




 本文详细介绍了Java虚拟机中的内存结构,包括程序计数器、栈内存、线程运行时的CPU占用诊断、本地方法栈、堆内存及其溢出处理,以及方法区和StringTable的特性和优化。重点讲解了栈内存溢出、递归调用、堆内存管理工具和字符串对象池的使用。
本文详细介绍了Java虚拟机中的内存结构,包括程序计数器、栈内存、线程运行时的CPU占用诊断、本地方法栈、堆内存及其溢出处理,以及方法区和StringTable的特性和优化。重点讲解了栈内存溢出、递归调用、堆内存管理工具和字符串对象池的使用。
内存结构笔记 1
0、 程序计数器
- Program Counter Register 程序计数器(寄存器)
- 作用:记住下一条jvm指令的执行地址
- 是线程私有的
- CPU会为每个线程分配时间片,当前线程的时间片使用完以后,CPU就会去执行另一个线程中的代码
- 程序计数器是每个线程所私有的,当另一个线程的时间片用完,又返回来执行当前线程的代码时,通过程序计数器可以知道应该执行哪一句指令
- 不会存在内存溢出
一、栈内存溢出
-
栈内存溢出:java.lang.StackOverflowError
-
栈帧过多导致栈内存溢出:如没有终止条件的方法递归调用等
-
栈帧过大导致栈内存溢出
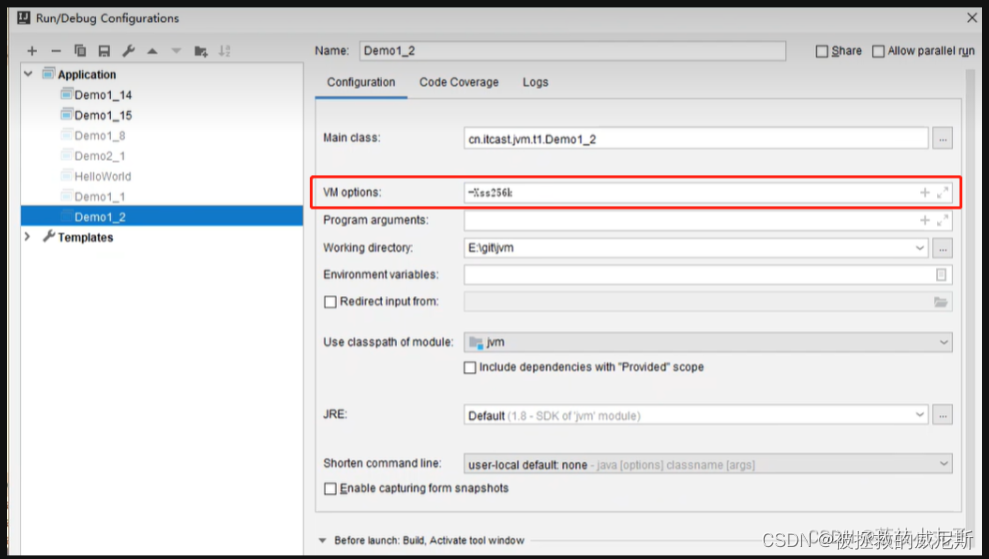
-
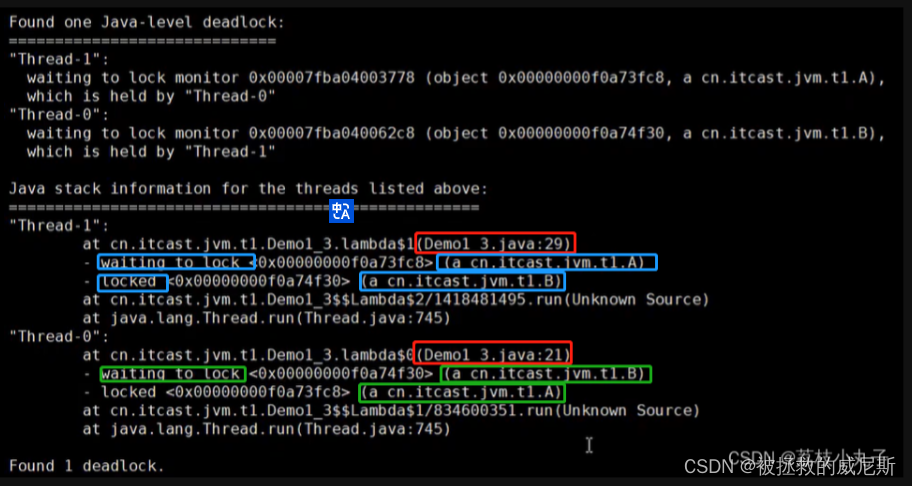
二、线程运行诊断
CPU占用高
- 用
top定位哪个进程对cpu的占用过高 ps H -eo pid,tid,%cpu | grep 进程id:用ps命令进一步定位是哪个线程引起的cpu占用过高(可以得到十进制的线程id)
- jstack 进程id
