




 本文介绍了Diverse Branch Block(DBB),它在训练阶段使用多分支,推理阶段合并为单卷积层,能在不增加参数量的情况下提升模型效果。阐述了其基于卷积同质性和可加性的原理,包括六种转换情况,还给出了代码实现,涉及各转换及DBB类关键函数。
本文介绍了Diverse Branch Block(DBB),它在训练阶段使用多分支,推理阶段合并为单卷积层,能在不增加参数量的情况下提升模型效果。阐述了其基于卷积同质性和可加性的原理,包括六种转换情况,还给出了代码实现,涉及各转换及DBB类关键函数。
上班真的好累哦!
理论上应该从RepVGG开始写重参化的,而且上星期就打算写来着!
但是上班真的好累哦完全提不起精神在周末打字看论文!
参考教程:
https://arxiv.org/pdf/2103.13425.pdf
https://github.com/DingXiaoH/DiverseBranchBlock
介绍
diverse branch block,就如同它的名称一样,是一个block形式的设计,这个block有多种分支组合,比如卷积、多尺度卷积、平均池化等。在训练阶段是正常的每个分支都会用到,在inference阶段则会将多分支合并到一起,变成一个卷积层来进行部署,从而实现相对于单卷积层的模型,在参数量不增加的情况下,带来明显的效果提升。
早在inception net时期就已经揭示过多分支结构和不同尺度复杂度支路的组合给模型的特征提取能带来明显效果提升。但是这种复杂的结构,在inference阶段就会显得有点累赘,因为小操作太多了,与gpu的并行计算能力不太匹配,从而速度上会有所下降。
由于业务需要或硬件限制,我们并不能无限地提升我们要训练的卷积网络的大小。在评价一个网络的水平时,一般也会对它的表现、时间损耗和计算量等多方面进行评估。
作者使用重参数化的方法,在卷积网络中插入复杂的模块来提高它的表现能力,同时保证原来的预测时间不会增加。通过“在训练阶段复杂化模型并在预测阶段将它还原”的方法解耦训练时间和预测时间,基于这一目的,对模型修改后的结构做出了以下两个要求:
- 能够有效提升模型的表现。
- 能够成功被还原为原结构。
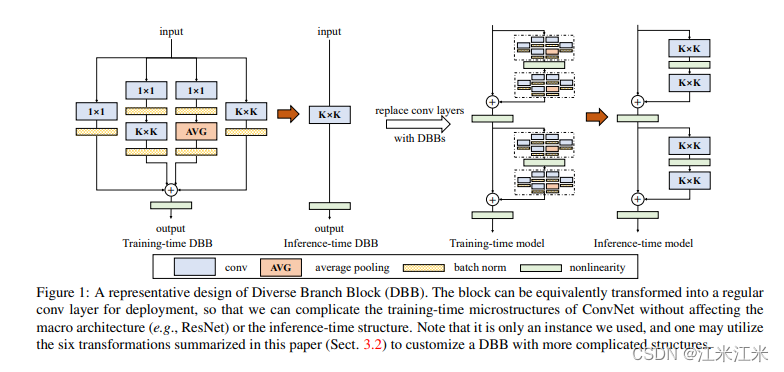
上图是一个dbb结构的示意图,在途中dbbblock使用了四种分支,其中分别包括了1x1卷积,1x1卷积+kxk卷积,1x1卷积+avg池化,kxk卷积。在测试阶段,这四个分支被合并到一起,组成一个kxk的卷积,从而在保证结果的情况下减少参数量。
原理
dbb实现的核心原理是卷积计算的同质性和可加性。
用 ⨂ \bigotimes ⨂符号代表卷积,那么在两个相同结构的卷积操作上有:
I ⨂ ( p F ) = p ( I ⨂ F ) I ⨂ F ( 1 ) + I ⨂ F ( 2 ) = I ⨂ ( F ( 1 ) + F ( 2 ) ) I \bigotimes(pF) = p(I\bigotimes F)\\ I\bigotimes F^{(1)} + I \bigotimes F^{(2)} = I\bigotimes(F^{(1)}+F^{(2)}) I⨂(pF)=p(I⨂F)I⨂F(1)+I⨂F(2)=I⨂(F(1)+F(2))
基于这一点,论文中提出来六中转换的情况。
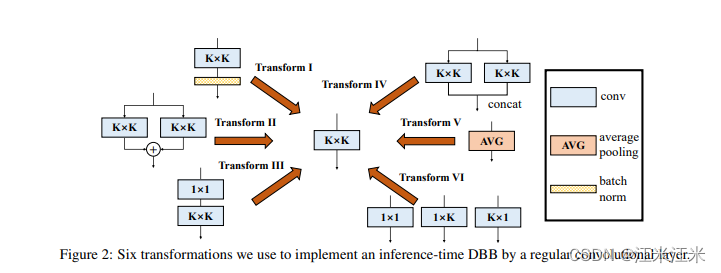
conv-bn => conv
第一种转换是带bn层的卷积转成普通的卷积。这种转换是很常用的,一个featuremap经过卷积+bn的组合后,得到的输出为:
O j = ( ( I ⨂ F j ) − μ j ) γ j ο j + β j = γ j ο j ( I ⨂ F j ) − γ j ο j μ j + β j = I ⨂ ( γ j ο j F j ) − γ j ο j μ j + β j \begin{align} O_j &= ((I\bigotimes F_j) - \mu_j)\frac{\gamma_j}{\omicron_j} + \beta_j \\ & = \frac{\gamma_j}{\omicron_j} (I\bigotimes F_j)-\frac{\gamma_j}{\omicron_j}\mu_j + \beta_j \\ &=I \bigotimes(\frac{\gamma_j}{\omicron_j} F_j) -\frac{\gamma_j}{\omicron_j}\mu_j + \beta_j \end{align} Oj=((I⨂Fj)−μj)οjγj
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









