




 Redis是一个高性能的内存数据库,以其单线程、数据持久化、丰富的数据类型等特点被广泛用于缓存、消息中间件等场景。本文详细介绍了Redis的性能优势、数据类型以及如何在Spring中使用Redis作为缓存,包括RedisTemplate和SpringCache的集成应用。
Redis是一个高性能的内存数据库,以其单线程、数据持久化、丰富的数据类型等特点被广泛用于缓存、消息中间件等场景。本文详细介绍了Redis的性能优势、数据类型以及如何在Spring中使用Redis作为缓存,包括RedisTemplate和SpringCache的集成应用。
一、Redis是什么
- Redis是一个由C 语言开发的一个高性能键值对(key-value)的内存数据库,可以用作数据库、缓存、消息中间件等。
- 它是一种NoSQL(not-only sql,泛指非关系型数据库)的数据库。
特点:
1.性能优越,数据存储在内存中,读写速度非常快,支持10W QPS。
2.单线程单进程,线程是安全的,同时避免了线程上下文的切换带来的损耗。
3.采用多路IO多路复用机制。
4.支持丰富的数据类型:字符串(strings)、散列(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)等。
5.支持数据持久化,可以将内存中数据保存在磁盘中,有RDB和AOF方式。
6.支持主从复制、哨兵模式。
7.另外也可以用作分布式锁、可以作为消息中间件使用、支持发布订阅。
二、Redis为什么这么快
1. 因为Redis完全是基于内存操作,绝大部分请求是纯粹的内存操作,非常迅速,数据存在内存中,类似于HashMap(HashMap的优势就是查找和操作的时间复杂度是O(1))。
2. 采用单线程,避免了不必要的上下文切换和竞争条件,不存在多线程导致的CPU,也不用考虑锁所带来的问题。
(官方解释:因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。)
3. 使用多路复用IO模型,非阻塞IO。
备注:
- 1.为什么Redis在6.0之后加入了多线程(在某些情况下,单线程出现了缺点,多线程可以解决?)
引入多线程说明Redis在有些方面,单线程已经不具有优势了。
因为读写网络的read/write系统调用在Redis执行期间占用了大部分CPU时间,如果把网络读写做成多线程的方式对性能会有很大提升。
Redis的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。之所以这么设计是不想Redis因为多线程而变得复杂,需要去控制key、lua、事务、LPUSH/LPOP等等的并发问题。
举例:
我们知道Redis可以使用del命令删除一个元素,如果这个元素非常大,可能占据几十兆或者是几百兆,那么在短时间内是不能完成的,这样一来就需要多线程的异步支持,现在删除工作可以在后台进行。
三、Redis支持的五种数据类型
首先,Redis内部使用一个redisObject对象来表示所以的key和value。

redisObject最主要的信息有:
1.type:表示一个value对象具体是何种数据类型,一般有5种,在后续讲解。
2.encoding是不同数据类型在Redis内存的存储方式。
比如:type = string表示value存储的是一个普通字符串,那么encoding可以是raw或者int。
- Redis中5种基本数据类型:
| 类型 | 简介 | 特性 | 场景 |
| string (字符串) | 二进制安全 | 可以包含任何数据, 比如jpg图片或者序列化对象 | ... |
| hash (字典) | 键值对集合, 即编程语言中的map类型 | 适合存储对象,并且可以像数据库一样update一个属性 | 存储、读取、修改用户属性 |
| list (列表) | 链表(双向链表) | 增删快,提供了操作某一元素的api | 最新消息排行;消息队列 |
| set (集合) | hash表实现,元素不重复 | 添加、删除、查找的复杂度都是O(1), 提供了求交集、并集、差集的操作 | 共同好友;利用唯一性,统计访问网站的所有ip |
| sorted set (有序集合) | set集合中增加score参数,元素按score有序排序 | 数据插入集合时,已经进行了天然排序 | 排行榜;带权重的消息队列 |
扩展类型:
- HyperLogLog:将数据哈希后分桶统计,结果存储在 String 中。
- Bitmaps:通过
SETBIT、GETBIT等命令操作 String 的二进制位。 - GEO:使用 ZSet 存储经纬度的 GeoHash 编码,通过
GEOADD等命令封装地理计算。
| 扩展数据结构 | 底层实现 | 用途 |
| HyperLogLog | 封装后的 String | 近似基数统计(如UV去重) |
| Bitmaps | String 的位操作 | 布尔标记、位统计 |
| GEO | ZSet + GeoHash | 地理位置存储与查询 |
| Stream | 链表 + 消息队列 | 消息流(类似Kafka) |
Redis基础类型 vs 扩展类型:
| 类别 | 特点 | 示例 |
| 基础类型 | 直接对应存储结构,支持通用操作 | String、List、Hash、Set、ZSet |
| 扩展类型 | 基于基础类型封装,解决特定场景问题 | HyperLogLog、Bitmaps、GEO |
四、Redis缓存使用
- 直接通过 RedisTemplate 来使用,使用 Spring Cache 集成 Redis
(1)pom.xml 中加入以下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
(2)配置文件 application.yml 的配置:
server: port: 8082
servlet: session: timeout: 30ms
spring:cache:type: redis
redis: host: 127.0.0.1
port: 6379
password:# redis默认情况下有16个分片,这里配置具体使用的分片,默认为0
database: 0
lettuce: pool:# 连接池最大连接数(使用负数表示没有限制),默认8
max-active: 100
(3)创建实体类 User.java:
public class User implements Serializable{
private static final long serialVersionUID = 662692455422902539L;
private Integer id;
private String name;
private Integer age;
public User(){ }
public User(Integer id, String name, Integer age){
this.id = id;
this.name = name;
this.age = age;
}
public Integer getId(){
return id;
}
public void setId(Integer id){
this.id = id;
}
public String getName(){
return name;
}
public void setName(String name){
this.name = name;
}public Integer getAge(){
return age;
}
public void setAge(Integer age){
this.age = age;
}
@Override
public String toString(){
return "User{" +"id=" + id +", name='" + name + '\'' +", age=" + age +'}';
}
}
(4.1)RedisTemplate 的使用方式
