




如果你从事数据科学领域,那么获取数据对于你来说就不可或缺,网络爬虫这一关你必须得过,而说到爬虫,大多数人想到的就是Python,因为python不仅编写调试方便,而且能够快速入门,最主要的是相关的类库十分丰富
今天,要和大家推荐的这个项目就是和Python编程有关的,这个项目介绍了如何用 Python 登录各大网站,并用简单的爬虫获取一些有用数据,目前该项目已经提供了知乎、B 站、和豆瓣等 18 个网站的登录方法。

模拟登陆基本采用的是直接登录或者使用selenium+webdriver的方式,有的网站直接登录难度很大,比如qq空间,bilibili等如果采用selenium就相对轻松一些。
每一个网站都会有对应的登录代码,有的还有数据的爬取代码。下面我们以淘宝为例:
爬取淘宝各子标签,按销量排名商品信息,按分类保存至MongoDB
通过pandas进行数据分析
将商品在各省分布、销量排行、地图分布等通过matplotlib绘图显示
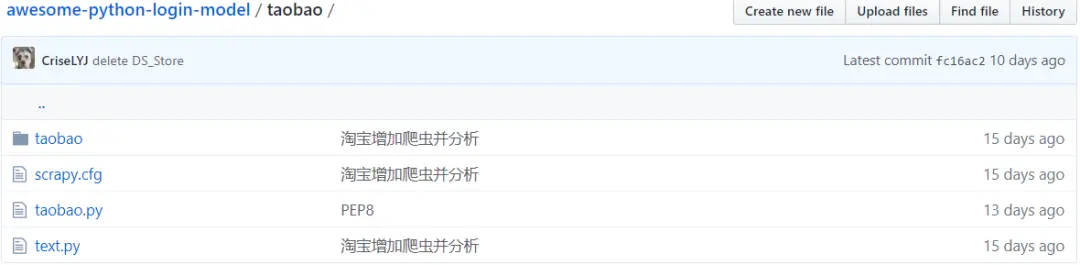
以上是淘宝爬虫相关的文件:
taobao.py为模拟登录
剩下的文件为爬虫
模拟登陆的代码如下:

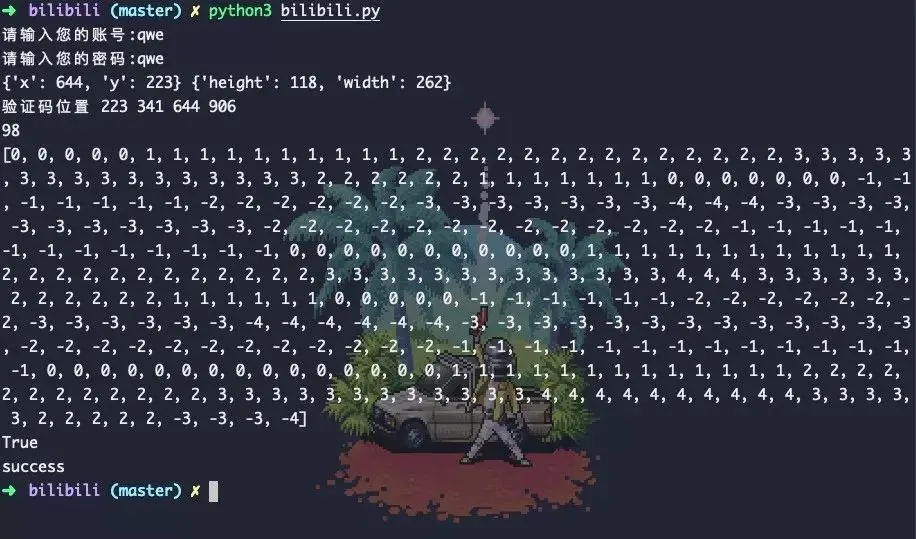
Bilibili自动登录测试正常,成功率98%

如果你还想查看更多示例,可以前往GitHub详情页,而且创建者也鼓励广大开发者提 Issue 或 Pull Requests。
项目地址:https://github.com/CriseLYJ/awesome-python-login-model
来源:开源最前线

欢迎关注我的公众号:【编程资源库】 ,关注后回复“我来自互联网”即可领取2000G视频教程

















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









