







前言
初学大数据组件Hive,对Hive没有一个系统的认知,因此决定对Hive进行一个总结,以便于加深对Hive的理解
一、Hive简介
1.1为什么要使用Hive
1.传统数仓的缺点
- 无法满足快速增长的海量数据存储需求
- 无法有效处理不同类型的数据
- 计算和处理能力不足
2.HDFS+Hadoop的不便
因为传统数仓的不足,大家希望使用上分布式存储,也就是HDFS。然而使用HDFS后发现,基于数据库的数据仓库用SQL就能做查询,现在换到HDFS上面,只能用Mapreduce任务去做分析。给分析代码极大的不便,因此需要一个框架,使用SQL来做HDFS的查询。Hive正是基于类似SQL的语言完成对hdfs数据的查询分析的框架
1.2Hive的优缺点
| 优点 | 缺点 |
|---|---|
| 1、高可靠、高容错:HiveServer采用集群模式。双MetaStor。超时重试机制。 | 1、延迟较高:默认MR为执行引擎,MR延迟较高。 |
| 2、类SQL:类似SQL语法,内置大量函数。 | 2、不支持雾化视图:Hive支持普通视图,不支持雾化视图。Hive不能再视图上更新、插入、删除数据。 |
| 3、可扩展:自定义存储格式,自定义函数。 | 3、不适用OLTP:暂不支持列级别的数据添加、更新、删除操作。 |
| 4、多接口:Beeline,JDBC,ODBC,Python,Thrift。 | 4、暂不支持存储过程:当前版本不支持存储过程,只能通过UDF来实现一些逻辑处理。 |
二、Hive的工作原理
Hive是Hadoop生态的一员,依托于Hadoop生态,赋予了其强大的生命力。Hive与其他Hadoop组件的关系为:
Hive依赖于HDFS 存储数据
Hive依赖于MapReduce 处理数据
在某些场景下Pig可以作为Hive的替代工具
HBase 提供数据的实时访问
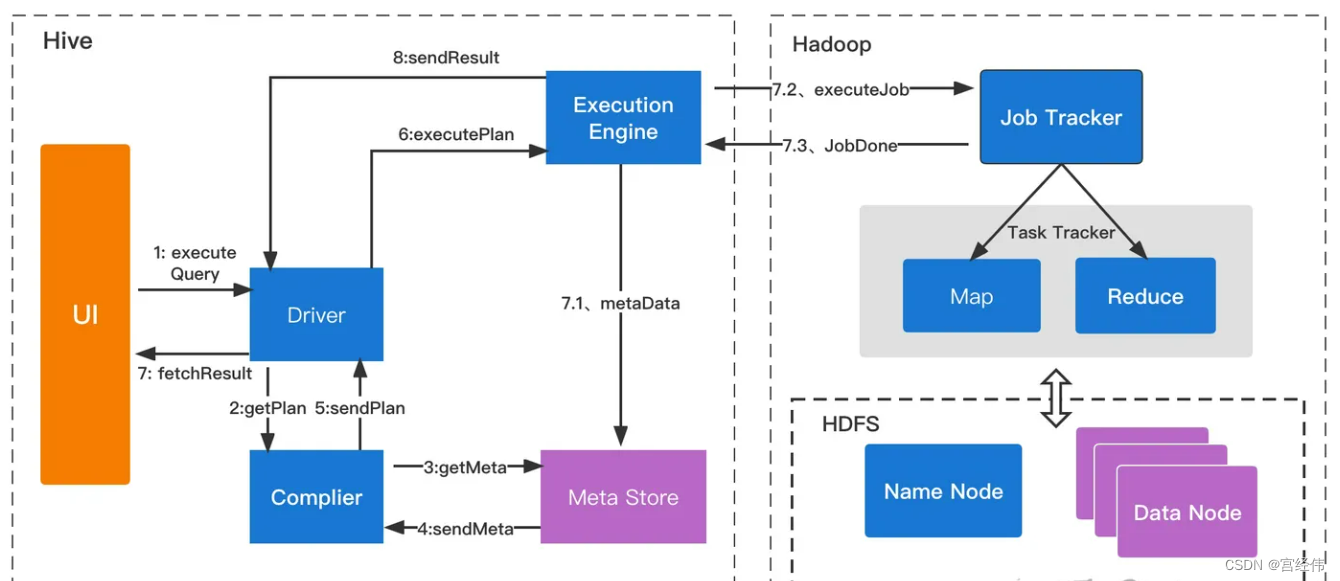
执行流程:
- ExecuteQuery(执行查询操作):命令行或Web
UI之类的Hive接口将查询发送给Driver(任何数据驱动程序,如JDBC、ODBC等)执行; - GetPlan(获取计划任务):Driver借助编译器解析查询,检查语法和查询计划或查询需求;
- GetMetaData(获取元数据信息):编译器将元数据请求发送到Metastore(任何数据库);
- SendMetaData(发送元数据):MetaStore将元数据作为对编译器的响应发送出去;
- SendPlan(发送计划任务):编译器检查需求并将计划重新发送给Driver。到目前为止,查询的解析和编译已经完成;
- ExecutePlan(执行计划任务):Driver将执行计划发送到执行引擎;
- FetchResult(拉取结果集):执行引擎将从datanode上获取结果集;
- SendResults(发送结果集至driver):执行引擎将这些结果值发送给Driver;
- SendResults (driver将result发送至interface):Driver将结果发送到Hive接口(即UI);
三、Hive的基础命令
1、Hive的命令说明
1.执行完立刻退出
使用hive -e 的形式
hive -e 'select count(*) from test'
2.不需看到其他无关紧要的信息
hive -S -e 'select count(*) from test'
3.一次性执行多个查询语句,可以将这些查询语句保存到后缀为sql的文件中,利用hive -f来一次性执行
hive -f test.sql
4.可以用"–"开头的字符串对Hive脚本进行注释
select count(*) from test --count the test table
5.查看Hive的使用方式
hive --help --service cli
6.Hive的分隔符
- \n: 换行符
- ^A(Ctrl+A): 在文本中以八进制编码\001表示,列分隔符
- ^B(Ctrl+B): 在文本中以八进制编码\002表示,作为分隔ARRAY、STRUCT中的元素,或者MAP中键值对的分隔
- ^C(Ctrl+C): 在文本中以八进制编码\003表示,用于MAP中键值对的分隔
2、对数据库的操作
1.1新建数据库
create database db_name;
如果数据库存在,将将抛出一个错误信息,可以使用如下语句避免:
create database if not exists db_name
数据库在HDFS上的目录都是以.db结尾
如果想针对某个数据库改变其存放位置,可以如下命令在建表时修改默认存放位置:
create database db_name location '/user/hadoop/temp';
如果想查看某个已存在的数据库,可以使用如下命令:
describe database db_name
查看存在的表结构
describe db_name
1.2删除数据库
drop database db_name;
1.3 显示数据库
show databases;
1.4 指定使用数据库
use db_name;
2.对表的操作
2.1创建内部表
use db_name;
#(filedName, filedType)
create table table_name (id int,name string,age int);
# 设置分隔符
row format delimited;
field terminated by ',';
# 展现数据表
desc db_name.table_name
如果我们用 drop 命令把表删除,这样将会把表以及表里面的数据和表的元数据都一起删除。
2.2 创建外部表
create external table t_ex_1(id int,name string,age int)
row format delimited
fields terminated by 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









