




 在Win10计算器培训中遇到问题,计算结果字符串长度异常,发现存在不可见字符U202D和U202C。这两个Unicode字符导致字符串比较异常,影响自动化处理。通过二进制查看和Unicode查询,了解到其为方向格式化字符,研究其在自动化中的影响。
在Win10计算器培训中遇到问题,计算结果字符串长度异常,发现存在不可见字符U202D和U202C。这两个Unicode字符导致字符串比较异常,影响自动化处理。通过二进制查看和Unicode查询,了解到其为方向格式化字符,研究其在自动化中的影响。
最近给新人培训的过程中, 在win10的计算器上遇到了一个小问题, 当时本来以为5分钟能给解决, 结果研究了2个小时才找到root cause, 总结一下当时的思路.
环境: Win10 ent x64 21H1
打开计算器, 获取计算结果的文本后, 与预期进行比较, 结果比较总是不会进到 IF里, 明明两个变量都是同样的数字.
刚开始看到这个问题, 我以为是计算器文本中带了 CR/LF/TAB 这类字符串, 便想到了remove前后的特殊字符, 无果.
之后比较了一下获取到的字符串的长度, 明明是一个三位数, 但是string length 竟然是5, 由此便想到放到二进制中查看一下.
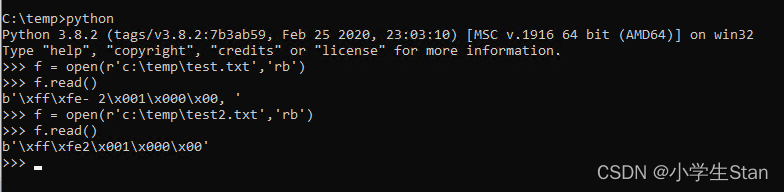
查看发现, 从计算器结果框中取到的值, 多了一个 '- '的字符.
这下就好判断了, 用unicode查看一下取到的变量, 发现获取到的变量中, 是两个不可见字符, U202C 和 U202D.
查了一下这两个字符的用途, 没找到特别满意的答案.不过发现有人跟我遇到了一样的问题.
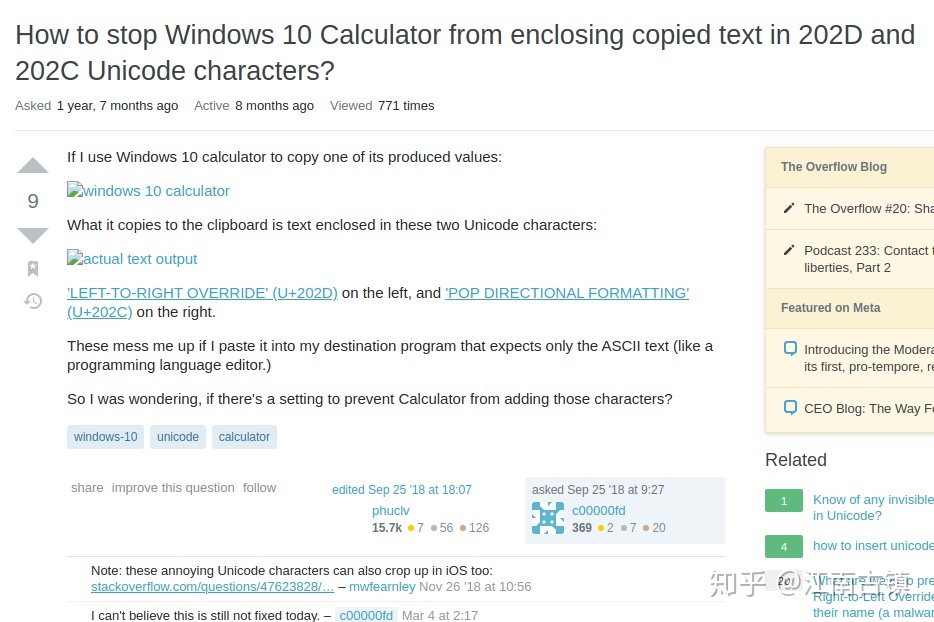
其实用workaround很容易把这个问题忽略, 但是确实感觉这么一个简单的计算器的automation, 觉得挺有趣的, 就花时间研究了一下.
字符含义:U+202C Pop Directional Formatting (PDF) Unicode Character (compart.com)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9328
9328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