可以根据线程id(此时的线程id为十六进制,在匹配时需要将上一步得到的十进制的换算为十六进制) 找到有问题的线程,进一步定位到问题代码的源码行号
三、本地方法栈
在java虚拟机调用一些本地方法时需要给本地方法提供的内存空间
- 本地方法:由于java有限制,不可以直接与操作系统底层交互,所以需要一些用c/c++编写的本地方法与操作系统底层的API交互,java可以间接的通过本地方法来调用底层功能
- 举例:Object的clone()、hashCode()、notify()、notifyAll()、wait()等

四、 堆内存溢出
堆内存溢出:java.lang.OutofMemoryError :java heap space.
- 可以通过参数-Xmx来控制程序堆的大小
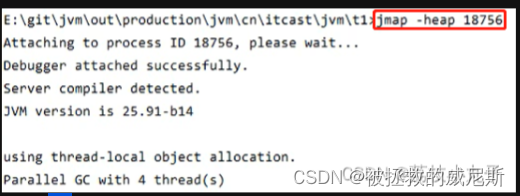
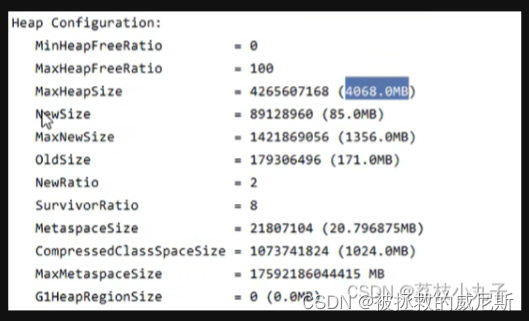
五、堆内存诊断
jps工具:查看当前系统中有哪些java进程

jmap工具:查看某一时刻堆内存占用情况
jconsole工具:图形界面的,多功能的监测工具,可以连续监测
jvisualvm工具
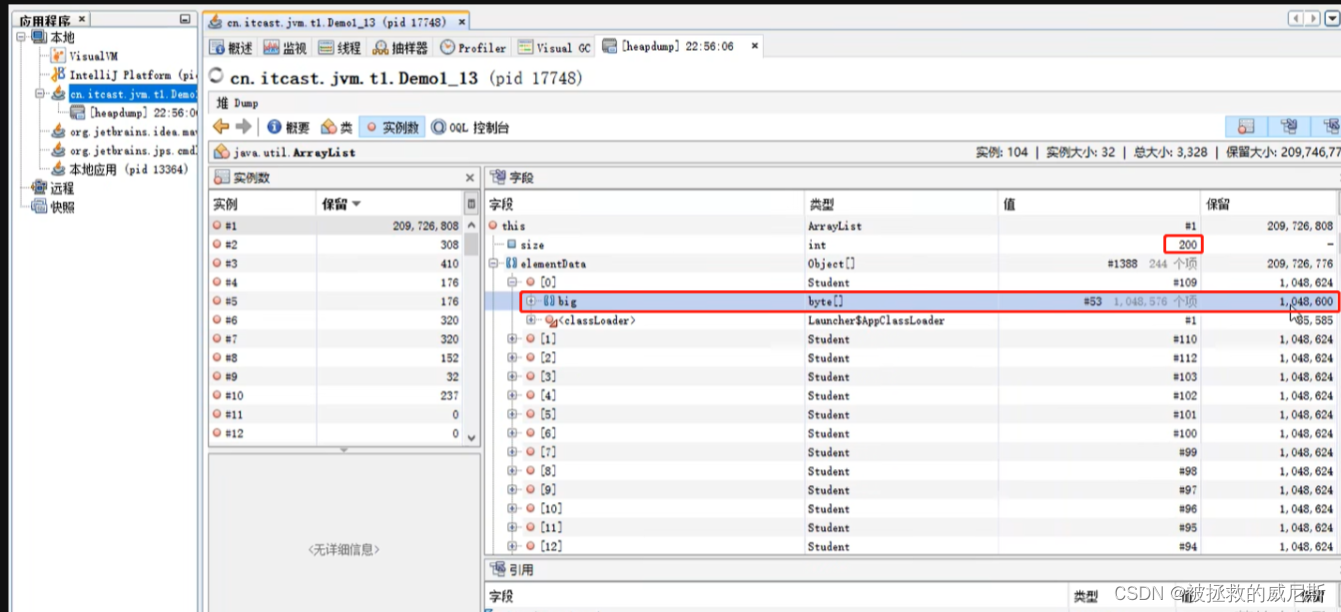
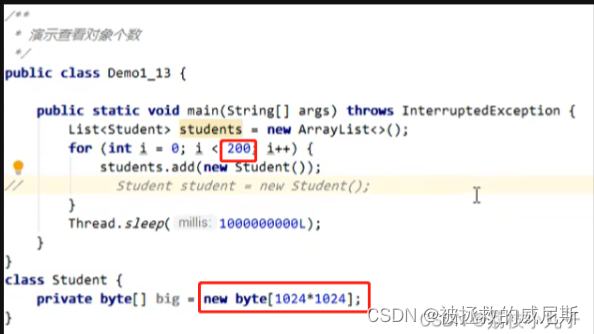
查看占用内存最大的对象:ArrayList
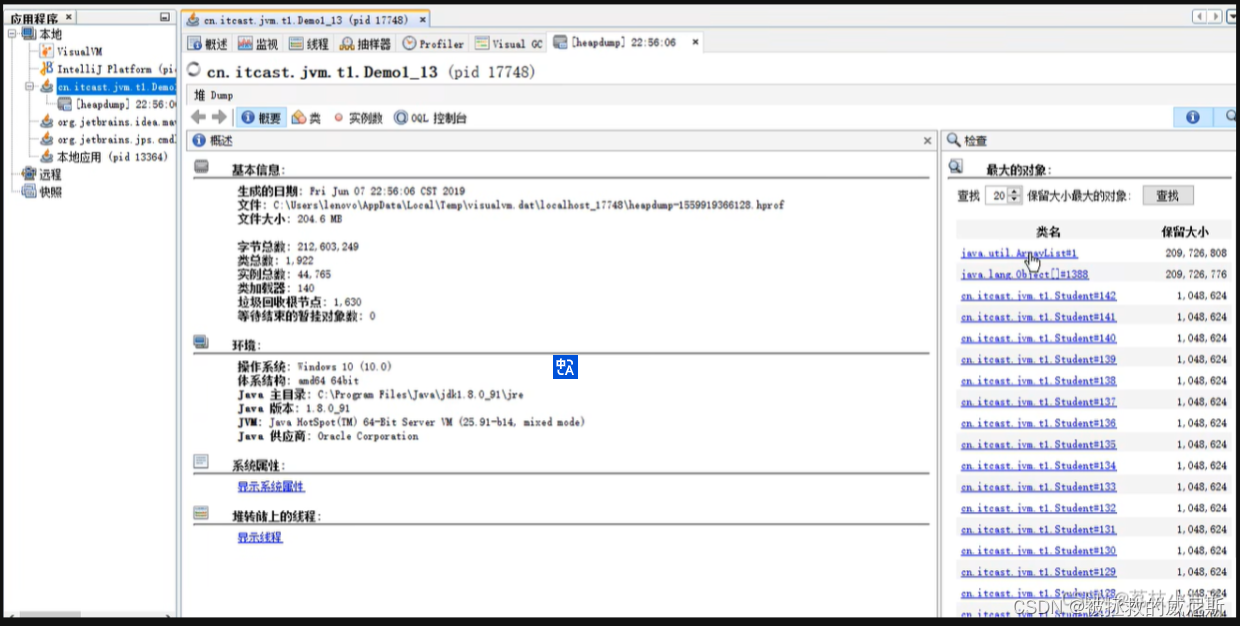
ArrayList中的元素Student对象中包含的big属性占用1M内存,共有200个元素,占用200M内存
6、方法区定义
- 所有java虚拟机线程的共享区域
- 存储类的结构的相关信息,如运行时常量池、成员变量、方法数据、成员方法和构造器的代码等
