




 WebScraper是一款Chrome插件,适用于网页数据抓取。它支持自动识别DOM节点,模拟滚动及点击等交互,适用于分页和子页面数据抓取场景。用户可通过简单配置实现信息的批量抓取并导出。
WebScraper是一款Chrome插件,适用于网页数据抓取。它支持自动识别DOM节点,模拟滚动及点击等交互,适用于分页和子页面数据抓取场景。用户可通过简单配置实现信息的批量抓取并导出。
Web Scraper是一款用于抓取网页数据的 Chrome 插件,只需通过简单的点选操作即可完成抓取配置,无需编写代码。
功能
就说说我使用时,他能够实现的那些具体功能吧。
- 能够实现网页内的信息抓取。可以自动识别相同结构的dom节点。
- 可以模拟滚动或者点击,获取多页面的信息。包括分页的情况和子页面的情况。
- 快速导出信息。
优缺点
| 优点 | 缺点 |
|---|---|
| 操作简单,无需写代码。自动识别dom,无需人工手找。 | 不适合复杂的爬虫 |
| 快速方便,只需一次配置,多次使用。可以将配置导入导出,方便分享。 | 好像没有代理的功能,容易被网站封 |
案例说明
安装
- 谷歌商店
- 网上搜索 Web Scraper 的crx插件,下载安装
爬取当前页
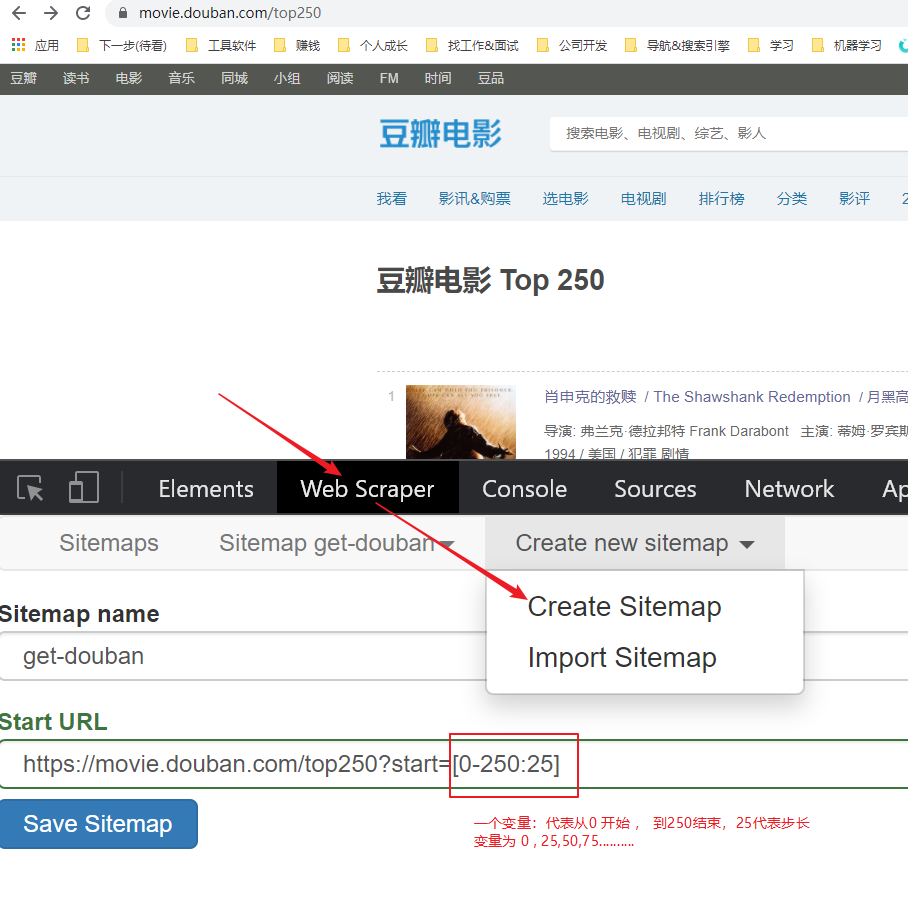
接着单击add new selector按钮,
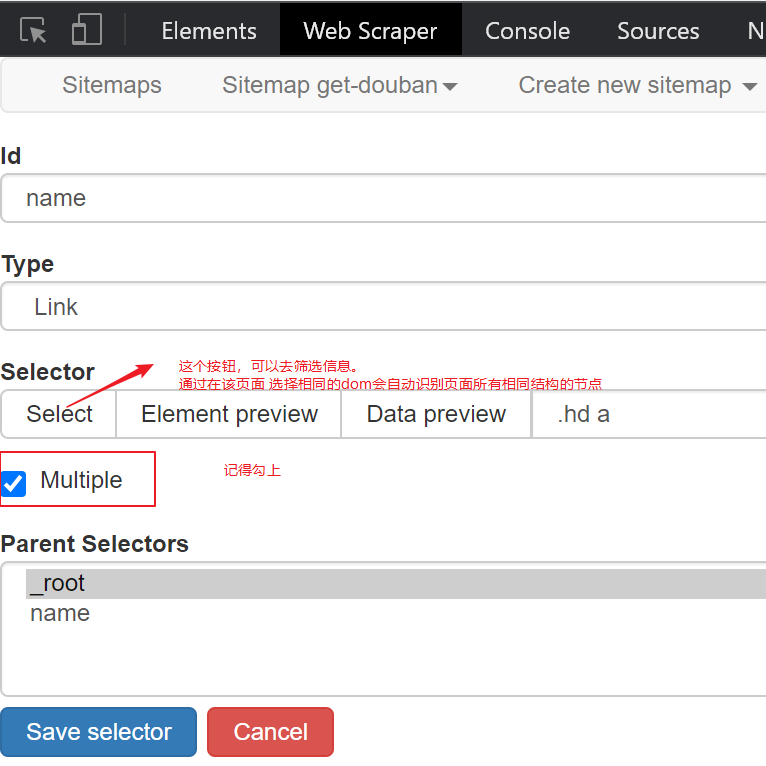
用同样的方法去,选择评分。
最后单击第个菜单 下的scrape 命令-> start scraping 进行抓取。
二级页面
可在第一步的基础上(Type为Link),单击selector 进去,再新建selector,进行子页面的信息筛选。
爬取多页(分页)
- 网址有规律(步骤1已经体现,通过特殊的表达式)
- 滚动。添加selector时 Type选择
Element scroll down即可。 - 动态单击下一页。添加selector时 Type选择,
Element click, 并且Click selector选择,下一页按钮 或者 分页数字按钮,Click type 对应选择。
具体使用方法请参考以下!
参考(学习教程)
https://space.bilibili.com/486167069/channel/detail?cid=98556


















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











