







 本文是Python轻奢入门系列的第三篇,详细介绍了字符串的基本操作,包括格式、输出、输入、下标、切片以及find、split等常见方法。接着讲解了正则表达式,涵盖匹配单个字符、多个字符、开头和结尾,以及re.match、re.search和re.sub等方法。此外,还讨论了列表的常用方法,如append、insert、remove等,并简要提及元组、字典和集合的特点及操作。最后提到了Python的垃圾回收机制及其优点。
本文是Python轻奢入门系列的第三篇,详细介绍了字符串的基本操作,包括格式、输出、输入、下标、切片以及find、split等常见方法。接着讲解了正则表达式,涵盖匹配单个字符、多个字符、开头和结尾,以及re.match、re.search和re.sub等方法。此外,还讨论了列表的常用方法,如append、insert、remove等,并简要提及元组、字典和集合的特点及操作。最后提到了Python的垃圾回收机制及其优点。

专栏: python轻奢入门系列
作者: 豆破苍琼
【字符串】
字符串介绍
字符串格式
被单引号或者双引号括起来的数据就是字符串。
字符串输出
"""
字符串输出
"""
def printStream(nums):
import time
for i in range(nums):
print('正在持续输出{}次'.format(i))
if i != nums-1:
print("等待1秒后...")
time.sleep(1)
print("完成输出!")
printStream(10)

字符串输入
"""
字符串输入
"""
name = 'hello world!'
count = 3
words = input("学习编程,进入编程世界的第一句话是什么?\n")
while True:
if words == name:
print("恭喜你,进入编程世界!")
break
else:
if count == 0:
print("江湖再见!\n")
break
words = input("很遗憾,你再想想,学习编程,进入编程世界的第一句话是什么?\n")
count -=1

字符串常见操作
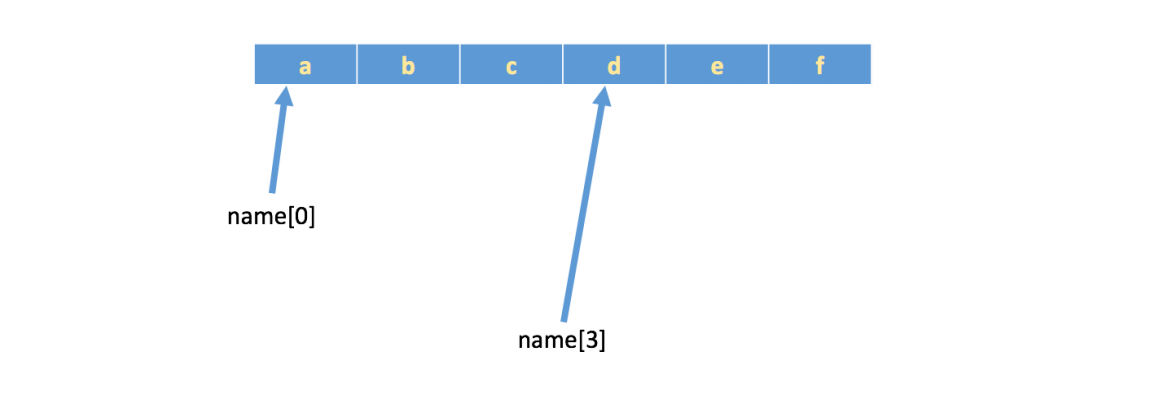
下标
字符串实际是字符数组,所以支持下标的使用。
切片
"""
字符串切片
"""
raw_address = 'https://dpcq.com:8080'
pure_address = raw_address[:-4]
pure_port = raw_address[-4:]
head = raw_address[0:4:1]
print('head:{}\naddress:{}\nport:{}'.format(head,pure_address,pure_port))
"""
特殊操作
"""
reverse_address = raw_address[::-1]
print('reverse operation:%s'%reverse_address)

