




有一个词叫做“三月爬虫”,指的是有些学生临到毕业了,需要收集数据写毕业论文,于是在网上随便找了几篇教程,学了点requests甚至是urllib和正则表达式的皮毛,就开始写爬虫疯狂从网上爬数据。这些爬虫几乎没有做任何隐藏自己的举动,不换IP,不设置headers,不限制速度,极易被有反爬的网站封锁,极易给没反爬的小网站造成流量压力。
后来,他们又不知道看了哪篇文章,知道要使用代理IP,要修改UserAgent。于是,他们真的就只在headers设置UserAgent,其他项一概不设置。你给他指出来,他还振振有词:你看我这样能爬到数据啊,headers里面其他项目没有用。
事实真的是这样吗?
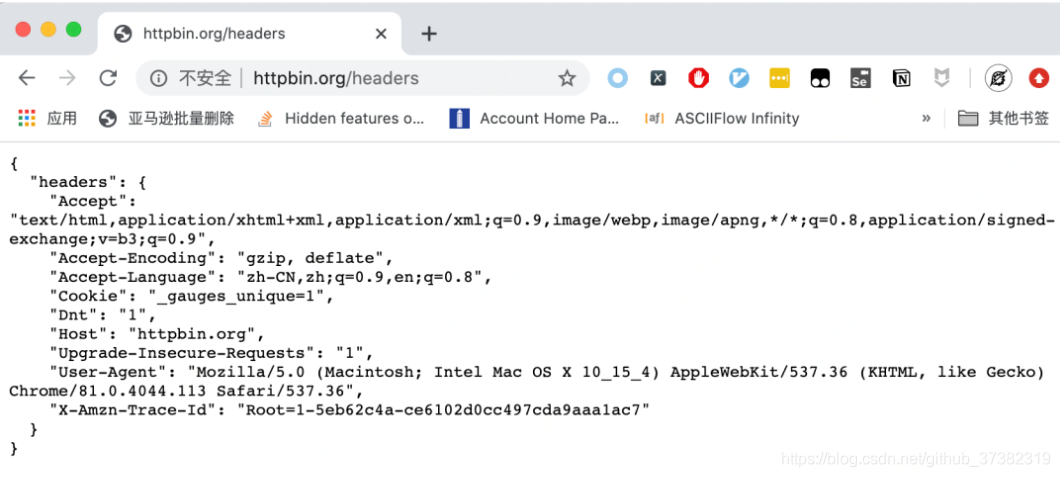
我们来做个实验,首先使用Chrome访问 http://httpbin.org/headers 这个网站可以显示当前你的headers。运行效果如下图所示:
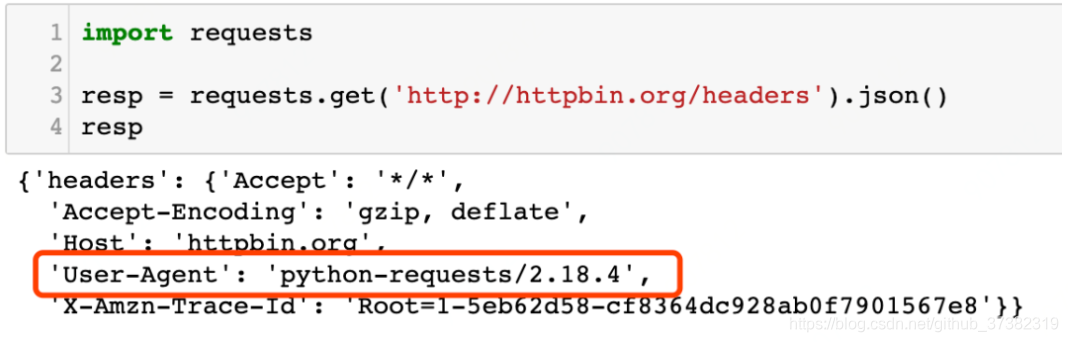
然后,再使用requests不设置headers请求这个URL,运行效果如下图所示:
最后,我们仅仅设置一个UserAgent看看效果:
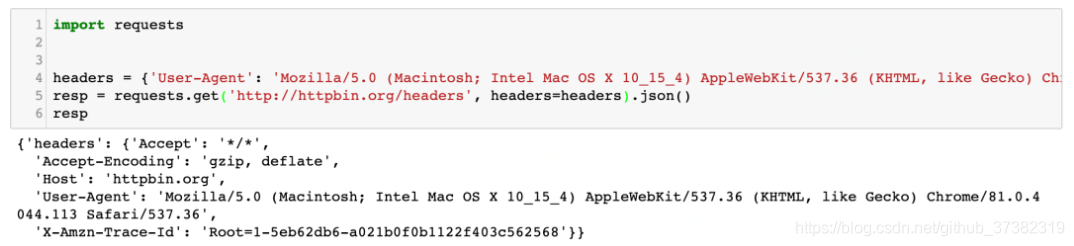
可以看出来,仅仅设置一个UserAgent,与用浏览器访问的 Headers 还是有很多不一样的地方。缺了很多项。网站只需要检测缺的这几项,就能确定你是用程序发起的请求还是用浏览器发的请求。

















 65万+
65万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









