




看了这一篇,更清晰了,下面截图做点笔记。
http://aandds.com/blog/ensemble-gbdt.html

方框1,本质就是每一轮弱学习器,去拟合损失函数关于预测值的负梯度,迭代下去,损失越来越小,这里也就是核心所在了----“梯度下降”
方框2,这里最速下降,有一个步长的最优搜索。

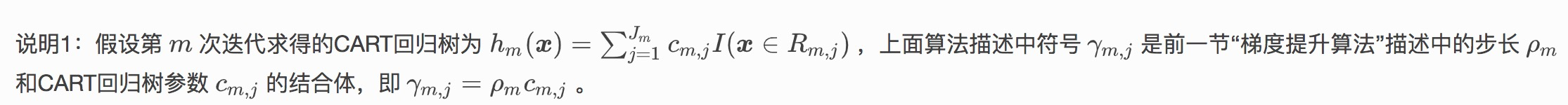
这个地方其实在之前博客中,写gbdt、xgboost树生成流程的时候算过,并没有先算梯度、再寻优步长,而是作为一个整体算这一轮弱分类器的预测值。
看了这一篇,更清晰了,下面截图做点笔记。
http://aandds.com/blog/ensemble-gbdt.html
方框1,本质就是每一轮弱学习器,去拟合损失函数关于预测值的负梯度,迭代下去,损失越来越小,这里也就是核心所在了----“梯度下降”
方框2,这里最速下降,有一个步长的最优搜索。
这个地方其实在之前博客中,写gbdt、xgboost树生成流程的时候算过,并没有先算梯度、再寻优步长,而是作为一个整体算这一轮弱分类器的预测值。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























