




 本文探讨了词义表示的方法,包括one-hot编码的问题、分布式语义的概念、词嵌入的原理及其在NLP任务中的应用。介绍了WordEmbedding、CBOW、SG、Glove、fastText等模型,并对比了它们的优缺点。
本文探讨了词义表示的方法,包括one-hot编码的问题、分布式语义的概念、词嵌入的原理及其在NLP任务中的应用。介绍了WordEmbedding、CBOW、SG、Glove、fastText等模型,并对比了它们的优缺点。
如何表示词义
-
流程
文本文件->分词后的序列->词表示的向量(词嵌入)->解决具体任务的算法;
用离散符号表示词
传统NLP中,我们将词表示为一个个的离散符号,如:sun、hotel、fruit……,我们可以用one−hotone-hotone−hot方式将词代表为向量形式,如:
sun=[0,1,0,0,0,0,0,0,0,0]sun=[0,1,0,0,0,0,0,0,0,0]sun=[0,1,0,0,0,0,0,0,0,0]
hotel=[0,0,0,0,1,0,0,0,0,0]hotel=[0,0,0,0,1,0,0,0,0,0]hotel=[0,0,0,0,1,0,0,0,0,0]
此时存在问题:
- 向量之间无相似性,各个词用one−hotone-hotone−hot方式表示时,不同词之间都是正交的,不含有近似单词的信息;
- 向量维度过高,利用one−hotone-hotone−hot方式表示词向量时,向量维度等于词表中的词数,当词数量过多时,这个方法所带来的维度过高问题就会凸显出来;
分布式语义
-
分布表示的思路
语料->对共现词计数->将计数后的数据转换为向量 ->通过一系列降维方法,将高维转换为低维
-
LSA(潜在语义分析)
-
Word Embedding(词嵌入)
通过给每个单词学习一个密集向量,类似于出现在相似上下文中的单词向量,这样的词向量就叫做word embedding或者word representations;
-
模型结构图
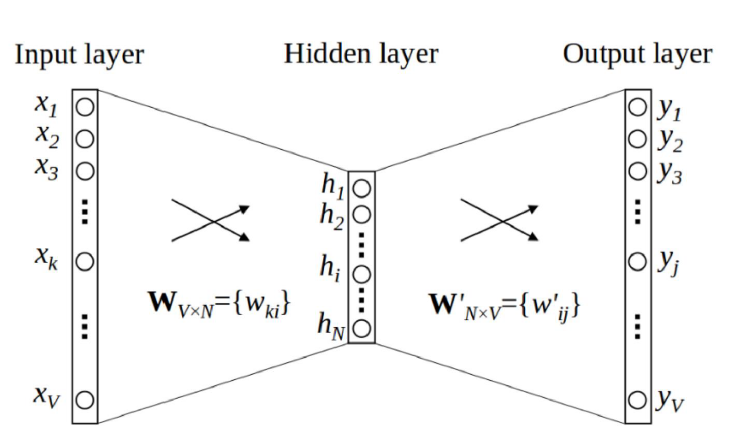
-
算法基本思想
输入层通过将大规模语料中的每个单词表示为一个密集向量,其中每个单词都是通过向量来表示,对文本进行遍历,每个位置都有一个中心词ccc和语境词表示ooo,通过利用ccc和ooo词向量之间的相似度,从而在给定ccc,计算出ooo的概率(或给定ooo,计算出ccc的概率),还需要通过调节词向量来最大化概率;
-
具体例子

在给定第ttt个位置中心词bankingbankingbanking的情况下,当窗口大小设为222时,通过给定p(wt)p(w_t)p(wt)来计算左右窗口大小为222的词的条件概率;
-
相似度
对于每个位置t=1,2,……,Tt=1,2,……,Tt=1,2,……,T,当预测固定窗口大小为mmm的上文问关联词时,给出中心词为wtw_twt,则相似度为:
L(θ)=∏t=1T∏−m<=j<=m,j≠0P(wt+j∣wt;θ),其中θ是所有需要优化的变量L(\theta)=\prod ^T_{t=1} \prod _{-m<=j<=m,j\not=0} P(w_{t+j}|w_t;\theta),其中\theta是所有需要优化的变量L(θ)=t=1∏T−m<=j<=m,j=0∏P(wt+j∣wt;θ),其中θ是所有需要优化的变量
- 目标函数(损失/代价函数)
J(θ)=−1TlogL(θ)=−1T∑t=1T∑−m<=j<=m,j≠0logP(wt+j∣wt;θ)J(\theta)=-\frac{1}{T}logL(\theta)=-\frac{1}{T}\sum^T_{t=1}\sum_{-m<=j<=m,j\not=0}logP(w_{t+j}|w_t;\theta)J(θ)=−T1logL(θ)=−T1t=1∑T−m<=j<=m,j=0∑logP(wt+j∣wt;θ)
即目标函数为负的相似度函数对数的平均值,通过最小化目标函数,从而将预测的准确率最大化;
-
预测函数
如何最小化目标函数呢?我们可以通过对预测函数的的处理来解决这一问题。对于预测函数P(wt+j∣wj,θ)P(w_{t+j}|w_j,\theta)P(wt+j∣wj,θ),可以通过用词www的两个向量来解决。我们假设VwV_wVw是中心词,UwU_wUw是语境词。则对于中心词ccc和语境词ooo而言,存在如下关系:
P(o∣c)=exp(uoTvc)∑w∈Vexp(uwTvc)P(o|c)=\frac{exp(u^T_ov_c)}{\sum_{w\in V}exp(u^T_wv_c)}P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
其中,分子中ooo和vvv的点积uoTvCu^T_o v_CuoTvC越大,则最后得到的概率P(o∣v)P(o|v)P(o∣v)越大。而分母则通过指数函数计算之后,从而实现了对整个词表的标准化;
- 实例

