




 本文探讨了自编码器在特征压缩中的应用,以及PCA和SVD在降维中的角色。介绍了BERT-whitening通过PCA/SVD进行句子向量的白化处理,并讨论了为何SVD在实践中更常用。同时,文章介绍了SimCSE利用Dropout作为无监督的数据扩增手段,改进了BERT模型,提升了文本embedding的效果。实验表明,降维和正负样本策略能有效提高模型性能。
本文探讨了自编码器在特征压缩中的应用,以及PCA和SVD在降维中的角色。介绍了BERT-whitening通过PCA/SVD进行句子向量的白化处理,并讨论了为何SVD在实践中更常用。同时,文章介绍了SimCSE利用Dropout作为无监督的数据扩增手段,改进了BERT模型,提升了文本embedding的效果。实验表明,降维和正负样本策略能有效提高模型性能。
1.“铲子”的经验、学习记录,不定期update【接上】
7)自编码器
结论:用来压缩特征,得到这个encoder,生成yyy
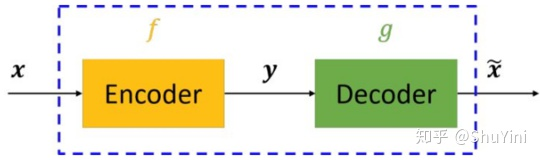
自编码器模型主要由编码器(Encoder)和解码器(Decoder)组成,其主要目的是将输入xxx转换成中间变量yyy,然后再将yyy转换成 x~\tilde{x}x~,然后对比输入xxx和输出x~\tilde{x}x~使得他们两个无限接近。比如建立一个MSE的loss,然后优化这个loss。
其实就是无监督的一个embedding
另外,和PCA这种思想也是,有损压缩,尽量信息损失少
8)无监督文本embedding(学习了下新东西)
- BERT-whitening:
思路很简单,就是在得到每个句子的句向量xi{x_i}xi后,对这些向量进行一个白化(也就是PCA/SVD),使每个维度的均值为0、协方差矩阵为单位阵,然后保留k个主成分。

为啥多用SVD:https://zhuanlan.zhihu.com/p/58064462
SVD与PCA等价,所以PCA问题可以转化为SVD问题求解,那转化为SVD问题有什么好处?
方阵的特征值分解计算效率不高,SVD除了特征值分解这种求解方式外,还有更高效且更准确的迭代求解法。
结论:实验结果显示,在多数任务中,降维不但不会带来效果上的下降,反而会带来效果上的提升。https://www.spaces.ac.cn/archives/8321
- SimCSE:
正负样本:本质上来说就是(自己,自己)作为正例、(自己,别人)作为负例来训练对比学习模型。数据扩增手段,让正例的两个样本有所差异,但是在NLP中如何做数据扩增本身又是一个难搞的问题,SimCSE则提出了一个极为简单的方案:直接把Dropout当作数据扩增。
模型:Bert(Transformer)
损失函数:


结论:1.SimCSE效果比BERT-whitening好(得益于这个正样本的扩充方式+损失函数第二部分?);2.用CLS比用Pooler好


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









