




今天看了B站一位up主解释L1和L2正则化,感觉讲解的很不错,自己总结一下。
面试常见问题:
- 如何防止模型过拟合。
- 为什么正则化可以防止过拟合?
- 为什么L1得到的多是稀疏解?
这三个问题,明显是一套组合拳。
4. 正则化,增加数据,减少模型参数
5. 可以从两方面回答,一个是增加约束条件,通过KKT条件,等价于增加正则化。第二,从概率论的角度。L1正则化是先验概率为拉普拉斯分布;L2正则是先验概率为高斯分布。
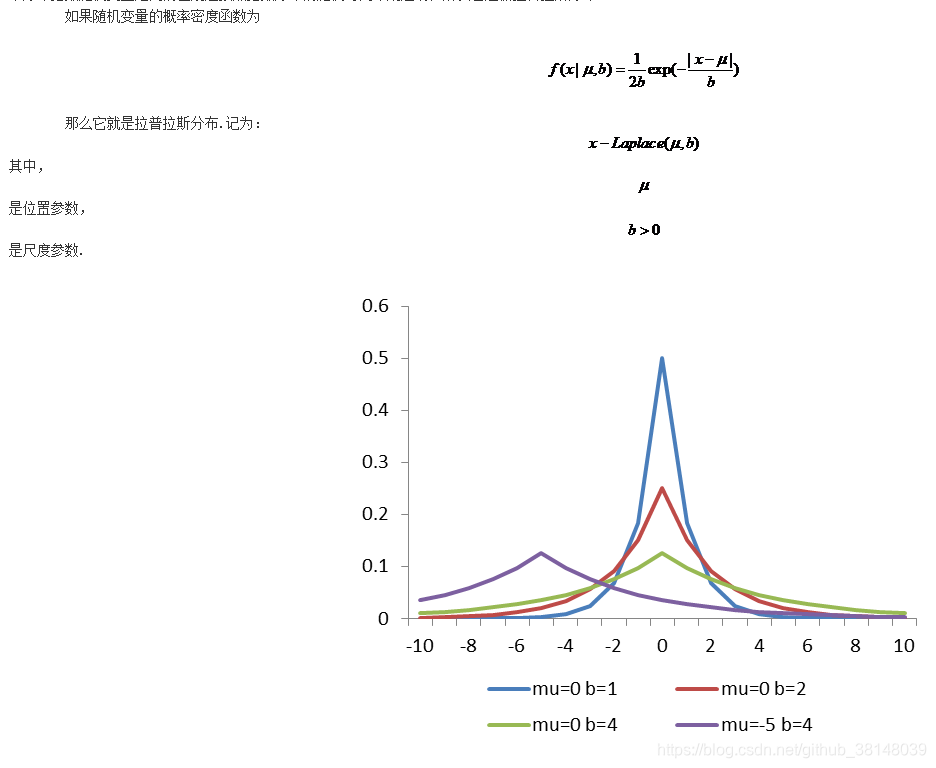
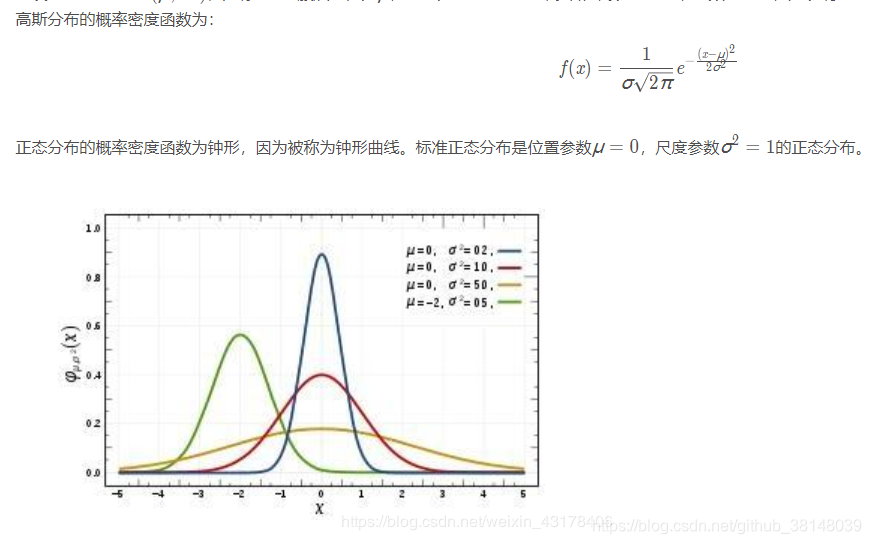
7. 第一,图形的交点。第二,取得零值的概率不同,拉普拉斯分布大于高斯分布。
参考:
减少过拟合的方法
https://blog.youkuaiyun.com/fangqingan_java/article/details/51816002?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
约束项解释
https://www.jianshu.com/p/9dffeb4fcfdb
概率论角度解释正则化
https://blog.youkuaiyun.com/qq_33638791/article/details/76039641
高斯与拉普拉斯分布
https://blog.youkuaiyun.com/weixin_43178406/article/details/98474881?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









