



 文章介绍了OpenAI开源的Whisper语音识别模型及其在33字幕、MemoAI和幕译客户端中的应用。33字幕提供全面的字幕功能,MemoAI适合有笔记需求者,而幕译专注于基础识别,GPU加速需会员。
文章介绍了OpenAI开源的Whisper语音识别模型及其在33字幕、MemoAI和幕译客户端中的应用。33字幕提供全面的字幕功能,MemoAI适合有笔记需求者,而幕译专注于基础识别,GPU加速需会员。
Whisper 是 OpenAI 开源的一个强大的通用语音识别模型,它使用了超过 68 万小时多语言来训练,支持了 99 种不同语言的转录,够实现高准确性的语音识别,尤其对于英文,识别度接近人类水平。
下面给大家推荐 3 款集成了这个模型的客户端。
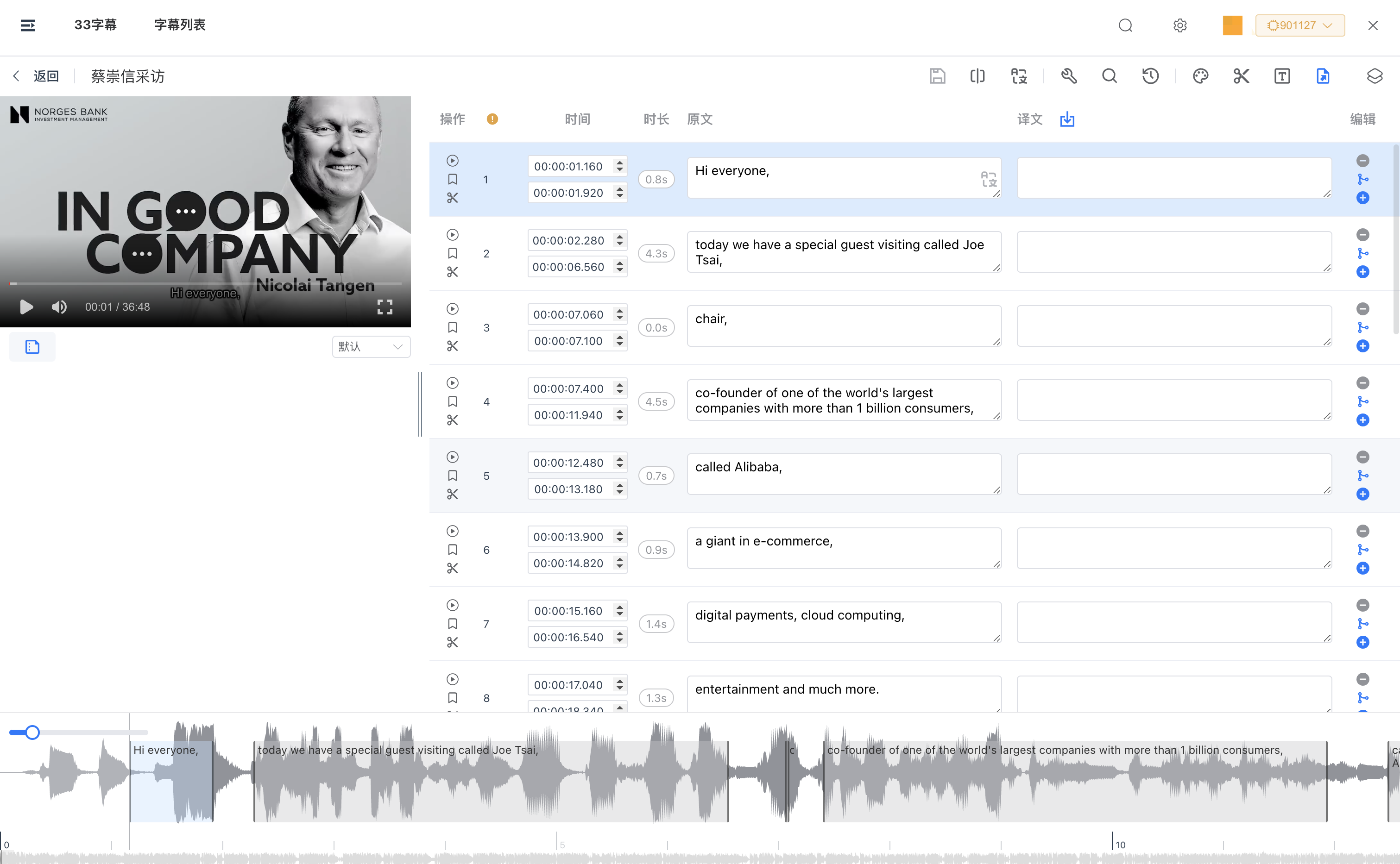
33字幕
33字幕是一款非常强大的字幕工具,除了云端识别,它也同时支持Whisper离线模型识别。