- 方法区在虚拟机启动时创建,其逻辑上是堆的一个组成部分,但在实现时不同的JVM厂商可能会有不同的实现
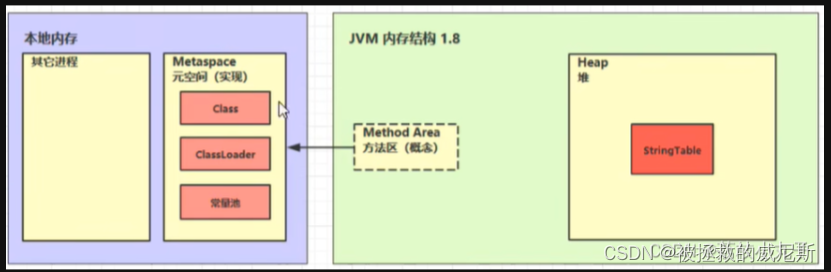
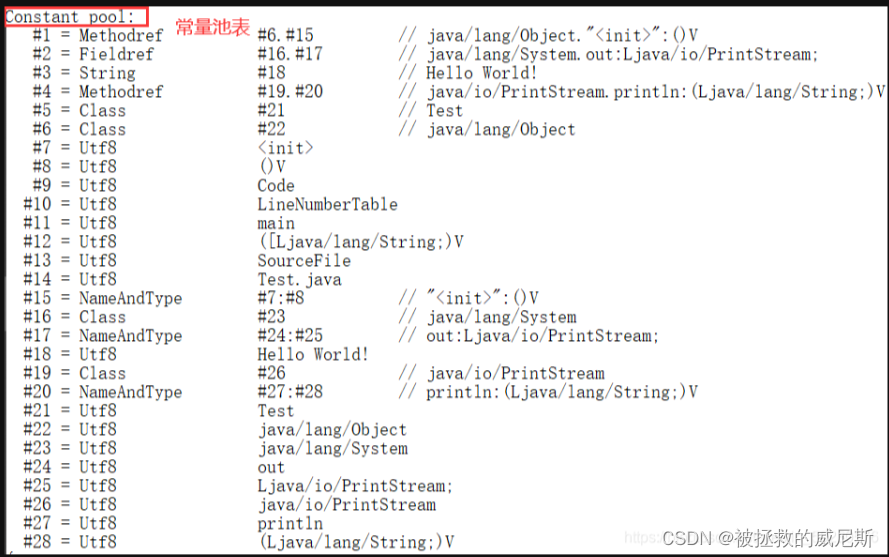
- 常量池:常量池,就是一张表,存储在*.class字节码文件中。虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
- 运行时常量池:常量池是*.class文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
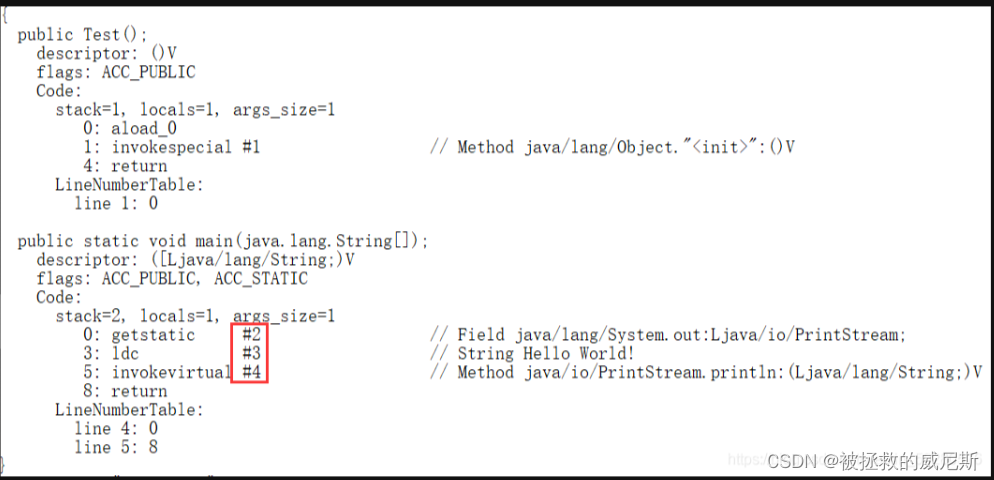
7、StringTable
-
常量池中的字符串仅是符号,第一次用到时才变为对象。
-
利用串池的机制,来避免重复创建字符串对象
package cn.itcast.jvm.t1.stringtable;
// StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容
public class Demo1_22 {
// 常量池中的信息,都会被加载到运行时常量池中, 这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象
// ldc #2 会把 a 符号变为 "a" 字符串对象
// ldc #3 会把 b 符号变为 "b" 字符串对象
// ldc #4 会把 ab 符号变为 "ab" 字符串对象
public static void main(String[] args) {