常见操作: find 、split、lower、upper、index、count、
"""
字符串常见操作
"""
raw_address = 'https://dpcq.com:8080'
# find 方法 、index 查询不到会报错 而不会返回-1
"""
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
"""
d_index = raw_address.find('d',1,-1)
q_index = raw_address.index('s')
# split 方法
"""
raw_address.split(sep=None, maxsplit=-1)
sep
The delimiter according which to split the string.
None (the default value) means split according to any whitespace,
and discard empty strings from the result.
maxsplit
Maximum number of splits to do.
-1 (the default value) means no limit.
"""
sp_data = raw_address.split(sep=':',maxsplit=2)
# lower 、upper 方法
lower_data = raw_address.lower()
upper_data = raw_address.upper()
# count 方法
nums_t = raw_address.count('d')
print(" d index is {},s index is {} \n sp_data len is {}\n lower_data is {} \n upper_data is {}\n t count is {}".format(
d_index,q_index,len(sp_data),lower_data,upper_data,nums_t))

正则表达式
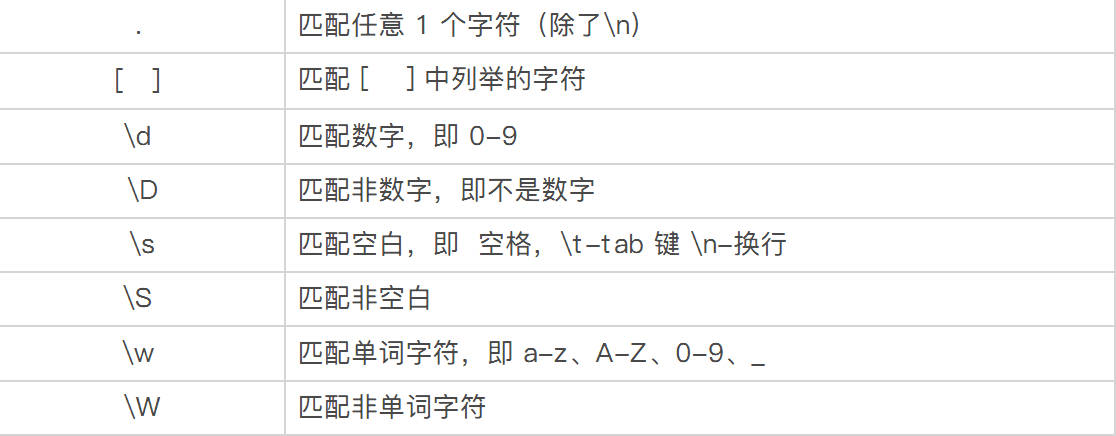
匹配单个字符
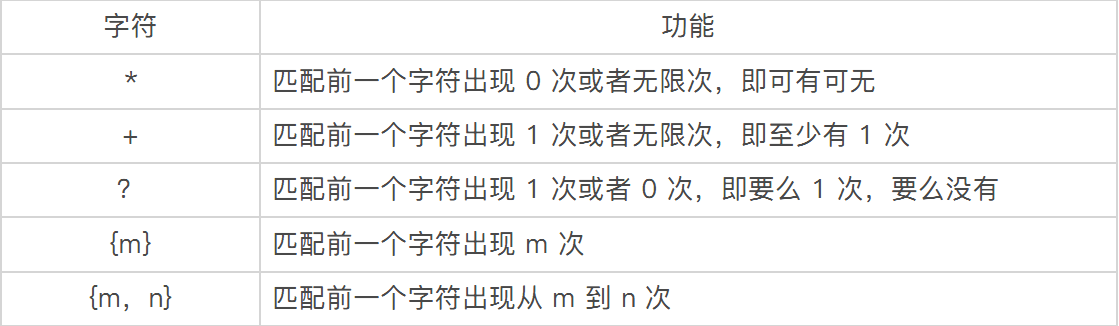
匹配多个字符
匹配开头和结尾

re.match匹配
re.match尝试从字符串的起始位置匹配,如果不是起始位置匹配成功的话,match方法就返回None。

import re
# match 匹配
"""
match 开头不成功,则返回None
"""
raw_data = 'luo zhi xiang shi shi jian guan li da shi'
matach_rst_1 = re.match('[l]',raw_data).span()
matach_rst_2 = re.match('zhi',raw_data)
line = "American is greater than before."
# re.M 表示多行匹配 会影响到^和$
# re.I 使匹配对大小写不敏感
matchObj = re.match(r'([a].*) is (.*?) .*$',line,re.M|re.I)
if matchObj:
print(matchObj.group())
print(matchObj.group(1))
print(matchObj.group(2))
else:
print("No match!")
re.research方法
import re
line = "American is greater than before."
matchObj = re.search(r't+',line,re.M|re.I)
if matchObj:
print("search match:",matchObj.group())
else:
print("No matched!")
re.search与re.match不同的是前者可以匹配全文,返回第一个匹配项,后者开头匹配,匹配不成功则返回None。
re.sub方法
Python的re模块提供了re.sub用于替换字符串中的匹配项。将匹配到的内容替换为自己想要的数据。

