







 本文介绍了一个基于LR解析器的错误检测与定位系统,该系统能够识别并定位多种类型的错误,包括赋值语句错误、语法错误等。通过预处理和递归下降解析策略,系统能有效识别错误并提供详细的错误信息。
本文介绍了一个基于LR解析器的错误检测与定位系统,该系统能够识别并定位多种类型的错误,包括赋值语句错误、语法错误等。通过预处理和递归下降解析策略,系统能有效识别错误并提供详细的错误信息。
想了解更多内容,移步至编译原理专栏
==========================2021.12.22 更新===================================
整理了一下代码,同步到了gitee
https://gitee.com/godelgnis/lrparser https://gitee.com/godelgnis/lrparser
https://gitee.com/godelgnis/lrparser
--------------------------------------------------分割线---------------------------------------------------------------------
在上次实验的基础上进行改进,能够识别多个错误,本文的只进行了部分数据的测试,所以可能会有其他错误识别不出来
部分缺失的代码请参考我之前写的博客,可以查看完整的代码
本博客的程序只能识别赋值语句,能够输出并输出多种错误的类型,并且实现了错误定位功能
package codescanner;
import java.util.ArrayList;
public class IrParser {
private Analyzer analyzer;
private ArrayList<Word> list = new ArrayList<>();
private Word word;
private int index = 0; // 从列表中获取单词的下标
private boolean error = false; //标记是否检测到错误
public int rowNum = 1; //用来记录行数
public IrParser() {
analyzer = new Analyzer("input.txt", "output.txt");
analyzer.analyze(analyzer.getContent());
list = analyzer.getList();
}
public void parse() {
if(list.size() > 0 && (word = getNext(list)).getTypenum() !=1) {
error = true;
index--;
System.out.print("begin错误");
System.out.println(" 识别符号为 " + word.getWord() + " " + "位置: " + rowNum + "行");
}
//分隔符
pretreatment();
if(list.size() > 0) {
word = getNext(list);
if (word == null) {
error = true;
System.out.print("缺end错误");
System.out.println(" 文件已结束 " + "位置: " + rowNum + "行");
}else if(word.getTypenum() != 6){
error = true;
System.out.print("缺end错误");
System.out.println(" 识别符号为 " + word.getWord() + " " + "位置: " + rowNum + "行");
}
}
if (!error) {
System.out.println("success");
}
}
/**
* 预处理
*/
public void pretreatment() {
while (word != null && word.getTypenum() != 6) {
statement();
}
index--;
}
/**
* 赋值错误和语句错误
*/
public void statement() {
word = getNext(list);
if (word != null && word.getTypenum() != 26) {
if (word.getTypenum() == 10) {
assignment();
} else {
if (word.getTypenum() != 0 && word.getTypenum() != 6) {
error = true;
System.out.print("语句错误");
System.out.println(" 识别符号为 " + word.getWord() + " " + "位置: " + rowNum + "行");
assignment();
}
}
}
}
/**
* 赋值号错误
*/
public void assignment() {
word = getNext(list);
if (word != null ) {
if (word.getTypenum() == 18) {
expression();
} else {
error = true;
System.out.print("赋值号错误");
System.out.println(" 识别符号为 " + word.getWord() + " " + "位置: " + + rowNum + "行");
expression();
}
}
}
/**
* 分析表达式表达式
*/
public void expression() {
if (word.getTypenum() == 26)
return;
word = getNext(list);
if (word != null) {
term();
while (word.getTypenum() == 13 || word.getTypenum() == 14) {
word = getNext(list);
term();
}
}
}
public void term() {
if (word != null) {
factor();
while (word.getTypenum() == 15 || word.getTypenum() == 16) {
word = getNext(list);
factor();
}
}
}
/**
* "("错误 和 表达式错误
*/
public void factor() {
if (word != null) {
if (word.getTypenum() == 10 || word.getTypenum() == 11) {
word = getNext(list);
} else if (word.getTypenum() == 27) {
expression();
if (word.getTypenum() == 28) {
word = getNext(list);
} else {
error = true;
System.out.print("')'错误");
System.out.println(" 识别符号为 " + word.getWord() + " " + "位置: " + rowNum + "行");
if (word.getTypenum() == 26)
return;
word = getNext(list);
}
} else {
error = true;
System.out.print("表达式错误");
System.out.println(" 识别符号为 " + word.getWord() + " " + "位置: " + rowNum + "行");
if (word.getTypenum() == 26)
return;
word = getNext(list);
}
}
}
/**
* 取下一个词,如果是读取到换行,就增加行数,
* @param list
* @return
*/
public Word getNext(ArrayList<Word> list) {
if (index < list.size()) {
Word currentWord = list.get(index++);
while (currentWord.getTypenum() == 30 || currentWord.getTypenum() == 31) {
//因为一个换行字符被我转换成长度为2字符串了,所以要除以2
rowNum += currentWord.getWord().length()/2;
currentWord = list.get(index++);
}
return currentWord;
} else {
return null;
}
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
public static void main(String[] args) {
IrParser parser = new IrParser();
parser.parse();
}
}
实验数据
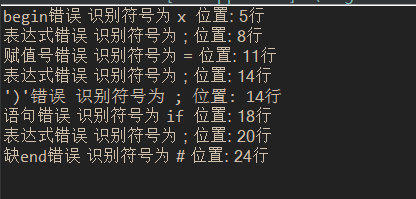
//正确测试例子
//begin a:=9; x:=2*3; b:=a+x end #
//缺begin错误
x:=a+b*c;
//表达式错误
a:=2+; x:=2*3; b:=a+x;
//赋值符号错误
a=9; x:=2*3; b:=a+x;
//')'错误 和 表达式错误
a:=9; x:=2*3; b:=(a+;
//语句错误
//if a>0 then a:=1;
if :=1;
//表达式错误
x:=4+;
//缺end错误
x:=a+b*c;
#以上的数据应该在当前项目目录下新建一个文件“input.txt”, 并且以“#”作为文件结束符


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









