




 本文探讨了从机器学习到深度学习的过渡,并详细解释了模型改进的重要性及如何通过验证集评估这些改进。此外,还介绍了随机梯度下降(SGD)的概念及其超参数调整技巧。
本文探讨了从机器学习到深度学习的过渡,并详细解释了模型改进的重要性及如何通过验证集评估这些改进。此外,还介绍了随机梯度下降(SGD)的概念及其超参数调整技巧。
课程 1:从机器学习到深度学习
模型改进
模型改进后,在你的验证集上影响了30个实例的改变,通常是有统计学意义的,通常是可以信任的。想象你的验证集里有3000个实例,假定你信任30的规则,你可以相信哪个水平的准确性的提升?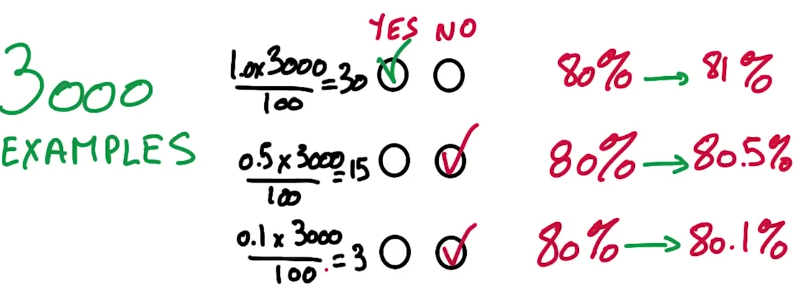
当你得到从80%到81%,这1%的提升更有说服力,因为有30个实例从不正确到正确。这就是为什么对大多数分类器任务,人们倾向于用超过3000个实例做验证集,因为这使得准确率的第一个小数位是有效数字,给你足够的分辨率去看到小的改进。

随机梯度下降(SGD)
人们认为SGD是黑魔法,你有很多超参数可以调节:
(1)初始化权重(initialization parameters)
(2)学习率(learning rate parameters)
(3)衰减比(decay)
(4)动量(momentum)
当训练出现问题的时候,首先应该想到降低学习率。
参考文献
[1] https://classroom.udacity.com/courses/ud730
课程 2:任务 1: notMNIST
官网示例:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/udacity/1_notmnist.ipynb
博客示例:http://www.hankcs.com/ml/notmnist.html
我是照着官网来的,但是其中的下载文件和解压是用浏览器下载和鼠标右键解压。我的解压文件放在E:\ Machine_Learning_Project\ deeplearning_in_udacity\ notMNIST,所以加上下列代码。
import os
os.chdir("E:\\Machine_Learning_Project\\deeplearning_in_udacity\\notMNIST")然后,把文件夹读进train_folders和test_folers,使
train_folders=['notMNIST_large/A', 'notMNIST_large/B', 'notMNIST_large/C', 'notMNIST_large/D', 'notMNIST_large/E', 'notMNIST_large/F', 'notMNIST_large/G', 'notMNIST_large/H', 'notMNIST_large/I', 'notMNIST_large/J']
test_folers=['notMNIST_small/A', 'notMNIST_small/B', 'notMNIST_small/C', 'notMNIST_small/D', 'notMNIST_small/E', 'notMNIST_small/F', 'notMNIST_small/G', 'notMNIST_small/H', 'notMNIST_small/I', 'notMNIST_small/J']之后,按照官网或者博客的操作就行。
总的来说,第一个学习任务没有太多难点,主要是用于熟悉一般的机器学习的,模型可以直接从sklearn里面选一些来尝试。如果用一般的模型,甚至还不用涉及tensorflow。
参考文献
[1] https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/udacity/1_notmnist.ipynb
[2] http://www.hankcs.com/ml/notmnist.html

















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