"""
re.sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the Match object and must return
a replacement string to be used.
"""
# 举个栗子! 再聚个麒麟臂
phone = "1236-63256-933 # this is a text."
non_num = re.sub(r'\D','',phone)
print(non_num)
# re.sub的第二个用途
def replace_num(str):
numDict = {'0':'〇','1':'一','2':'二','3':'三','4':'四','5':'五','6':'六','7':'七','8':'八','9':'九'}
print(str.group())
return numDict[str.group()]
my_str = '2020年10月24号'
a = re.sub(r'(\d)', replace_num, my_str)
print(a)
re.split方法
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以用个按位OP(|)它们来指定。

# re.split
raw_data = 'dcpq,wwww,com,dot'
split_result = re.split('\W',raw_data)
split_result
【列表】
列表格式
列表内的元素可以是不同类型的。
列表输出
类似以下的都可以被称为对列表的输出。

遍历列表
for、while循环
"""
列表
"""
students = ['杨超越','吴尊','刘亦菲','杨利伟','Max Moon','Alex Jim']
#print(students)
# for 循环列表
for s_stu in students:
print('current:{}'.format(s_stu))
# while 循环打印列表元素
while len(students)>0:
print(students.pop())
print(len(students))
常见方法
append、insert、extend、del、remove、pop、in、not in
poem = ['见与不见']
poem.append('你见,或者不见我')
poem.append('我就在那里')
poem.append('不悲不喜')
poem.insert(4,'你念,或者不念我')
print(poem)
poem.extend(['情就在那里','不来不去','你爱,或者不爱我'])
print(poem)
del poem[-1]
print(poem)
poem.remove('不来不去')
print(poem)
poem.pop()
print(poem)
test_1 = '我就在哪里'
test_2 = '我就在那里'
if test_2 in poem:
print('It is in !')
else:
print('Not in !')
【元组、字典、集合】
元组
介绍
元组和列表类似,不同之处在于
- 元组的元素不能修改
- 元组使用的是小括号、列表使用的是方括号
- 元组中只包含一个元素时,需要再元素的后面添加逗号
访问元组
修改元组
元组不允许对其修改
删除元组
del即可。
元组运算符
与字符串一样,元组之间可以使用+号和*号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。