默认情况下的模板只能支持 RedisTemplate<String, String>,也就是只能存入字符串,所以自定义模板很有必要。
添加配置类 RedisCacheConfig.java:
@Configuration
@AutoConfigureAfter(RedisAutoConfiguration.class)
public class RedisCacheConfig {
@Bean
public RedisTemplate<String, Serializable> redisCacheTemplate(LettuceConnectionFactory connectionFactory) {
RedisTemplate<String, Serializable> template = new RedisTemplate<>();
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
template.setConnectionFactory(connectionFactory);returntemplate;
}
}
测试类:
@RestController
@RequestMapping("/user")
public class UserController{
public static Logger logger = LogManager.getLogger(UserController.class);
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisTemplate<String, Serializable> redisCacheTemplate;
@RequestMapping("/test")
public void test() {
redisCacheTemplate.opsForValue().set("userkey", new User(1, "张三", 25));
User user = (User) redisCacheTemplate.opsForValue().get("userkey");
logger.info("当前获取对象:{}", user.toString());
}
}(4.2)使用 Spring Cache 集成 Redis
Spring Cache 具备很好的灵活性,
不仅能够使用 SPEL(spring expression language)来定义缓存的 Key 和各种 Condition,还提供了开箱即用的缓存临时存储方案,
也支持和主流的专业缓存如 EhCache、Redis、Guava 的集成。
定义接口 UserService.java:
public interface UserService {
User save(User user);
void delete(int id);
User get(Integer id);
}
接口实现类 UserServiceImpl.java:
@Service
public class UserServiceImpl implements UserService{
public static Logger logger = LogManager.getLogger(UserServiceImpl.class);
private static Map<Integer, User> userMap = new HashMap<>();
static {
userMap.put(1, new User(1, "肖战", 25));
userMap.put(2, new User(2, "王一博", 26));
userMap.put(3, new User(3, "杨紫", 24));
}
@CachePut(value ="user", key = "#user.id")
@Override
public User save(User user){
userMap.put(user.getId(), user);
logger.info("进入save方法,当前存储对象:{}", user.toString());
return user;
}
@CacheEvict(value="user", key = "#id")
@Override public void delete(int id){
userMap.remove(id);
logger.info("进入delete方法,删除成功");
}
@Cacheable(value = "user", key = "#id")
@Override public User get(Integer id){
logger.info("进入get方法,当前获取对象:{}", userMap.get(id)==null?null:userMap.get(id).toString());
return userMap.get(id);
}
}
为了方便演示数据库的操作,这里直接定义了一个 Map<Integer,User> userMap。
这里的核心是三个注解:
@Cachable@CachePut@CacheEvict
测试类:UserController
@RestController
@RequestMapping("/user")
public class UserController{
public static Logger logger = LogManager.getLogger(UserController.class);
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisTemplate<String, Serializable> redisCacheTemplate;
@Autowired
private UserService userService;
@RequestMapping("/test")
public void test(){
redisCacheTemplate.opsForValue().set("userkey", new User(1, "张三", 25));
User user = (User) redisCacheTemplate.opsForValue().get("userkey");
logger.info("当前获取对象:{}", user.toString());
}
@RequestMapping("/add")
public void add(){
User user = userService.save(new User(4, "李现", 30));
logger.info("添加的用户信息:{}",user.toString());
}
@RequestMapping("/delete")
public void delete(){
userService.delete(4);
}
@RequestMapping("/get/{id}")
public void get(@PathVariable("id") String idStr) throws Exception{
if (StringUtils.isBlank(idStr)) {
thrownew Exception("id为空");
}
Integer id = Integer.parseInt(idStr);
User user = userService.get(id);
logger.info("获取的用户信息:{}",user.toString());
}
}
用缓存要注意,启动类要加上一个注解开启缓存:
@SpringBootApplication(exclude=DataSourceAutoConfiguration.class)
@EnableCaching
public class Application{
public static void main(String[] args){
SpringApplication.run(Application.class, args);
}
}
备注:
1)为什么使用redis做缓存而不是其他的消息队列如kafka?