其中P(uproblems∣vinto)P(u_{problems}|v_{into})P(uproblems∣vinto)为P(problems∣into;uproblems,vinto,θ)P(problems|into;u_{problems},v_{into},\theta)P(problems∣into;uproblems,vinto,θ)的简写形式;

- SoftmaxSoftmaxSoftmax回归
softmax(x)i=exp(xi)∑j=1nexp(xj)=pisoftmax(x)_i = \frac{exp(x_i)}{\sum^n_{j=1}exp(x_j)}=p_isoftmax(x)i=∑j=1nexp(xj)exp(xi)=pi
softmaxsoftmaxsoftmax又称为多项逻辑回归(multinomiallogisticregressionmultinomial logistic regressionmultinomiallogisticregression),多用于分类过程,它通过将多个神经元的输出,映射到(0,1)(0,1)(0,1)区间。它通过将任意值xix_ixi映射到一个概率分布pip_ipi上,"maxmaxmax“是因为它会将输入中最大的值的概率进一步放大,而”softsoftsoft"则是因为对于输入中极小的值,它也人然后分配一些概率,而不是直接丢弃。因此,softmaxsoftmaxsoftmax函数常常用在深度学习中;
word2vec中将文本进行向量表示的方法
- CBOW(ContinuousBagofWords)CBOW(Continuous Bag of Words)CBOW(ContinuousBagofWords)

给定上下文中的词,然后预测中心词。从而利用中心词的预测结果情况,利用梯度下降方法不断调整上下文词的向量。训练完成后,每个词都作为中心词遍历了一遍,将上下文中的词向量进行调整,从而获取整个文本中所有词的向量;
- SG(Skip−Gram)SG(Skip-Gram)SG(Skip−Gram)

给定中心词,然后预测上下文中的词。从而利用上下文中的词的预测结果情况,利用梯度下降法不断调整中心词的词向量,最后文本遍历完一遍之后,就得到了所有词的词向量;
-
CBOWCBOWCBOW和SGSGSG的比较
两者均为三层神经网络(输入层、投影层和输出层)。SGSGSG中,每个词作为中心词时,是一对多的情况,多个上下文中的词对一个中心词进行“训练”,然后得出较准确地中心词的向量结果,这样最终的效果更好。CBOWCBOWCBOW中,是多对一的情况,多个上下文中的词从一个中心词处进行“学习”,这样效率更高,速度快,但是最终效果却不如SGSGSG。此外,在SGSGSG中,每个词都会受上下文词的影响,每个词作为中心词时,需要进行KKK次训练(KKK为窗口大小),所以经过多次调整将使得词向量相对更准确。CBOWCBOWCBOW预测词数和整个文本中词数几乎相等,每次预测才会进行一次反向传播。
模型优化的方法
- 分层SoftmaxSoftmaxSoftmax

