




一、高可用性
1.Kafka 本身是一个分布式系统,同时采用了 Zookeeper 存储元数据信息,提高了系统的高可用性。
2.Kafka 使用多副本机制:当状态为 Leader 的 Partition 对应的 Broker 宕机或者网络异常时,Kafka 会通过选举机制从对应的 Replica 列表中重新选举出一个 Replica 当做 Leader,从而继续对外提供读写服务,利用多副本机制在一定程度上提高了系统的容错性,从而提升了系统的高可用。
二、可靠性
- 从 Producer 端来看,可靠性是指生产的消息能够正常的被存储到 Partition 上且消息不会丢失。Kafka 通过 request.required.acks和min.insync.replicas 两个参数配合,在一定程度上保证消息不会丢失。
request.required.acks 可设置为 1、0、-1 三种情况。
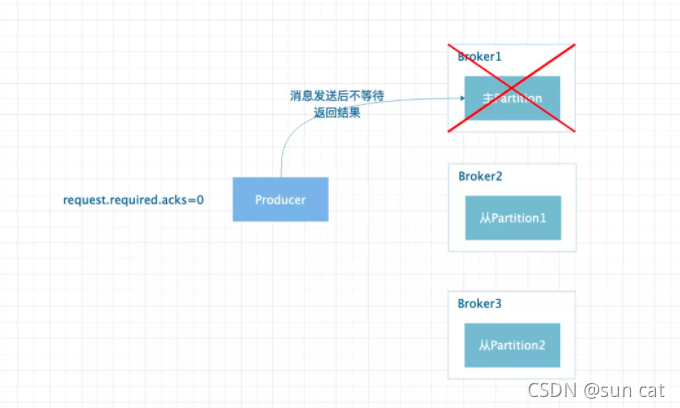
request.required.acks=1。设置为 1 时代表当 Leader 状态的 Partition 接收到消息并持久化时就认为消息发送成功,如果 ISR 列表的 Replica 还没来得及同步消息,Leader 状态的 Partition 对应的 Broker 宕机,则消息有可能丢失。
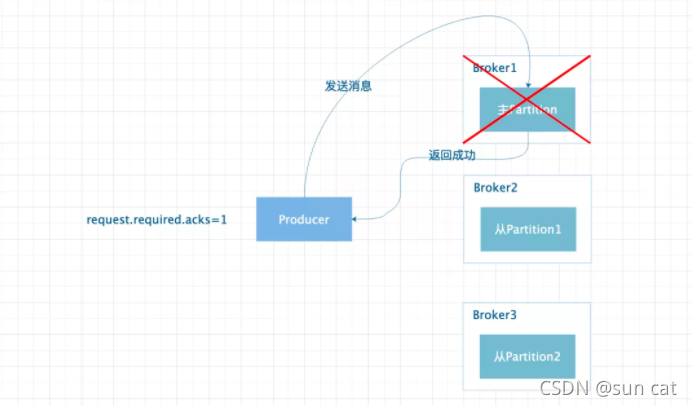
request.required.acks=0。设置为 0 时代表 Producer 发送消息后就认为成功,消息有可能丢失。
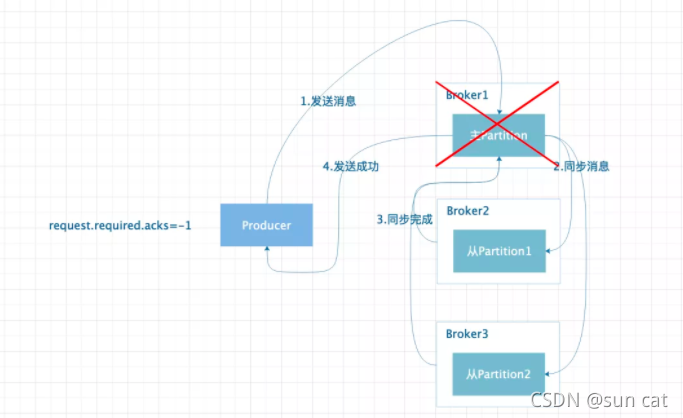
request.required.acks=-1。设置为-1 时,代表 ISR 列表中的所有 Replica 将消息同步完成后才认为消息发送成功;但是如果只存在主 Partition 的时候,Broker 异常时同样会导致消息丢失。所以此时就需要min.insync.replicas参数的配合,该参数需要设定值大于等于 2,当 Partition 的个数小于设定的值时,Producer 发送消息会直接报错。
备注:上面这个过程看似已经很完美了,但是假设如果消息在同步到部分从 Partition 上时,主 Partition 宕机,此时消息会重传,虽然消息不会丢失,但是会造成同一条消息会存储多次。在新版本中 Kafka 提出了幂等性的概念,通过给每条消息设置一个唯一 ID,并且该 ID 可以唯一映射到 Partition 的一个固定位置,从而避免消息重复存储的问题
