



在pycharm中引入beautifulsoup库和requests库
from bs4 import BeautifulSoup
import requests
一、解析一个网页,获取网页内容(get),使用 requests 提供的方法向指定 URL 发送 HTTP 请求,返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等
若直接解析,会出现乱码

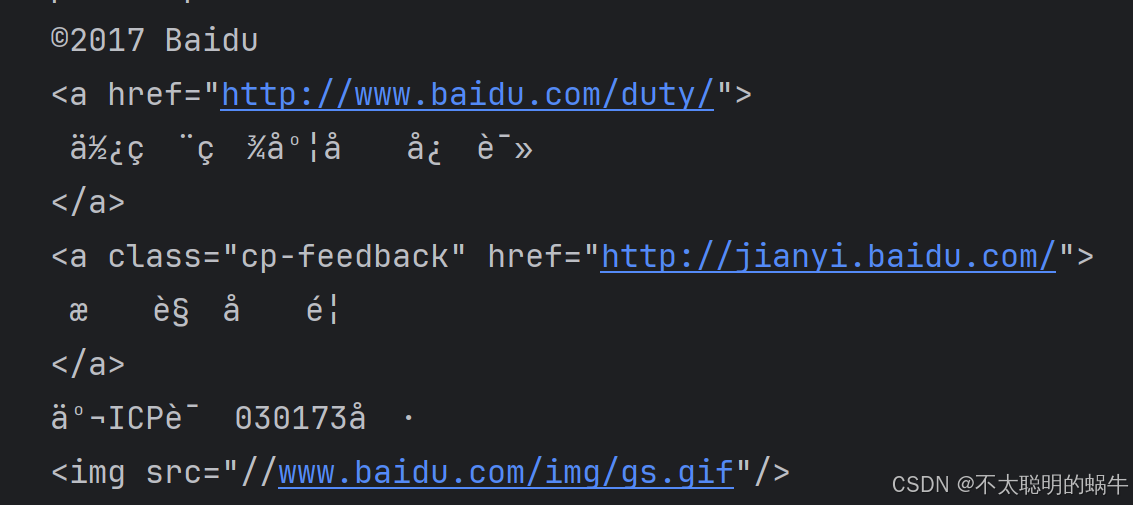
方法一:用response.content获取文本
response=requests.get("http://www.baidu.com")
html=response.content
方法二:正确解码(通用)
apparent_encoding获取网页源码的编码方式,encoding从网页响应的header中,提取charset字段中的编码,若header中没有charset字段,则默认为ISO-8859-1编码模式,ISO-8859-1编码无法解析中文,这也是中文乱码的原因。response.encoding=response.apparent_encoding表示希望用apparent_encoding解析网页
response=requests.get("http://www.baidu.com")
response.encoding=response.apparent_encoding
html=response.text
二、创建BeautifulSoup对象,传递网页内容以及解析的方法
html.parser是一个用于解析HTML的解析器
bs = BeautifulSoup(html, 'html.parser')
三、prettify 方式输出页面
prettify()方法接受一个可选的参数encoding,它允许你指定输出字符串的编码方式。如果不提供这个参数,默认情况下会使用UTF-8编码
print(bs.prettify()) # prettify 方式输出页面
四、全部代码
from bs4 import BeautifulSoup
import requests
response=requests.get("http://www.baidu.com")
response.encoding=response.apparent_encoding
html=response.text
bs = BeautifulSoup(html, 'html.parser')
print(bs.prettify()) # prettify 方式输出页面


















 56万+
56万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









