






概述
yolov3.yaml是整个yolov3的建筑蓝图,其中源码中定义了大楼的整体结构等详细信息
主要模块总结
- Backbone(骨架结构)
- 作为建筑的主要框架,负责提取输入图像的基本特征,支撑整个模型的运行
- Head(检测头)
- 结合 PANet 和 Detect 模块,检测头部分确保了模型在不同尺度上的检测能力和准确性
- 作为建筑的设施和功能区,负责将骨架结构提取的特征进行融合和处理,最终实现目标检测
- Parameters(模型参数)
- 定义建筑的规模和结构比例,通过调整深度和宽度系数,实现不同复杂度的模型设计
- Anchors
- 预定义的边界框尺寸,用于在不同尺度的特征图上进行目标检测
模块分析
模型参数
# Parameters
nc: 20 # 模型识别的类别数量
depth_multiple: 1.0 # 模型深度参数
width_multiple: 1.0 # 模型通道参数参数解释
- nc:指定模型需要识别的不同类别数量
- 一栋建筑中有多少个不同的房间类型,也就是最后需要识别多少个种类
- depth_multiple:用于调整模型的深度(层数)的缩放因子
- 调整楼层数,从而适应不同规模的项目需求
- 源码中对参数设置成1.0,则表示模型的深度保持原样,不进行缩放
- 可以通过调整该参数,实现增减模型的层数
- width_multiple:用于调整模型的宽度(通道数)的缩放因子
- 类似于调整建筑中走廊和通道的宽度,从而适应不同的人流量和空间需求
- 源码中默认设置成1.0表示模型的通道数保持原样。通过调整该参数,可以增加或减少卷积通道的宽度,类似于调整建筑中走廊的宽度来适应不同的使用需求
Anchors
参考YOLOv3原理中对于章节,Anchors就是预定义的边界框尺寸, 主要用于在不同尺寸的特征图上进行目标检测,从而加快检测速度
# yolov3初始化了9个anchors,在三个Detect层使用(3个feature map)中使用,每个feature map的每个grid_cell都有三个anchor进行预测。
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32详细分析
- 如果按照建筑的事例分析,那么这里就类似于不同尺寸和位置的支柱,用于支撑不同区域的负载,确保建筑的稳定性
Backbone
基于Darknet-53搭建骨干网络,简单来说就是通过逐渐增大卷积核和不符图像特征提取并向下采样,随着层数的增加就会使用更多的Botteneck模块提取深层次的特征,也会逐渐增加通道数

# darknet53 backbone 配置
backbone:
# [from, number, module, args]
# from: 表示当前模块的输入来自哪一层的输出,-1 表示来自上一层的输出。
# number: 表示本模块的理论重复次数,1 表示只有一个,3 表示重复 3 次。实际的重复次数为 number × depth_multiple。
# module: 模块名,指明使用哪个模块进行网络的搭建,可以通过该类名在 common.py 中找到相应的实现。
# args: 在网络搭建过程中,模块的参数列表,包括 channel(通道数)、kernel_size(卷积核大小)、stride(步幅)、padding(填充)、bias(偏置)等。
[[-1, 1, Conv, [32, 3, 1]], # 0: 第 0 层,输入来自上一层(-1),进行 1 次卷积操作,输出通道为 32,卷积核大小为 3x3,步幅为 1