用于计算softmaxsoftmaxsoftmax的方法,用二叉树(根据类标频数构造的霍夫曼树)来表示词汇表中的所有单词。如上图,其中,白色节点表示词汇表中的所有单词,而黑色节点则表示隐节点。其中VVV个单词存储于二叉树的叶子节点单元,而对于每个叶子节点,都有一条唯一的路径可以从根节点达到该叶子节点,这条路径用于计算该叶子节点所代表的单词的概率。在这个模型中,不存在单词的输出向量,而是V−1V-1V−1个隐节点中都有一个输出向量vn(w,j)‘v ^`_{n(w,j)}vn(w,j)‘,单词作为输出词的概率被定义为:
p(w=wO)=∏j=1L(w)−1σ([[n(w,j+1)=ch(n(w,j))]].vn(w,j)‘Th)p(w=w_O)=\prod ^{L(w)-1}_{j=1}\sigma([[n(w,j+1)=ch(n(w,j))]].{v^`_{n(w,j)}}^Th)p(w=wO)=j=1∏L(w)−1σ([[n(w,j+1)=ch(n(w,j))]].vn(w,j)‘Th)
其中,ch(n)ch(n)ch(n)是节点nnn的左侧子节点,vn(w,j)‘v^`_{n(w,j)}vn(w,j)‘是隐节点n(w,j)n(w,j)n(w,j)的向量表示(即“输出向量”)。而hhh则是隐藏层的输出值(SG模型中,h=vwih=v_{wi}h=vwi;CBOW模型中,h=1C∑c=1Cvwch=\frac{1}{C}\sum_{c=1}^C v_{w_c}h=C1∑c=1Cvwc),[[x]][[x]][[x]]则为一个特殊函数,其定义如下:
[[x]]={1 ,if x is true−1 , others[[x]]=\begin{cases}1\ \ ,if\ x\ is\ true\\-1\ ,\ others\end{cases}[[x]]={1 ,if x is true−1 , others
-
负采样技术
为解决数量过于庞大的输出向量的更新问题,于是在更新时不更新所有向量,而只更新他们的一个样本。正样本应该出现在我们的样本中,此外也需要加入几个单词作为负样本。而在采样的过程中,我们需要任意指定一个总体的概率分布,这个分布就叫做噪声分布,标记为Pn(w)P_n(w)Pn(w)。在word2vecword2vecword2vec中,作者用一个定义好的后多项分布的负采样形式取代简化的训练目标,从而产生高质量的嵌入:
E=−logσ(vwO‘Th)−∑wj∈Wneglogσ(−vwj‘Th)E=-log\sigma({v^`_{w_O}}^Th)-\sum_{w_j\in W_{neg}}log\sigma(-{v^`_{w_j}}^Th)E=−logσ(vwO‘Th)−wj∈Wneg∑logσ(−vwj‘Th)
其中,wOw_OwO是正样本(即输出单词),vwO‘v^`_{w_O}vwO‘是词向量。而hhh则是隐藏层的输出值(SG模型中,h=vwih=v_{wi}h=vwi;CBOW模型中,h=1C∑c=1Cvwch=\frac{1}{C}\sum_{c=1}^C v_{w_c}h=C1∑c=1Cvwc)。Wneg={wj∣j=1,…,K}W_{neg}=\{w_j|j=1,…,K\}Wneg={wj∣j=1,…,K}是从Pn(w)P_n(w)Pn(w)中采样得到的单词集合,即负样本。
GloveGloveGlove
-
定义
基于计数和直接预测的方法;
-
目标函数
J(θ)=12∑i,j=1Wf(Pij)(uiTvj−logPij)2J(\theta)=\frac{1}{2}\sum^W_{i,j=1}f(P_{ij})(u^T_iv_j-logP_{ij})^2J(θ)=21i,j=1∑Wf(Pij)(uiTvj−logPij)2
Xfinal=U+VX_{final}=U+VXfinal=U+V
其中,PijP_{ij}Pij是单词jjj出现在单词iii上下文中的概率,而f(Pij)f(P_{ij})f(Pij)则是为了去除噪声而设定的函数。
如何评价EmbeddingEmbeddingEmbedding
-
内在方式:对特定/中间子任务的评估;
-
外在方式:应用到具体任务中;
fastTextfastTextfastText分类
在文本分类任务中,fastTextfastTextfastText作为一种浅层网络,能取得媲美于深度网络的精度,但是训练时间却比深度网络快许多数量级。一般情况下,用fastTextfastTextfastText进行文本分类的同时也会产生词的embeddingembeddingembedding;
-
字符级的n−gramn-gramn−gram
word2vecword2vecword2vec中以词作为原子,为每个词生成一个向量,而忽略词内部形态特征。面对这一问题,fastTextfastTextfastText采用字符级的n−gramn-gramn−gram来表示一个单词。通过这样处理则有两个优点;
- 对于低频词,生成的词向量效果更好,其n−gramn-gramn−gram可以与其他词共享;
- 对于训练词库外的词,仍然可以构建其词向量,可通过叠加其字符级n−gramn-gramn−gram从而生成向量;
- 模型架构

类似于word2vecword2vecword2vec中的CBOWCBOWCBOW模型,只有输入层、隐藏层、输出层三层。其中,输入为多个单词表示成的向量,输出是一个特定的targettargettarget,隐藏层是对多个词向量的叠加平均。不同的是,CBOWCBOWCBOW的输入是目标词上下文中的词,而fastTextfastTextfastText的输入则是多个单词及其n−gramn-gramn−gram特征。这些特征用于表示单个文档,CBOWCBOWCBOW中输入词的是经过one−hotone-hotone−hot编码过的,输出为目标词;而fastTextfastTextfastText中输入特征则是经embeddingembeddingembedding过的特征,输出是各个文档对应的类标,且采用分层softmaxsoftmaxsoftmax优化措施,大大加快了训练速度;
-
核心思想
将整篇文档的词及n−gramn-gramn−gram向量叠加平均,从而得到文档向量,然后利用文档向量做多层softmaxsoftmaxsoftmax多分类,主要涉及到n−gramn-gramn−gram特征的引入以及分层SoftmaxSoftmaxSoftmax分类技术;
-
fastTextfastTextfastText样例
-
主要步骤
- 添加输入层(即embeddingembeddingembedding层);
- 添加隐藏层(即投影层);
- 添加输出层(即softmaxsoftmaxsoftmax层);
- 指定损失函数、优化器类型、评价指标、编译模型;
-


















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











