




 本文详细介绍了PyTorch中的transforms模块,用于图像数据预处理,包括ToTensor()、Normalize()、Resize()、RandomCrop()、RandomHorizontalFlip等方法,以及如何组合使用这些方法进行图像变换,以适应模型训练需求。
本文详细介绍了PyTorch中的transforms模块,用于图像数据预处理,包括ToTensor()、Normalize()、Resize()、RandomCrop()、RandomHorizontalFlip等方法,以及如何组合使用这些方法进行图像变换,以适应模型训练需求。
教程参考:
https://pytorch.org/tutorials/
https://github.com/TingsongYu/PyTorch_Tutorial
https://github.com/yunjey/pytorch-tutorial
详细的transform的使用样例可以参考:ILLUSTRATION OF TRANSFORMS
文章目录
为什么要使用transforms
你得到的原始数据,可能并不是你期望的用于模型训练的数据的形式,比如数据中图像的大小不同、数据的格式不对。这时就需要你对数据进行统一的处理,torchvision.transforms就提供了一些帮助我们进行数据处理的简易手段。
在pytorch官方教程最开始,给了这样一个示例。
示例中使用自带的datasets:FashionMNIST,为了便于训练,对于原始数据和label分别使用了transform的方法。
对于数据本身,使用的方法是 ToTensor(),
对于标签,使用的方法是one-hot。
在后面的部分我们会详细介绍一下不同的transform方法。
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
torchvision.transforms中提供了多个方法,并且这些方法可以使用Compose进行连接,并按顺序执行。其中的大部分transforms方法都可以接受PIL图像和tensor图像作为输入,当然也有一部分在输入上有限制。
transforms方法举例
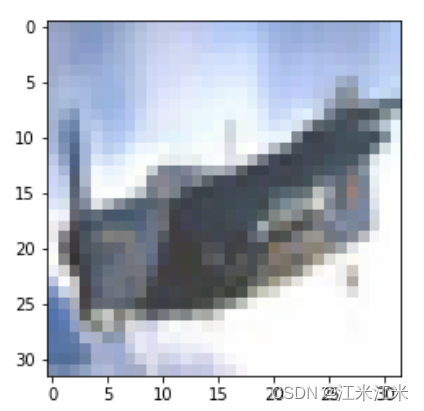
我们使用opencv读入一张cifar10中的图片作为例子,并将其通道从BGR转为RGB通道。使用opencv读入的图片,为numpy.ndarray格式。下图是我们的例子,一个类别为airplane的图像。
ToTensor()
ToTensor()方法可以把一个PIL图像或者numpy.ndarray数据转成FloatTensor的形式,并且将图像规范化到0和1之间。
更细致地来说,它会把一共PIL图像,或者范围在[0,255]的大小为(HxWxC)的numpy.ndarray转成一个大小为(CxHxW)的范围在[0.0,1.0]的floattensor。ndarray数据的dtype必须是np.uint8。

使用ToTensor()方法对我们的img进行处理,可以看到它原本为uint8的ndarray,变成了float32的tensor,它的形状从(32, 32, 3)转为(3, 32, 32),并且它的像素值的大小从51 到 255被转变为0.2到1.0。
我们也可以将图像读取为PIL Image的形式,并使用同样的方法处理。得到的结果是完全相同的。

Normalize()
Normalize()方法可以把一个tensor数据进行归一化/标准化处理。在使用时,需要你提供数据的均值和方差,Normalize()会对输入数据的每一个通道进行归一化处理。使用的方法是:
o u t p u t [ c h a n n e l ] = i n p u t [ c h a n n e l ] − m e a n [ c h a n n e l ] s t d [ c h a n n e l ] output[channel] = \frac{input[channel] - mean[channel]}{std[channel]} output[channel]=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6574
6574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









