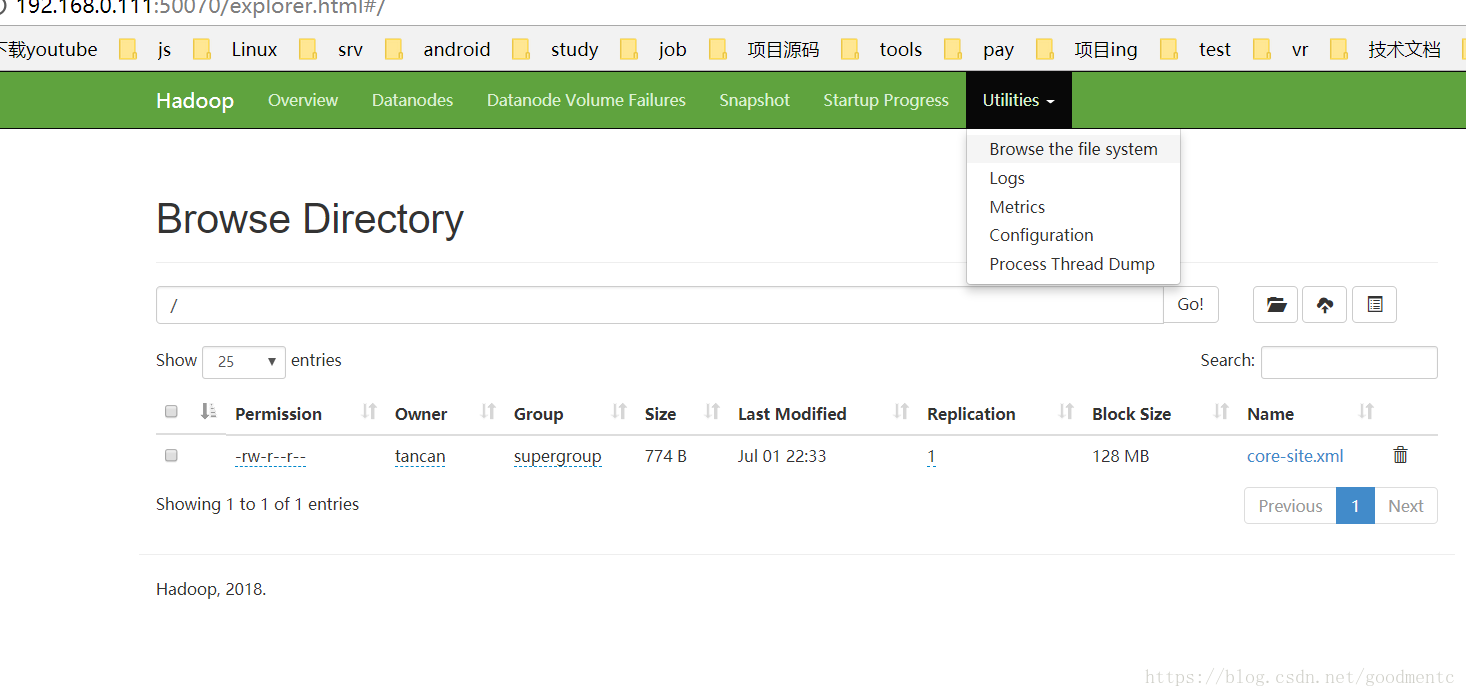
界面方式
在上面的web界面,点击下图红线标识图标,可以上传文件:
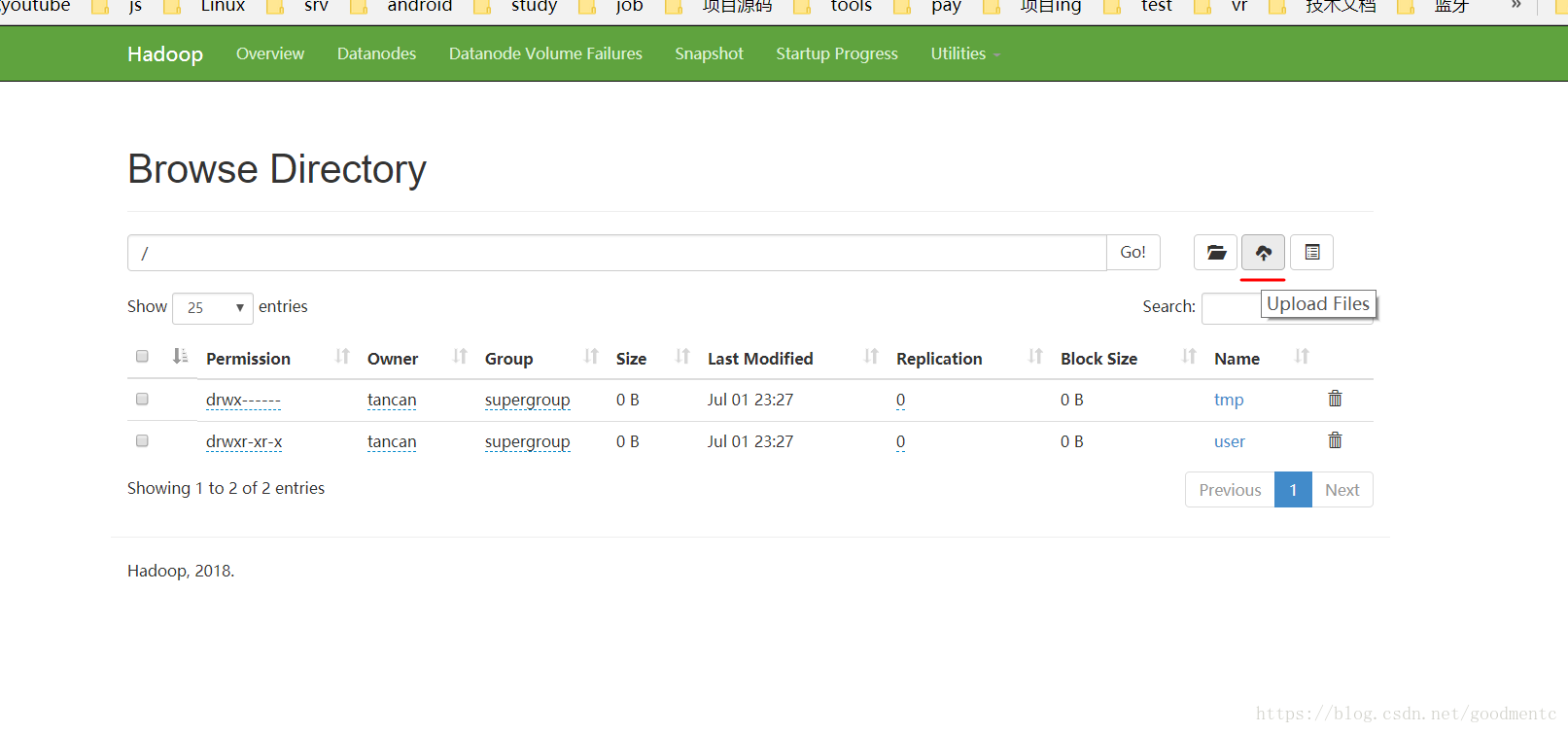
注:实际操作没有成功,待研究。
Couldn't upload the file filename.txt. 下载文件
从HDFS下载文件到当前路径
命令:hadoop fs -get hdfs://master:9000/core-site.xml
core-site.xml是HDFS文件系统已有文件。
tancan@ubuntu:~$ hadoop fs -get hdfs://master:9000/core-site.xml
tancan@ubuntu:~$ ls
1.gn Documents myWebRTC64.tar.gz source
androidapp.tar.gz Downloads Pictures Templates
core-site.xml google_appengine_1.9.50.zip ProjectRTC-master test
depot_tools.tar.gz hadoop Public Videos
Desktop Music soft
tancan@ubuntu:~$ HDFS的大体实现的思想
- HDFS通过分布式集群来存储文件,为客户端提供了一个方便的访问方式,就是一个虚拟的目录结构;
- 文件存储到HDFS集群中的时候是被切分成block块的;
- 文件的block存放在若干台datanode上;
- HDFS文件系统中的文件与真实的block有映射关系,有namenode管理;
- HDFS文件系统中的文件的block在集群中有多个副本,好处是:可提高数据可靠性,还可提高数据访问的吞吐量。
DFS命令
hadoop fs 显示hadoop 的fs的功能
hadoop fs -ls / 列举某目录下面的文件夹
hadoop fs -lsr 列举某目录下面的文件夹及其文件夹里面的文件
hadoop fs -mkdir /user/hadoop 在user文件夹下面创建一个hadoop文件夹
hadoop fs -put a.txt /user/hadoop/ 将a.txt文件上传到user文件夹下面的hadoop文件夹下面
hadoop fs -get /user/hadoop/a.txt / 获取到user文件夹下面的hadoop文件夹下面的a.txt文件
hadoop fs -cp /原路径 /目标路径 拷贝文件,从原路径拷贝到目标路径
hadoop fs -mv /原路径 /目标路径 从原路径移动到目标路径
hadoop fs -cat /user/hadoop/a.txt 查看a.txt文件里面的内容
hadoop fs -rm /user/hadoop/a.txt 删除user文件夹下面的hadoop文件夹下面的a.txt文件
hadoop fs -rm -r /user/hadoop/a.txt 递归删除,文件夹和文件
hadoop fs -copyFromLocal /本地路径 /目的路径 与hadoop fs -put功能类似。
hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件。
hadoop fs -chown 用户名:用户组名 /文件名 修改所属的用户和用户组,权限修改
hadoop fs -chmod 777 /文件名 文件的权限可读可写可执行的的权限修改
hadoop fs -df -h / 查看根目录下面的磁盘空间,可用和未用等等
hadoop fs -du -s -h / 查看某文件的大小
hadoop fs -du -s -h hdfs://主机名:9000/* 查看根目录下面的所有文件的大小其他
遇到的问题
- mapred-site.xml 配置导致
tancan@ubuntu:/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce$ hadoop jar hadoop-mapreduce-examples-3.0.3.jar pi 5 5
Number of Maps = 5
Samples per Map = 5
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Starting Job
2018-07-01 07:39:21,454 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.0.111:8032
2018-07-01 07:39:22,150 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/tancan/.staging/job_1530455506282_0001
2018-07-01 07:39:22,335 INFO input.FileInputFormat: Total input files to process : 5
2018-07-01 07:39:22,799 INFO mapreduce.JobSubmitter: number of splits:5
2018-07-01 07:39:22,880 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2018-07-01 07:39:23,024 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1530455506282_0001
