




 本文探讨了如何利用智能指针如auto_ptr和shared_ptr进行资源管理,避免内存泄漏,重点介绍了资源获取即初始化(RAII)的概念及其在C++中的应用。
本文探讨了如何利用智能指针如auto_ptr和shared_ptr进行资源管理,避免内存泄漏,重点介绍了资源获取即初始化(RAII)的概念及其在C++中的应用。
这一章主要在讲资源的管理,电脑的资源就跟图书馆的书一样,你想看的时候可以借,但看完了就应该还,否则其他人就没法看你借的书。其中最重要的也就是内存的分配和回收了,比较常见的性能问题就是由于分配了内存但是没有回收,于是就会造成泄露。
ITEM 13: USE OBJECTS TO MANAGE RESOURCES
所谓“谁污染,谁治理”,在程序中也是一样,谁申请内存,谁就应该负责在用完后释放它,因此一条基本原则就是每有一个new,就应当有一个delete。比如下面的代码:
void f()
{
Investment *pInv = createInvestment(); // call factory function
... // use pInv
delete pInv; // release object
}
在理想情况下这样当然没有什么问题,但是事情往往不会永远按照我们的预期发展,在有些情况下delete的释放会失败,比如:在使用这个对象的过程中整个函数提前返回了,那么最后的delete就不会被调用到。或者说在一个循环内new、delete,然后又在中途调用了continue,break之类的语句。这样都会造成内存的泄露,同时该对象持有的所有资源也被泄露了。
即使我们很小心的编写代码,在每个离开的地方都去判断是否需要delete,但并不是每个人都会注意,如果是其他人也要修改这一块的代码,他很有可能不知道这里有这么个坑,于是就在无意识中造成了内存的泄露,于是你就得花上几天的功夫来debug到底是哪里造成了泄露。因此最理想的情况应该是,当指针离开了某个块或作用域,它就会自动被释放掉。
于是就引出了这样的想法:依赖C++的析构函数来帮助我们释放内存,因为当一个对象离开了作用域后它的析构函数会自动被调用,所以我们应当使用对象来管理资源。标准库中的智能指针auto_ptr就可以帮助我们做到这件事,它是一个类似指针的对象,会自动在析构函数中释放所指向的内存。改进之后代码如下:
void f()
{
std::auto_ptr<Investment> pInv(createInvestment()); // call factory
// function
... // use pInv as
// before
} // automatically
// delete pInv via
// auto_ptr's dtor
可以看到,当Investment类型的对象创建后,它的资源就转交给auto_ptr进行了管理,实际上是用这个对象来初始化了auto_ptr,这种用对象管理资源的做法叫做Resource Acquisition Is Initialization(RAII)。智能指针使用起来跟普通的指针没有区别,但是当智能指针被销毁时它会自动帮我们释放这一片内存。这里有一个需要注意的地方,因为auto_ptr会自动释放内存,所以不能让两个auto_ptr指向同一片内存,否则就会造成重复释放,因此它的复制特性会看起来有点奇怪,在复制的同时会将原来的指针置空。我自己写了个小的测试程序来验证这一点:
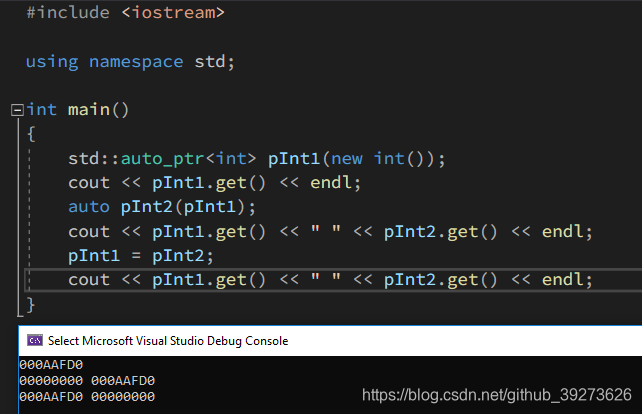
可以很清楚的看到,用pInt1来拷贝构造pInt2之后pInt1就为空了,而pInt2指向了pInt1原来指向的内存。当再次把pInt2赋值给pInt1后,pInt1又重新指向了原来的区域,而pInt2被置空。
这样用起来会有很大的局限性,因为没法让两个指针指向同一个区域了,于是就有了用的最多的shared_ptr,引用计数指针(reference-counting smart pointer)。它的作用就是当没有指针指向某个对象后会负责释放它,类似于垃圾回收,但是它无法打破循环引用(A指向B,B指向A,那么这两个对象永远不会被释放)。我也写了个小的测试程序感受了一下:
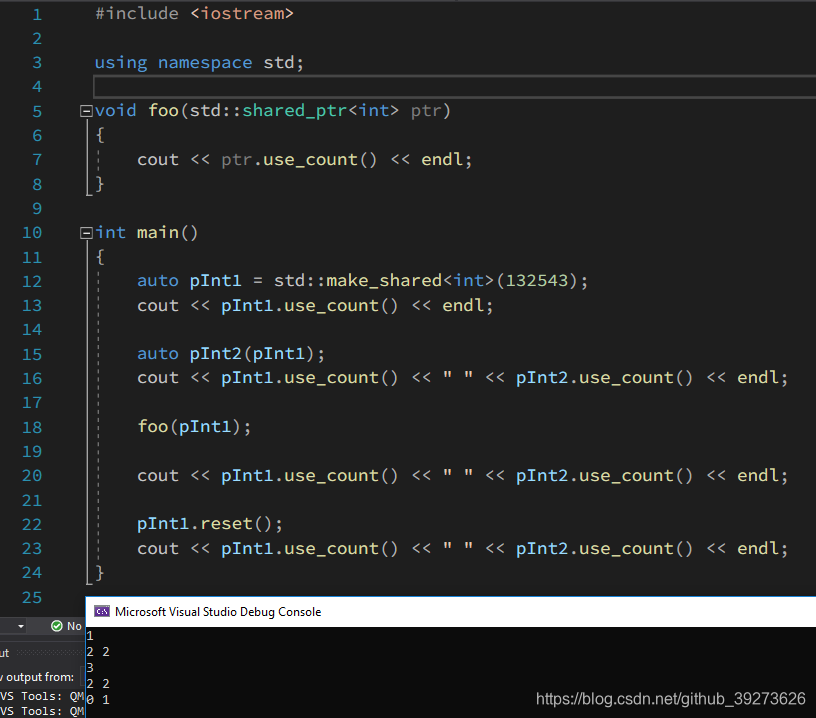
可以看到,每有一个指针指向分配的那一片内存,引用计数就会加一,而指针被销毁后引用计数也会下降,最后当最后一个指向该内存的指针也被销毁时它会负责释放这一片内存。有一点需要注意:auto_ptr和shared_ptr的析构函数调用的都是delete而不是delete [],也就是说我们不应该用智能指针来管理动态的数组,因为它被自动析构时只有第一个元素的内存会被释放。
std::auto_ptr<std::string> // bad idea! the wrong
aps(new std::string[10]); // delete form will be used