三、一致性
从 Consumer 端来看,同一条消息在多个 Partition 上读取到的消息是一致的,Kafka 通过引入 HW(High Water)来实现这一特性。
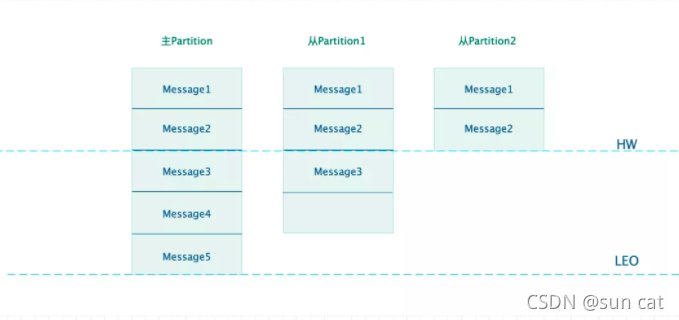
消息同步图
从上图可以看出,假设 Consumer 从主 Partition1 上消费消息,由于 Kafka 规定只允许消费 HW 之前的消息,所以最多消费到 Message2。假设当 Partition1 异常后,Partition2 被选举为 Leader,此时依旧可以从 Partition2 上读取到 Message2。其实 HW 的意思利用了木桶效应,始终保持最短板的那个位置。
从上面我们也可以看出,使用 HW 特性后会使得消息只有被所有副本同步后才能被消费,所以在一定程度上降低了消费端的性能,可以通过设置replica.lag.time.max.ms参数来保证消息同步的最大时间。
四、数据传输的事务
数据传输的事务定义通常有以下三种级别:
(1)最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输
(2)最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输.
(3)精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输
五、实现高吞吐率、以及快
快:kafka 使用了顺序写入和“零拷贝”技术,来达到每秒钟 200w(Apache 官方给出的数据) 的磁盘数据写入量,另外 Kafka 通过压缩数据,降低 I/O 的负担。
Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。
kafka主要使用了以下几个方式实现了超高的吞吐率:
(1)顺序读写:
大家都知道,对于磁盘而已,如果是随机写入数据的话,每次数据在写入时要先进行寻址操作,该操作是通过移动磁头完成的,极其耗费时间,而顺序读写就能够避免该操作。
(2)零拷贝
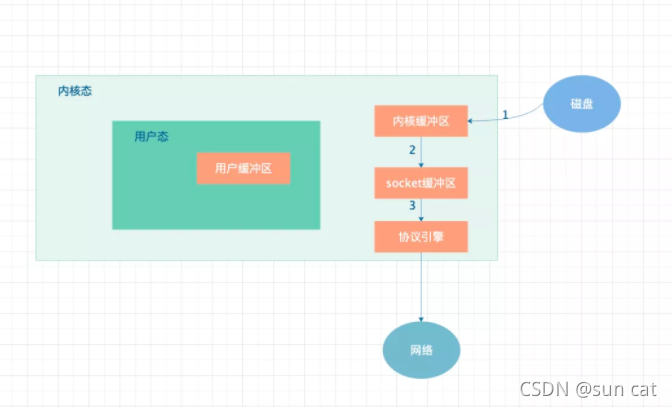
普通的数据拷贝流程如上图所示,数据由磁盘 copy 到内核态,然后在拷贝到用户态,然后再由用户态拷贝到 socket,然后由 socket 协议引擎,最后由协议引擎将数据发送到网络中。
