






索引概述

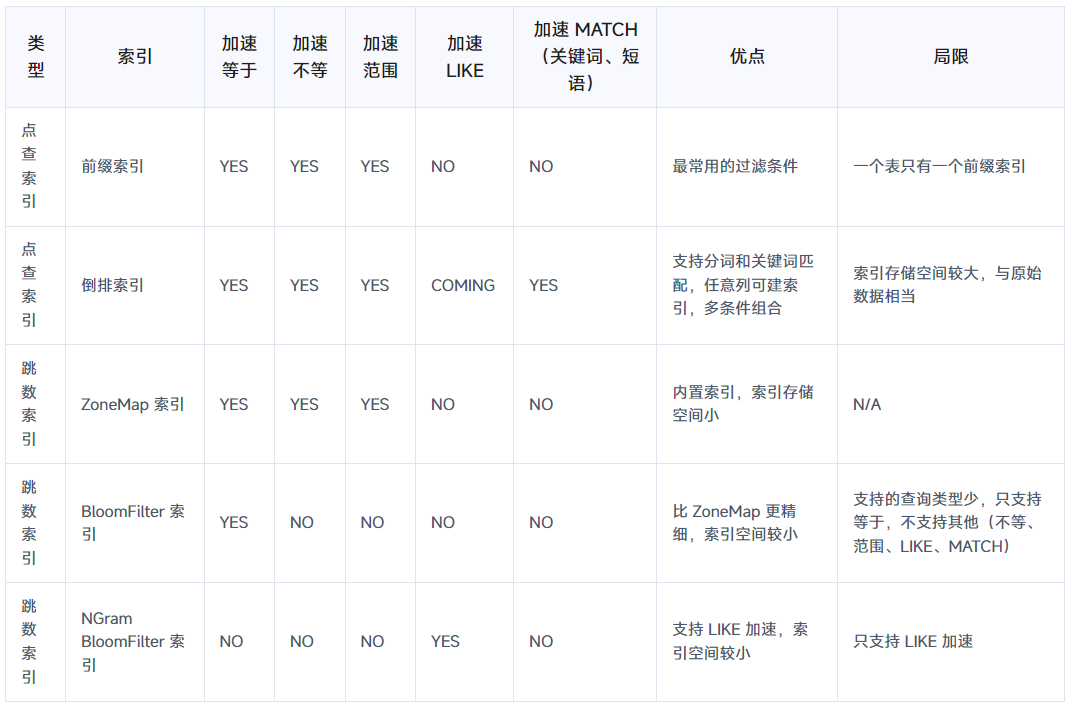
索引对比
索引建议
(1)最频繁使用的过滤条件指定为 Key字段,自动建前缀索引,它的过滤效果最好,但是一个表只能有一个前缀索引,因此要用在最频繁的过滤条件上,前缀索引比较小,所以可以全量在内存中缓存。建表时会自动取表的 Key 的前 36 字节作为前缀索引。
(2)对非 Key 字段如有过滤加速需求,首选建倒排索引,因为它的适用面广,可以多条件组合,次选下面两种索引:
A. 有字符串 LIKE 匹配需求,再加一个 NGram BloomFilter 索引
B. 对索引存储空间很敏感,将倒排索引换成 BloomFilter 索引
(3)如果性能不及预期,通过 QueryProfile 分析索引过滤掉的数据量和消耗的时间,具体参考各个索引的详细文档。
(4)数据块一行数据的前 36 个字节作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。如果第一列即为 VARCHAR,那么即使没有达到 36 字节,也会直接截断,后面的列不再加入前缀索引,所以在建表时,正确选择列顺序,能够极大地提高查询效率。



















 3833
3833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