2018-07-01 07:39:23,026 INFO mapreduce.JobSubmitter: Executing with tokens: []
2018-07-01 07:39:23,476 INFO conf.Configuration: resource-types.xml not found
2018-07-01 07:39:23,477 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2018-07-01 07:39:24,453 INFO impl.YarnClientImpl: Submitted application application_1530455506282_0001
2018-07-01 07:39:24,656 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1530455506282_0001/
2018-07-01 07:39:24,656 INFO mapreduce.Job: Running job: job_1530455506282_0001
2018-07-01 07:39:29,738 INFO mapreduce.Job: Job job_1530455506282_0001 running in uber mode : false
2018-07-01 07:39:29,740 INFO mapreduce.Job: map 0% reduce 0%
2018-07-01 07:39:29,763 INFO mapreduce.Job: Job job_1530455506282_0001 failed with state FAILED due to: Application application_1530455506282_0001 failed 2 times due to AM Container for appattempt_1530455506282_0001_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2018-07-01 07:39:28.782]Exception from container-launch.
Container id: container_1530455506282_0001_02_000001
Exit code: 1
[2018-07-01 07:39:28.785]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
[2018-07-01 07:39:28.787]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
For more detailed output, check the application tracking page: http://master:8088/cluster/app/application_1530455506282_0001 Then click on links to logs of each attempt.
. Failing the application.
2018-07-01 07:39:29,809 INFO mapreduce.Job: Counters: 0
Job job_1530455506282_0001 failed!解决,修改mapred-site.xml内容为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/soft/hadoop-3.0.3/etc/hadoop,
/usr/soft/hadoop-3.0.3/share/hadoop/common/*,
/usr/soft/hadoop-3.0.3/share/hadoop/common/lib/*,
/usr/soft/hadoop-3.0.3/share/hadoop/hdfs/*,
/usr/soft/hadoop-3.0.3/share/hadoop/hdfs/lib/*,
/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce/*,
/usr/soft/hadoop-3.0.3/share/hadoop/mapreduce/lib/*,
/usr/soft/hadoop-3.0.3/share/hadoop/yarn/*,
/usr/soft/hadoop-3.0.3/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
- yarn的从节点没有启动起来导致:
tancan@ubuntu:/usr/soft/hadoop-3.0.3$ yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar pi 4 100
Number of Maps = 4
Samples per Map = 100