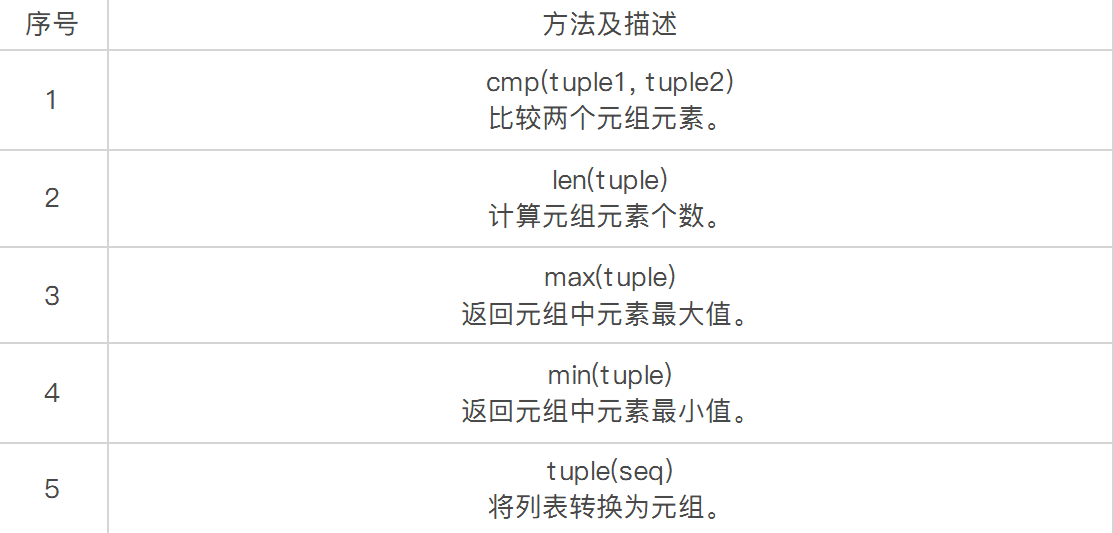
元组的内置函数
字典
介绍
在Python中,字典与列表类似,但是字典是无序的,保存的内容是以key-value的形式进行存放的。
字典特征
- 通过键而不是索引来获取数据
- 字典中的键必须唯一
- 字典中的键必须不可变
字典访问
price_fruit = {'banana':4.3,'apple':2,'pea':4}
print(price_fruit['banana'])
other = price_fruit.get('water',1)
print(other)
常见操作
- 添加、修改、删除、len、keys、values、items
price_fruit = {'banana':4.3,'apple':2,'pea':4}
print(price_fruit['banana'])
other = price_fruit.get('water',1)
print(other)
# 添加
price_fruit['pointer'] = 2
# 删除
del price_fruit['pea']
# 修改
price_fruit['pointer'] = 4
# len
len_dict = len(price_fruit)
# keys 返回字典类型的迭代器
k_d = price_fruit.keys()
for i in k_d:
print(i)
# values
v_d = price_fruit.values()
for i in v_d:
print(i)
# items 方法 获取字典中的键值对 将其存储在元组中
print(price_fruit.items())
for i in price_fruit.items():
print(i)
集合
介绍
Python集合是一个无序,不重复的元素序列。
创建
常见操作
- 添加
集合不仅可以添加单个元素,并且可以添加任意元素.可以是列表、元组、字典等。
- 删除
删除可以是删除指定元素,也可以是删除任意元素。
# 添加
s1 = set(('腾讯',"百度","京东"))
s1.add("小米")
print(s1)
# 添加
s1.update({1,2})
print(s1)
s1.update([3,4],[5,65])
print(s1)
# 删除 1
s1.discard("hahah")
print(s1)
# remove 删除不存在的元素会报错、discard则不会
s1.remove('ping')
# pop删除任意元素
s1.pop()
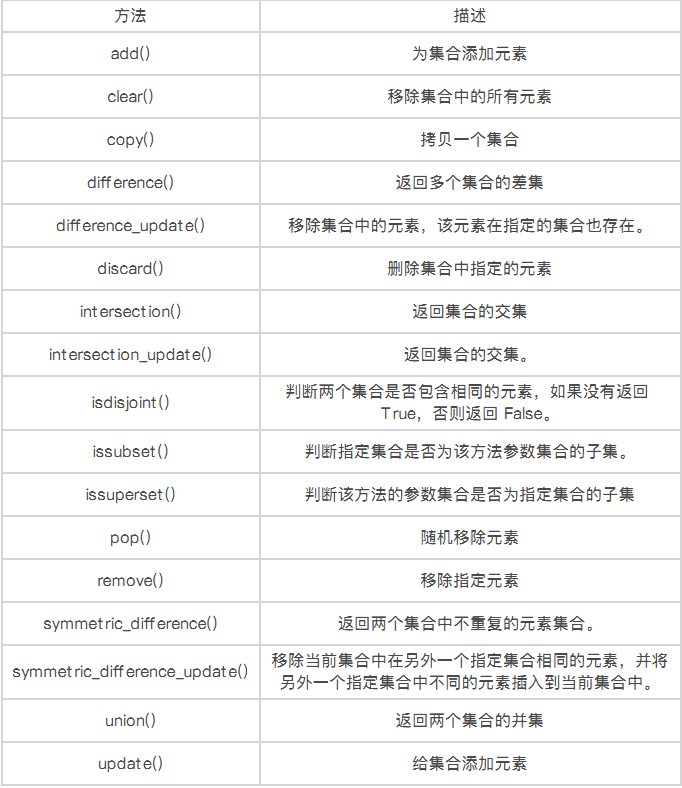
集合内置方法列表
垃圾回收机制
Python中垃圾回收是以引用计数为主,分代收集为辅。引用计数的缺陷是循环引用的问题。
在python中,如果一个对象的引用数为0,Python虚拟机就会回收这个对象的内存。当引用计数为0时,该对象的声明就结束了。
优点
- 简单
- 实时性

【参考】
1.《Pyrhon handbook》


















 71万+
71万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











