







 本文详细介绍了Kafka的消息日志存储机制,包括文件目录布局、日志索引、日志分段切分、索引文件预分配空间、日志清理策略以及磁盘存储技术。Kafka通过稀疏索引、顺序写入、页缓存和零拷贝等技术提高存储效率和检索速度。日志清理策略包括基于时间、大小和起始偏移量的保留策略,以及日志压缩。
本文详细介绍了Kafka的消息日志存储机制,包括文件目录布局、日志索引、日志分段切分、索引文件预分配空间、日志清理策略以及磁盘存储技术。Kafka通过稀疏索引、顺序写入、页缓存和零拷贝等技术提高存储效率和检索速度。日志清理策略包括基于时间、大小和起始偏移量的保留策略,以及日志压缩。
文章目录
1. 文件目录布局
主题、分区、副本回顾:
- Kafka中的消息是以主题为基本单位进行归类的,各个主题在逻辑上相互独立。
- 每个主题又可以分为一个或多个分区,分区的数量可以在主题创建时候指定,也可以在之后修改。每条消息在发送的时候会根据分区规则被追加到指定的分区中,分区中的每条消息都会被分配一个唯一的序列号,也就是通常所说的偏移量
offset; - 每个分区又拥有多个副本,一个负责读写的leader副本和0或多个负责同步的follower副本;leader副本均匀的分布在多个broker上,实现负载均衡;
日志布局:
- Kafka中一个副本对应一个日志
Log; - 为了防止Log过大,Kafka又引入了日志分段
LogSegment的概念,将Log切分为多个LogSegment,相当于一个巨型文件被平均分配为多个相对较小的文件,这样也便于消息的维护和清理; Log在物理上对应一个文件夹;LogSetment是逻辑上的概念,每个LogSetment对应磁盘上的一个日志文件和两个索引文件(偏移量索引和时间戳索引),以及可能的其他文件(比如,以.txnindex为后缀的事务索引文件);
主题、分区、副本和日志文件的对应关系如下:
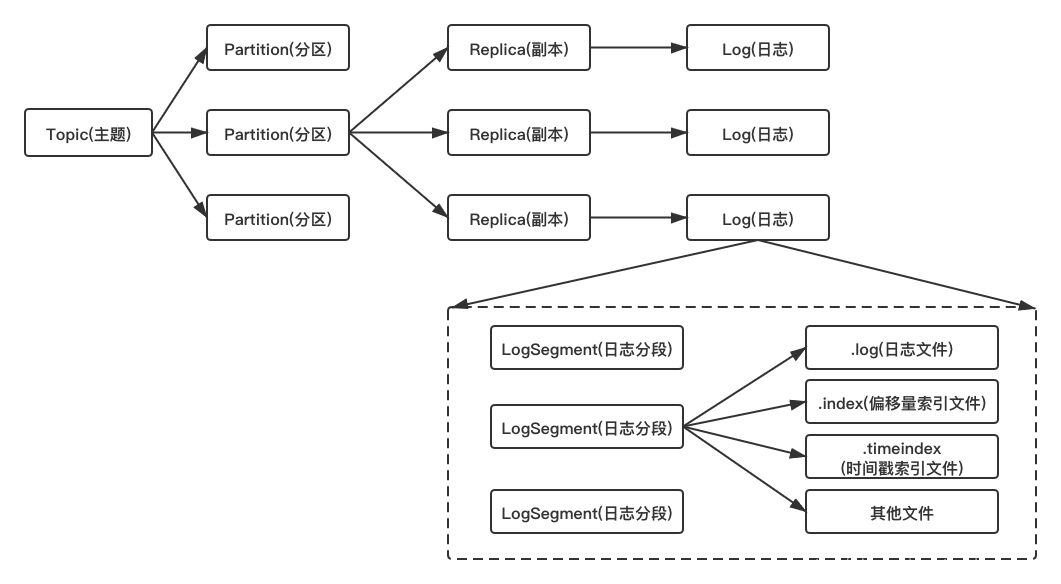
- Log对应一个命名形式为
<topic>-<partition>的文件夹;每个副本对应的日志文件夹以分区号为后缀; - 向Log中追加消息时是顺序写入的,只有最后一个
LogSegment才能执行写入操作,在此之前的所有LogSegment都不能写入数据;最后一个LogSegment称为activeSegment; - 为了便于消息的检索,每个LogSegment中的日志文件(以
.log为文件后缀)都有对应的两个索引文件:偏移量索引文件(以.index为文件后缀)和时间戳索引文件(以timeindex为文件后缀); - 每个
LogSegment都有一个基准偏移量baseOffset,用来表示当前LogSegment中第一条消息的offset,偏移量是一个64位的长整数,日志文件和两个索引文件都是根据偏移量命名的; - 在创建主题的时候,如果当前broker中不止配置了一个根目录,那么会挑选分区数最少的根目录来完成本次创建任务;
2. 日志索引
两个索引文件
- 每个日志分段文件对应了两个索引文件(偏移量索引文件和时间戳索引文件),主要用来提高查找消息的效率;
- 偏移量索引文件:用来建立消息偏移量(
offset)到物理地址之间的映射关系,方便快速定位消息所在的物理文件位置; - 时间戳索引文件:根据指定的时间戳(
timestamp)来查找对应的偏移量信息;
稀疏索引
- Kafka中的索引文件以稀疏矩阵(
sparse index)的方式构造消息的索引,并不保证每个消息在索引文件中都有对应的索引项; - 每当写入一定量(由broker端参数
log.index.interval.bytes指定,默认值为4096,即4KB)的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项; - 增大或减小
log.index.interval.bytes的值,对应的可以缩小或增加索引项的密度; - 稀疏索引通过
MappedByteBuffer将索引文件映射到内存中,以加快索引的查询速度; - 偏移量索引文件中的偏移量是单调递增的,查询指定偏移量时,使用二分查找法来快速定位偏移量位置;如果指定的偏移量不在索引文件中,则会返回小于指定偏移量的最大偏移量;然后去日志文件中从返回的偏移量位置开始顺序查找;
- 时间戳索引文件中的时间戳也保持单调递增,查询指定时间戳时,也根据二分查找法来查找不大于该时间戳的最大偏移量,然后还需要根据偏移量从偏移量索引文件中进行再次定位;
- 稀疏索引的方式是在磁盘空间、内存空间、查找时间等多方面的一个折中方案;
日志分段切分
- 日志分段达到一定的条件时需要切分,那么对应的索引文件也需要进行切分;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