std::tr1::shared_ptr<int> spi(new int[1024]); // same problem
总结:
1. 使用RAII的方法在构造函数中获取资源,并在析构函数中释放它
2. 两种常用的RAII类是auto_ptr和shared_ptr,后者通常是更好的选择,因为它的复制操作更加合理,前者的复制操作会将源指针置空(类似于转移)
ITEM 14: THINK CAREFULLY ABOUT COPYING BEHAVIOR IN RESOURCE-MANAGING CLASSES
上面一条讲的主要是管理堆上的内存,但我们并不是所有的资源都在堆上,这个时候用智能指针可能不太合适,我们就得自己写一个管理类。比如说我们正在使用C的API操作mutex对象,那就不可避免的要加锁和解锁:
void lock(Mutex *pm); // lock mutex pointed to by pm
void unlock(Mutex *pm); // unlock the mutex
于是我们希望有一个类在构造函数中加锁,在析构函数中解锁:
class Lock {
public:
explicit Lock(Mutex *pm)
: mutexPtr(pm)
{ lock(mutexPtr); } // acquire resource
~Lock() { unlock(mutexPtr); } // release resource
private:
Mutex *mutexPtr;
};
客户端代码
Mutex m; // define the mutex you need to use
...
{ // create block to define critical section
Lock ml(&m); // lock the mutex
... // perform critical section operations
} // automatically unlock mutex at end
// of block
正常情况下OK,但是如果要复制的时候会发生什么呢
Lock ml1(&m); // lock m
Lock ml2(ml1); // copy ml1 to ml2—what should
// happen here?
这其实是一个很宽泛的问题,就是RAII的复制操作应该如何进行,在大多数情况下有以下几种选择:
- 禁止拷贝:这种情况下对RAII的拷贝没有意义,比如上面的
Lock类,因此我们直接禁止进行拷贝操作,具体做法参照第二章的item 6 - 引用计数管理的资源:这种情况就是
shared_ptr的行为,大家共用一个,最后用的负责释放。如果一个类需要引用计数的特性,它可以包含一个shared_ptr来实现。不幸的是shared_ptr在计数归零后的默认行为是释放管理的对象,幸运的是我们可以改写它的deleter,让它做我们希望做的事(在Lock中就是解锁)
class Lock {
public:
explicit Lock(Mutex *pm) // init shared_ptr with the Mutex
: mutexPtr(pm, unlock) // to point to and the unlock func
{ // as the deleter
lock(mutexPtr.get()); // see Item 15 for info on "get"
}
private:
std::tr1::shared_ptr<Mutex> mutexPtr; // use shared_ptr
}; // instead of raw pointer
这里我们没有声明析构函数了,因为没有这个必要,当Lock被析构时会自动调用成员对象的析构函数,所以智能指针就会自动调用unlock
- 拷贝资源:既拷贝管理类对象也拷贝管理的资源,既深拷贝
- 转移控制权:
auto_ptr的行为,保证只有一个类在对资源进行管理
总结:
1. 拷贝一个RAII对象涉及到拷贝它管理的资源,所以对资源的拷贝方式决定了拷贝RAII对象的方式
2. 一般的RAII类不支持拷贝和引用计数,但其他行为是允许的
ITEM 15: PROVIDE ACCESS TO RAW RESOURCES IN RESOURCE-MANAGING CLASSES
资源管理类用着很方便,但是工作中难免会出现需要直接访问它所管理的对象的情况,比如QT中连信号和槽就必须把QObject*作为参数,因此我们最好提供对原始资源的直接访问,通常有显式转换和隐式转换两种方法。
比如auto_ptr和shared_ptr都提供了get方法显式的返回一份对内部原始指针的拷贝。同时它们也重载了解引用运算符(operator*,operater->),提供了隐式转换的方法。
有的RAII类为了用起来更方便,会提供隐式转换的方法(否则每次都要调用get,会让代码看起来很冗余),这里学习了一下用operator关键字进行类型转化的用法:
class Font {
public:
...