[-1, 1, Conv, [64, 3, 2]], # 1: 第 1 层,输入来自上一层,进行 1 次卷积操作,输出通道为 64,卷积核大小为 3x3,步幅为 2(下采样)
[-1, 1, Bottleneck, [64]], # 2: 第 2 层,输入来自上一层,进行 1 次 Bottleneck 模块,输出通道为 64(Bottleneck 模块有更多卷积结构,用于提升网络的表示能力)
[-1, 1, Conv, [128, 3, 2]], # 3: 第 3 层,输入来自上一层,进行 1 次卷积操作,输出通道为 128,卷积核大小为 3x3,步幅为 2(下采样)
[-1, 2, Bottleneck, [128]], # 4: 第 4 层,输入来自上一层,进行 2 次 Bottleneck 模块,输出通道为 128
[-1, 1, Conv, [256, 3, 2]], # 5: 第 5 层,输入来自上一层,进行 1 次卷积操作,输出通道为 256,卷积核大小为 3x3,步幅为 2(下采样)
[-1, 8, Bottleneck, [256]], # 6: 第 6 层,输入来自上一层,进行 8 次 Bottleneck 模块,输出通道为 256
[-1, 1, Conv, [512, 3, 2]], # 7: 第 7 层,输入来自上一层,进行 1 次卷积操作,输出通道为 512,卷积核大小为 3x3,步幅为 2(下采样)
[-1, 8, Bottleneck, [512]], # 8: 第 8 层,输入来自上一层,进行 8 次 Bottleneck 模块,输出通道为 512
[-1, 1, Conv, [1024, 3, 2]], # 9: 第 9 层,输入来自上一层,进行 1 次卷积操作,输出通道为 1024,卷积核大小为 3x3,步幅为 2(下采样)
[-1, 4, Bottleneck, [1024]], # 10: 第 10 层,输入来自上一层,进行 4 次 Bottleneck 模块,输出通道为 1024
]Head检测头
检测头部分类似于建筑物中的电梯,实现将不同楼层连接起来。YOLOv3中的head则是结合了 PANet 和 Detect 模块,负责融合来自不同尺度的特征图,并进行最终的目标检测。head 部分通过一系列卷积、Bottleneck、上采样、拼接(Concat)等模块,将骨干网络提取的多层次特征融合起来,确保模型在不同尺度上都能准确检测目标
# YOLOv3 head
# head = PANet+Detect 作者没有区分neck模块,所以head部分包含了PANet+Detect部分
# [from, number, module, args]
# from: 表示当前模块的输入来自那一层的输出,-1表示来自上一层的输出。不过这里可以为list,就是这层的输入由所层输出concat而来。
# number:表示本模块的理论重复次数,1表示只有一个,3表示重复3次。实际的重复次数:number×depth_multiple
# module:模块类名,通过这个类名去common.py中寻找相应的类,进行模块化的搭建网络。
# args:是一个list,是模块搭建所需参数的列表,包括channel,kernel_size,stride,padding,bias等
head:
[[-1, 1, Bottleneck, [1024, False]],
