




这篇文章提出了一种通过扩散模型直接从 EEG 信号生成图像的方法:NECOMIMI 框架。
一、训练
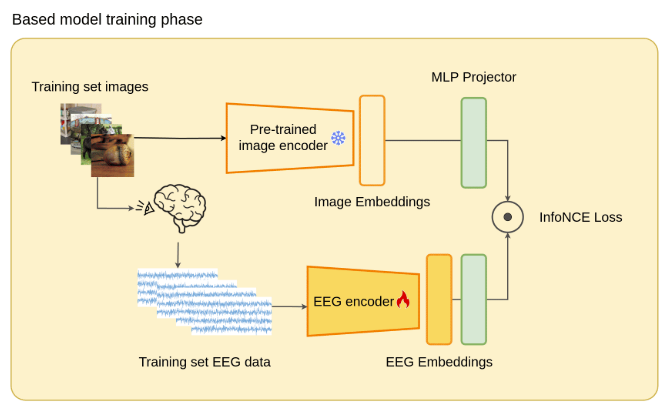
采用预训练好的 CLIP - ViT 图像编码器对图像进行编码,得到图像嵌入,训练EEG编码器对EEG进行编码,得到EEG嵌入,这些嵌入通过MLP投影仪投射到统一的空间中,使用InfoNCE损失使得图像和脑电嵌入在潜在空间中对齐。(对比学习的方法)
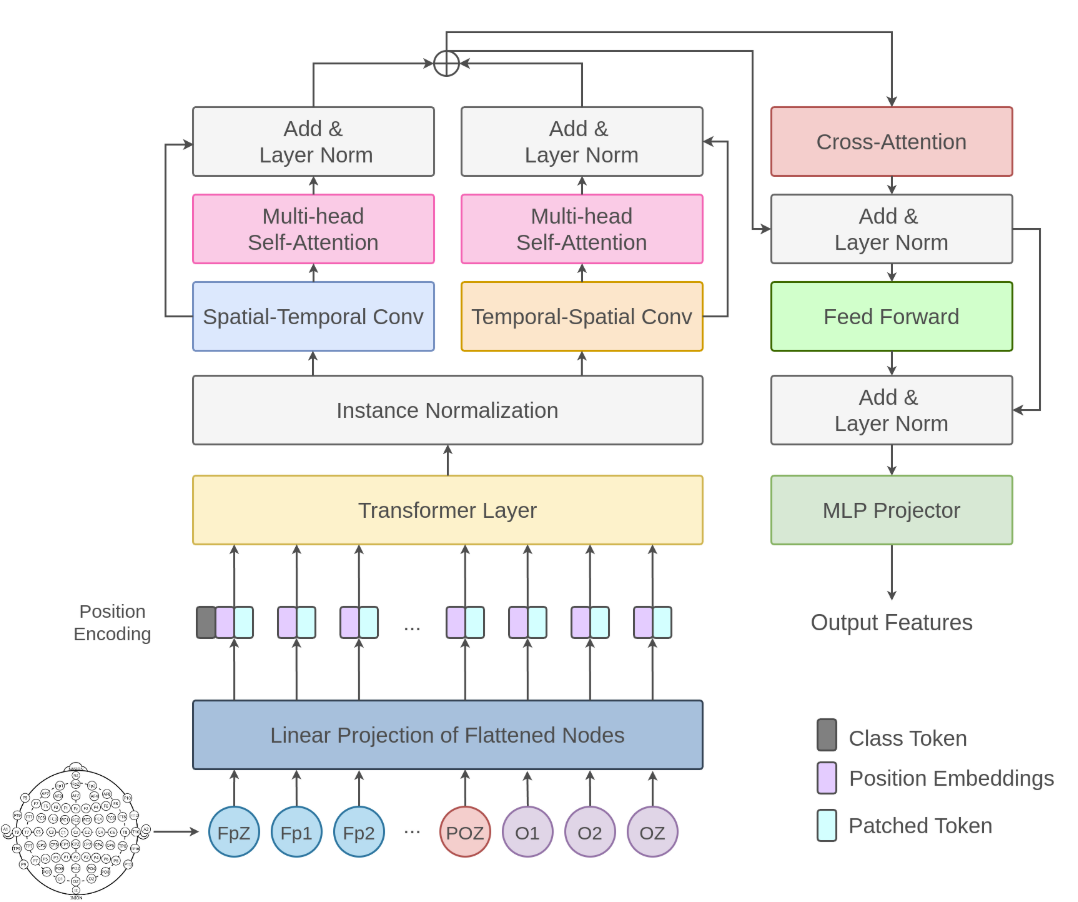
其中,EEG编码器采用了一种新的基于多注意机制的脑电信号编码器NERV,其结构如下:
二、测试
1、零样本分类测试
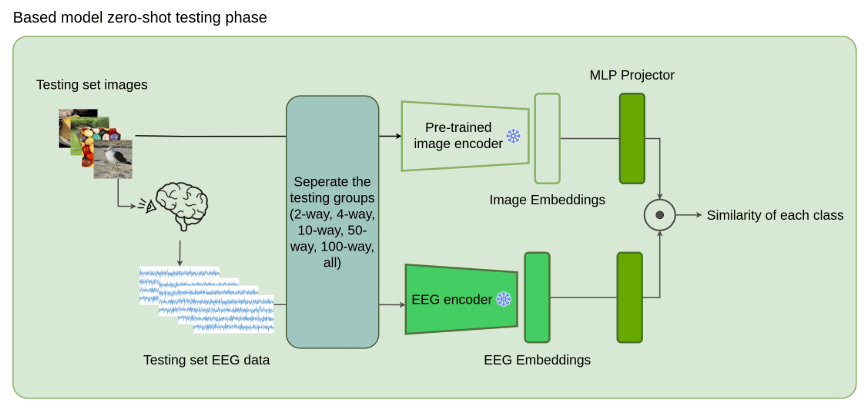
文章采用ThingsEEG数据集,它的测试集中有200个类别,每个类别有一张图片。将测试集分为2-way, 4-way, 10-way, 50-way, 100-way,全部,用前面训练好的模型去评估分类准确率。部分结果如下:
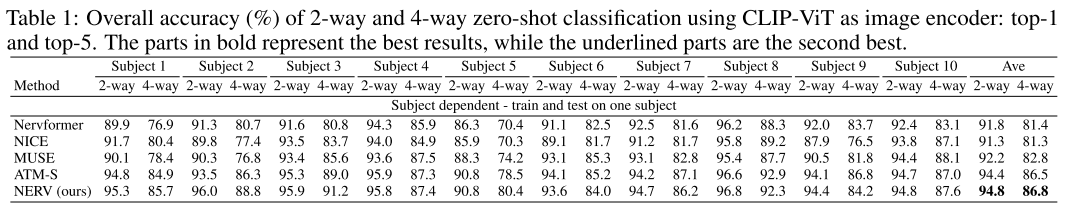
(个人观点:准确率提高很少,NERV这个结构也没有什么独特之处)
2、单阶段图像生成
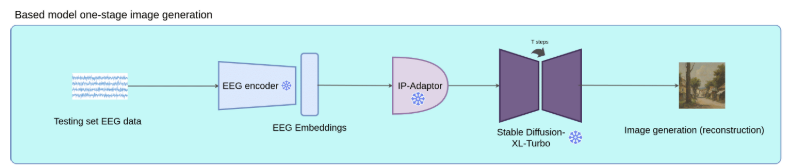