2018-07-01 06:49:47,961 WARN hdfs.DataStreamer: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/tancan/QuasiMonteCarlo_1530452986743_1525369731/in/part0 could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2107)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:287)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2668)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:868)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:550)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:872)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:818)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1686)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2678)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1491)
at org.apache.hadoop.ipc.Client.call(Client.java:1437)
at org.apache.hadoop.ipc.Client.call(Client.java:1347)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:498)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy12.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream.addBlock(DFSOutputStream.java:1078)
at org.apache.hadoop.hdfs.DataStreamer.locateFollowingBlock(DataStreamer.java:1865)
at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1668)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:716)
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/tancan/QuasiMonteCarlo_1530452986743_1525369731/in/part0 could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2107)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:287)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2668)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:868)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:550)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:872)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:818)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1686)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2678)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1491)
at org.apache.hadoop.ipc.Client.call(Client.java:1437)
at org.apache.hadoop.ipc.Client.call(Client.java:1347)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:498)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy12.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream.addBlock(DFSOutputStream.java:1078)
at org.apache.hadoop.hdfs.DataStreamer.locateFollowingBlock(DataStreamer.java:1865)
at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1668)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:716)
tancan@ubuntu:/usr/soft/hadoop-3.0.3$ 

















 2372
2372




 到【灌水乐园】发言
到【灌水乐园】发言