operator FontHandle() const { return f; } // implicit conversion function
...
};
函数名是什么类就表示转化成什么类,于是下次传递RAII类时如果不写get就会调用这个转化函数进行隐式转化。当然这样做的风险就是增加了出错的概率,因为有可能你其实想拷贝RAII类但是却错误的拷贝了它所管理的类。总之,需要自己权衡应该用显式转换保证直观性,还是用隐式转换保证自然性。
最后聊了一下关于RAII类对封装的破坏,作者对此的解释是:RAII类并不是用来封装的,它是为了保证资源被正确的分配和释放。而且,有的RAII类结合了良好的封装性和较松的封装性,比如shared_ptr对于引用计数的实现进行了封装,同时又提供了get方法允许用户访问管理的资源。好的类应当隐藏客户端不需要知道的,但提供客户端可能需要知道的。
总结:
1. API经常需要访问原始类的指针,因此在RAII类中需要提供方法对资源进行访问
2. 对资源的访问可以通过显式或隐式的方法完成,通常来说显式更安全,隐式用起来更方便
ITEM 16: USE THE SAME FORM IN CORRESPONDING USES OF NEW AND DELETE
这条比较简单,一句话概括就是如果用new创建单个对象,就直接delete,如果用new创建了数组,就必须用delete [],这个知识点也是之前听了课才知道的,这里再巩固一下。
std::string *stringArray = new std::string[100];
...
delete stringArray;
以上代码会导致只有第一个string被释放,剩下99个都泄露了。当调用new的时候,首先会分配内存(通过operator new实现),然后会调用一次或多次相应的构造函数。当调用delete的时候,首先会调用一次或多次相应的析构函数,然后会释放内存(通过operator delete实现)。而delete时最大的问题就是:有多少个对象驻留在内存中?这决定了应该调用多少次析构函数。
而单个对象和数组对象的内存布局是不同的,我们可以理解成数组对象应当先存储它的大小,然后才是它所包含的对象,如图:

所以当调用delete的时候,我们必须告诉编译器应该是哪种布局,否则它不知道是否会有数组大小这样一个信息在该内存区域,而告诉它的方法就是[]。错误的调用delete或者delete []都会造成无法预期的结果,通常都是不好的。其实用vector之后就几乎可以不用原生的数组了,也更加安全。
总计:
如果new的时候没有[],delete的时候就不用[],如果new的时候用了[],delete的时候就要用[]
ITEM 17: STORE NEWED OBJECTS IN SMART POINTERS IN STANDALONE STATEMENTS
这一条主要是说应该用单独的语句来创建智能指针,事实上代码本来也是应该一行就做一行的事情,不应当有过于复杂的表达式,当然这里主要是在讲可能会发生的内存泄露。
int priority();
void processWidget(std::tr1::shared_ptr<Widget> pw, int priority);
上面的代码用了智能指针管理的作为参数
processWidget(new Widget, priority());
但是这样会报错,因为智能指针的构造函数是显式的,不能直接传入Widget的指针进行隐式转换,所以需要这样写:
processWidget(std::tr1::shared_ptr<Widget>(new Widget), priority());
以上的代码是可能造成泄露的,原因如下:
编译器需要先生成processWidget的参数,第二个参数是直接通过priority函数获得,但第一个参数其实包含两步:new Widget,调用智能指针的构造函数。也就是说编译器要做三件事:
- 调用
priority - 执行
new Widget - 调用
shared_ptr的构造函数
而C++的编译器具有比较大的自由度,所以这三件事的顺序可能是这样的:
- 执行
new Widget - 调用
priority - 调用
shared_ptr的构造函数
如果这种情况下,调用priority产生了异常,就会导致我们只做了第一步而没有做第三步,也就是只创建了对象但是还没来得及将它转交给智能指针,也因此就会造成内存泄漏。防止这种情况也很简单,只要单独写一条语句来创建智能指针然后把它作为参数传入就行了:
std::tr1::shared_ptr<Widget> pw(new Widget); // store newed object
// in a smart pointer in a
// standalone statement
processWidget(pw, priority()); // this call won't leak
编译器在语句之间是没有很大的自由度的,只在语句内才可能调换顺序,所以这样写就不会出现刚才的问题了。
总结:
用单独的语句来创建智能指针,否则可能因为异常的出现导致内存泄露

















 7660
7660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