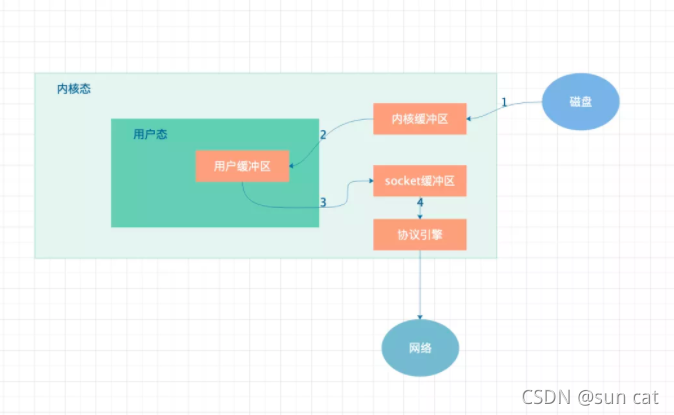
采用了“零拷贝”技术后可以看出,数据不在经过用户态传输,而是直接在内核态完成操作,减少了两次 copy 操作。从而大大提高了数据传输速度。
(3)文件分段
(4)批量发送
(5)数据压缩:
Kafka 官方提供了多种压缩协议,包括 gzip、snappy、lz4 等等,从而降低了数据传输的成本。
六、kafka的message包括哪些信息?
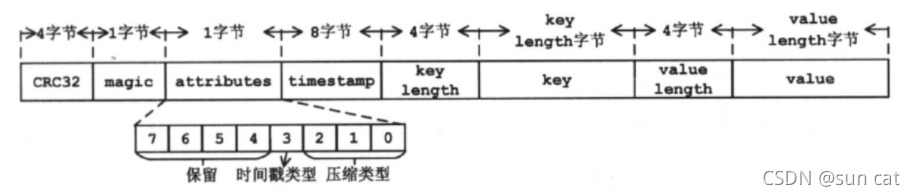
一个 Kafka 的 Message 由一个固定长度的 header 和一个变长的消息体 body 组成
header 部分:由一个字节的 magic(文件格式)和四个字节的 CRC32(用于判断 body 消息体是否正常)构成。
当 magic 的值为 1 的时候,会在 magic 和 crc32 之间多一个字节的数据:attributes(保存一些相关属性,比如是否压缩、压缩格式等等);如果 magic 的值为 0,那么不存在 attributes 属性
body :是由 N 个字节构成的一个消息体,包含了具体的 key/value 消息
(1)CRC32:4个字节,消息的校验码。
(2)magic:1字节,魔数标识,与消息格式有关,取值为0或1。当magic为0时,消息的offset使用绝对offset且消息格式中没有timestamp部分;当magic为1时,消息的offset使用相对offset且消息格式中存在timestamp部分。所以,magic值不同,消息的长度是不同的。
(3)attributes: 1字节,消息的属性。其中第0~ 2位的组合表示消息使用的压缩类型,0表示无压缩,1表示gzip压缩,2表示snappy压缩,3表示lz4压缩。第3位表示时间戳类型,0表示创建时间,1表示追加时间。
(4)timestamp: 时间戳,其含义由attributes的第3位确定。
(5)key length:消息key的长度。
(6)key:消息的key。
(7)value length:消息的value长度。
(8)value:消息的内容
更多内容:


















 1866
1866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