String s1 = "a"; // 懒惰的, 运行到此行才会创建字符串对象放入串池
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab")
String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为ab
System.out.println(s3 == s4);//false
System.out.println(s3 == s5);//true
}
}
-
对于字符串变量拼接
String s4 = s1 + s2;:原理是 StringBuilder (1.8)- 其过程为:
new StringBuilder().append("a").append("b").toString(),即`new String(“ab”),其应当存储在堆中,而不是常量池
- 其过程为:
-
对于字符常量拼接
String s5 = "a" + "b";:原理是编译期优化- javac 在编译期间的优化,结果已经在编译期确定为
"ab",因此会直接找到常量池中的值
面试题
- javac 在编译期间的优化,结果已经在编译期确定为
package cn.itcast.jvm.t1.stringtable;
public class Demo1_21 {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b"; // ab
String s4 = s1 + s2; // new String("ab")
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4); // false
System.out.println(s3 == s5); // true
System.out.println(s3 == s6); // true
String x2 = new String("c") + new String("d"); // new String("cd")
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢//调换位置后:true//jdk1.6:false
System.out.println(x1 == x2);//false
}
}
- jdk1.6时,StringTable是常量池的一部分,随常量池存储在永久代中;jdk1.7/jdk1.8时StringTable从永久代转移到了堆中。
- 永久代内存回收效率很低,只有Full GC时才会触发永久代的垃圾回收,而Full GC只有在整个老年代的空间不足时才会触发,时机较晚。而StringTable使用频繁,其中存储着大量字符串常量,若其回收效率不高就会占用大量内存,导致永久代内存不足。因此jdk1.7 / jdk1.8开始将StringTable从永久代转移到了堆中,只需要Minor GC就会对用不到的字符串进行堆垃圾回收,减轻了字符串对内存的占用。
StringTable调优
调整 -XX:StringTableSize=桶个数
StringTable是由HashTable实现的,所以可以适当增加HashTable桶的个数,来减少字符串放入串池所需要的时间
考虑将字符串对象是否入池
若字符串对象很多且大量重复,可以考虑使用intern方法将字符串入池,减少重复对象

















 3890
3890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