直接用测试集的EEG嵌入来生成图像,其中IP-Adapter 是腾讯 AILab 开发的一种高效轻量级适配器,它把EEG嵌入转化为条件,指导Stable Diffusion生成图像。结果发现,无论类别如何,用这种方式生成的图片大多是景观。
3、两阶段图像生成

第一阶段:训练先验扩散模型,让模型学习如何从有噪声的嵌入中恢复原始嵌入。具体过程是训练一个Diffusion UNet,去生成新的EEG嵌入。
第二阶段:将第一阶段生成的EEG嵌入作为提示输入ip适配器,通过Stable Diffusion XL-Turbo模型生成图像。
图像生成结果:

4、基于类别的评估表(CAT)得分
文章提出了一个专门为脑电图到图像评估设计的新指标。在ThingsEEG测试数据集(它包含200个类别,每个类别有一个图像)中,每个图像都被手动标记为两个广泛类别的标签,一个用于特定类别的标签,一个用于背景内容的标签,结果每个图像总共有五个标签。通过chatgpt - 40提取了这些标签。因此整个测试数据集包含200张图像×5 tags = 1000个点。使用手动注释,可以确定生成的图像的类别是否与这些标签匹配。
(感觉像是文章自己创建了一个能使自己的结果看起来很漂亮的评价指标...)


















 3093
3093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