它是唯一一个同时集成了 Whisper.CPP 和 FasterWhisper 两种离线识别引擎的客户端,并且还在这个基础上做了许多优化。
比如 Whisper 的时间戳不准确的问题,在33字幕中,通过选用 FasterWhisper,你会发现时间戳会变得准确许多,另外幻觉文本,断句等问题也得到了极大的改善。
除了基础的语音识别能力,33字幕还有完备的字幕编辑、字幕翻译、内容总结、压制字幕、字幕搜索、剪切片段等强大的功能。
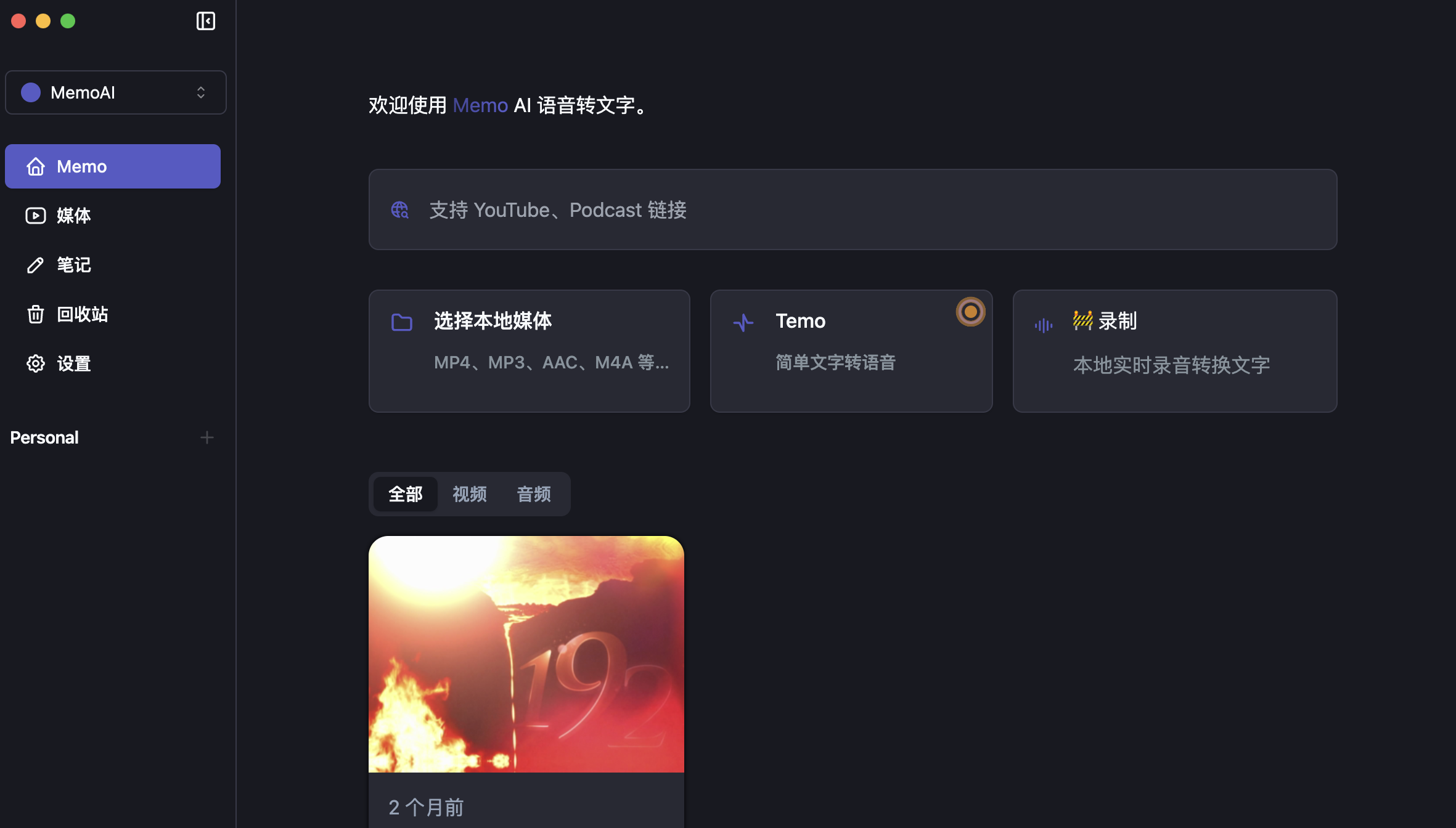
MemoAI
MemoAI 是一款优秀的离线语音转文字应用,它集成的是 Whisper.CPP 引擎。
它具备有如下的特性:
- 可以将 YouTube、播客等视频转录成文字。
- 文字翻译:能够将文字翻译成多种语言。
- 笔记功能:在音视频播放过程中可以添加笔记和注释。