[-1, 1, Conv, [512, [1, 1]]],
[-1, 1, Conv, [1024, 3, 1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P4
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 1, Bottleneck, [256, False]],
[-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
[[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
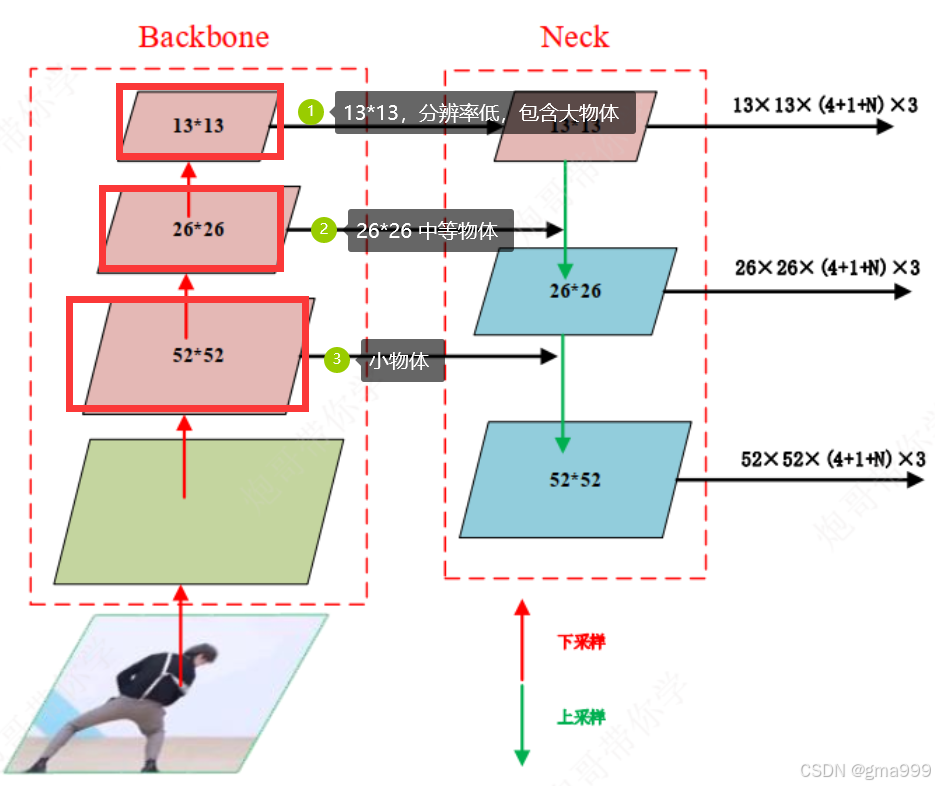
]分析:P5 - 13*13在代码中并没有像p4 p3一样进行了融合(重要)
P5经过特征处理后,直接进入了detect层,用于检测大目标。因为P5 的低分辨率和高语义特征使其更适合直接用于检测,而不是通过上采样融合。P3 和 P4 的融合是为了弥补这些层次的特征图语义不足的问题,而 P5 已经是最深层的特征,因此无需进一步融合
对应关系
- P5:特征图大小为 13×13,分辨率最低,包含大目标的信息
- P4:特征图大小为 26×26,分辨率适中,包含中等目标的信息
- P3:特征图大小为 52×52,分辨率最高,包含小目标的信息
首先处理高分辨率特征图 (P5)
- Bottleneck:增强特征提取能力,提升网络的非线性表达能力,输入和输出通道数都为 1024
- Conv:多次卷积操作,包括 1x1 和 3x3 的卷积核,分别用于减少通道数和增加感受野
- 最终生成处理过的 P5 特征图(即 large scale,用于检测大目标)
[[-1, 1, Bottleneck, [1024, False]],
[-1, 1, Conv, [512, [1, 1]]],
[-1, 1, Conv, [1024, 3, 1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)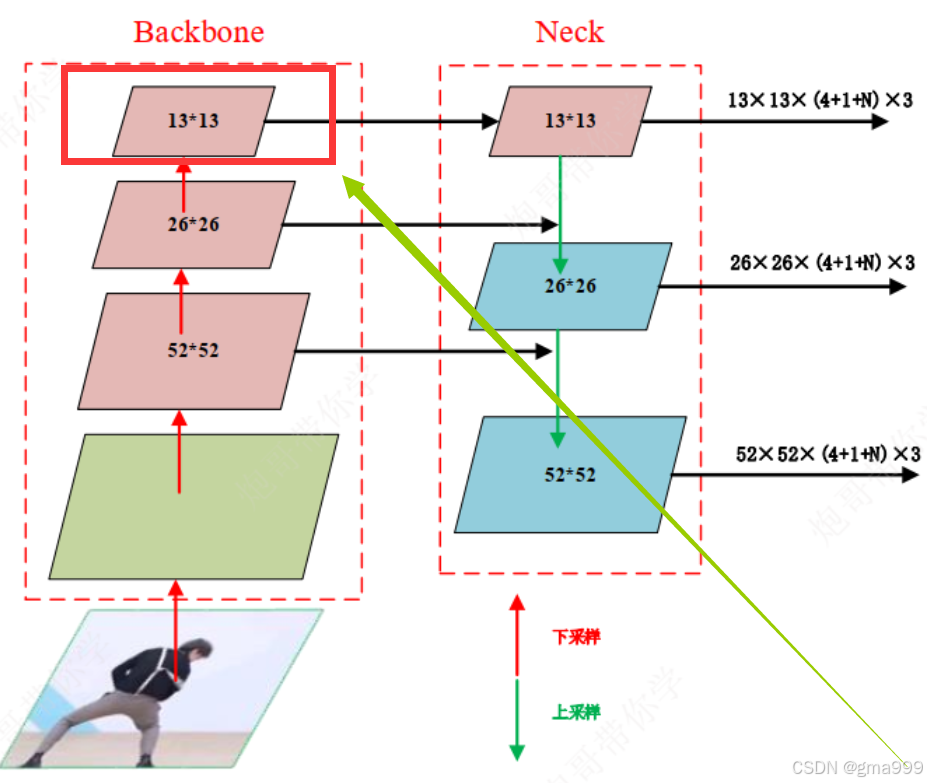
将 P5 上采样后与 P4 拼接

- P5(13×13) → P4(26×26)融合
- 首先将p5特征图通过1*1卷积降低通道数
- 然后通过nn.Upsample上采样,使 P5 特征图的大小变为 26×26,与 P4 特征图分辨率一致
- 然后将上采样的p5和Backbone基中的94
# 将 P5 特征图上采样后与 P4 拼接
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]],
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [512, 3, 1]],P4(26×26) → P3(52×52)融合
# 将 P4 特征图上采样后与 P3 拼接
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]],
[-1, 1, Bottleneck, [256, False]],
[-1, 2, Bottleneck, [256, False]],
















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