- 支持实时字幕显示,并可进行校准、剪辑和导出。
- 利用 ChatGPT 对转译后的内容进行摘要。
MemoAI的体验非常好,不过由于 Whisper.CPP 的时间戳问题有时候会比较严重,所以它也会有这个问题,另外它的GPU加速需要会员才能开启。
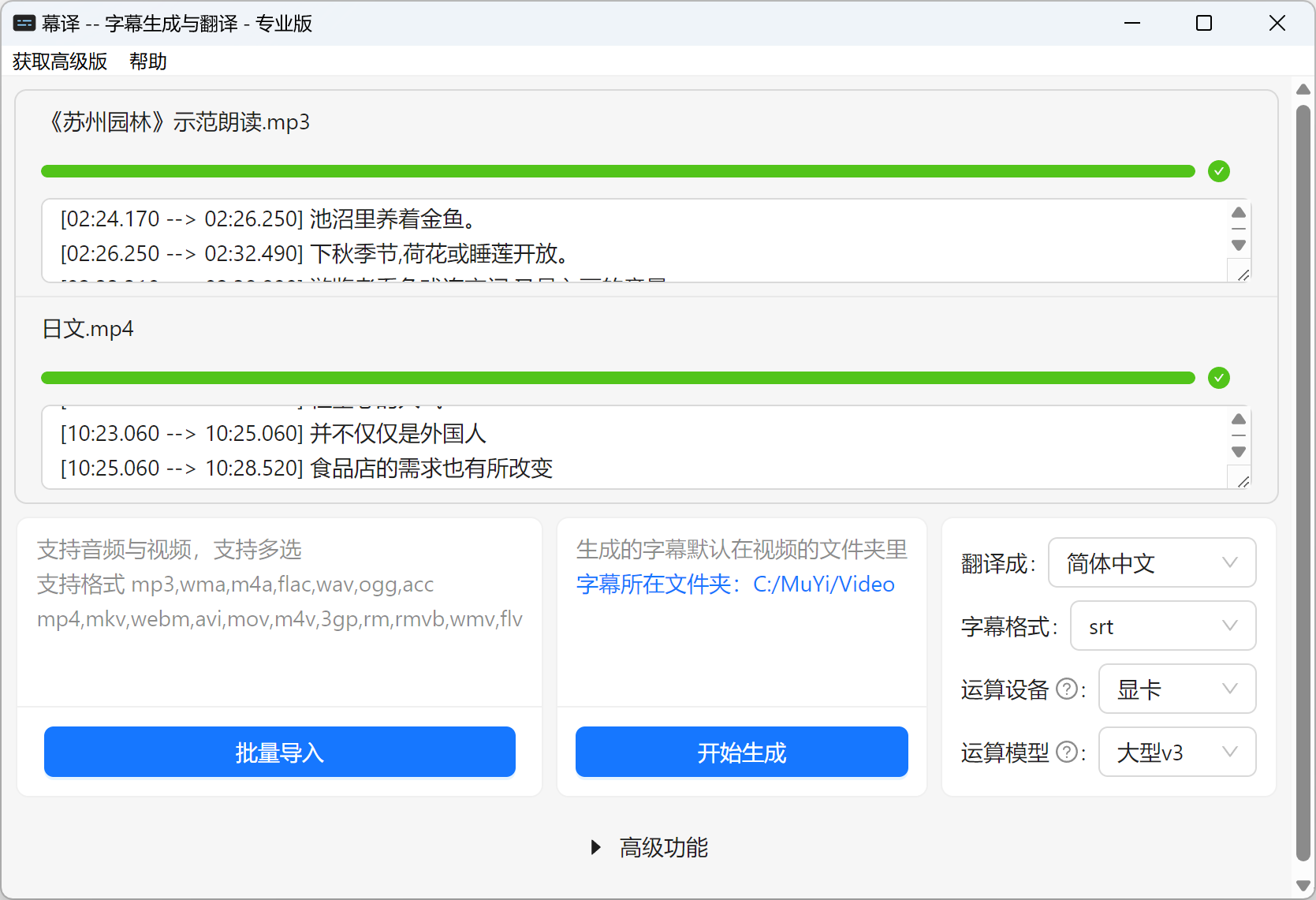
幕译
幕译是一款集成了 FasterWhisper 的离线客户端应用,它目前只有基础的语音识别能力,对于后期修正起来可能会比较麻烦。
无论是什么模型,它都有支持GPU加速,但是使用大模型需要会员。
综上所述,如果你是想制作字幕或者单纯把语音转文字,我们首先推荐你试一下33字幕,它的字幕功能是最齐备的。如果你需要一些笔记的功能,那么Memo AI是个不错的选择。

















 3572
3572




 到【灌水乐园】发言
到【灌水乐园】发言