核心功能与设计目标不同
| 维度 | Redis | Kafka |
| 核心用途 | 高速缓存、键值存储、实时数据访问 | 高吞吐量消息队列、流数据处理、日志聚合 |
| 数据时效性 | 毫秒级延迟,适合实时读写 | 高吞吐但延迟较高(通常毫秒到秒级) |
| 数据存储 | 内存为主,支持持久化 | 磁盘持久化,长期存储海量数据 |
| 数据结构 | 支持丰富数据结构(字符串、哈希、列表等) | 仅支持字节流,需应用层解析 |
| 消费模式 | 直接通过键访问 | 基于消费者组的顺序或并行拉取 |
2)设计redis的key和value上,有哪些原则
1)Key 的设计原则
- 可读性:Key 应易于理解,清晰表达其所关联的值的意义。例如,使用 user:basic.info:userid:string 这样的命名方式,通过在名称中包含值类型来增强可读性。
- 简洁性:保持 Key 简短但有意义,以节省内存并提高性能。避免过于简略导致与其他 Key 冲突。
- 字符限制:避免使用特殊字符,确保 Key 易于阅读和操作。建议仅使用大小写字母、数字及特定符号(如竖线、下划线、英文点号“.”和英文冒号“:”)。
- 命名空间:利用前缀创建命名空间,区分不同类型的数据。比如,用户数据可用 user: 开头,缓存数据则用 cache: 前缀。
- 长度控制:避免过长的 Key 名称,以免占用过多内存。
2)Value 的设计原则
- 数据类型选择:根据数据特点选择最合适的 Redis 数据类型(如字符串、列表、哈希、集合或有序集合),以优化操作效率。
- 避免大Value:尽量避免存储过大的 Value,因为这可能导致性能问题。考虑将大数据分割为多个小 Value 以提高处理速度和降低内存消耗。
- 设置过期时间:为 Value 定义适当的过期时间,以便自动清理不再需要的数据,减少内存占用。
- 压缩数据:对于可压缩的数据,在存储之前进行压缩可以有效减少内存使用。
- 数据结构内存编码优化:合理配置数据结构的内存编码。例如,ziplist 对于小型列表、哈希表和有序集合特别有效,因为它允许这些结构共享连续的内存块。然而,由于 ziplist 缺乏索引支持,频繁的查找、插入或删除操作可能会导致性能下降。因此,应基于实际需求评估是否采用 ziplist 或其他更合适的数据结构。
3)Redis中多大的key算热key,该如何解决,怎么避免热点问题
3-1)热key的识别
- 单个key的QPS远高于其他Key(如超过1000QPS)
- 某个Key的请求量占集群总请求量的5%~10%以上
3-2)如何识别热key
redis-cli --hotkeys
使用 Redis 自带的命令(需开启 LFU 算法,maxmemory-policy配置为allkeys-lfu或volatile-lfu)。- 第三方监控工具
如 Prometheus + Grafana、Redis 的INFO命令统计、商业监控工具(如阿里云 DAS)。
3)解决方案
3-1)本地缓存(Local Cache)
原理:将热 Key 数据缓存在应用服务器的本地内存(如 Guava Cache、Caffeine),减少直接访问 Redis 的次数。
注意事项:
设置合理的过期时间,避免数据不一致。
3-2)数据分片(Sharding)
原理:将热 Key 拆分为多个子 Key,分散到不同节点。例如:
hot_key → hot_key:1、hot_key:2、hot_key:3实现方式:客户端一致性哈希:根据用户 ID 或随机数选择子 Key。
3-3)限流与降级(Rate Limiting & Degradation)
原理:对热 Key 的请求限流,或在极端情况下返回降级内容(如默认值)。
工具:使用 Sentinel、Hystrix 等框架实现熔断机制。
3-4)读写分离(Read/Write Splitting)
原理:通过 Redis 主从架构,将读请求分流到从节点。
优化:使用 Redis Cluster 或 Sentinel 自动管理读写分离。
4)Redis的zset的原理
底层分别使用ziplist(压缩链表)和skiplist(跳表)实现。
4-1)当zset满足以下两个条件的时候,使用ziplist:
1. 保存的元素少于128个
2. 保存的所有元素大小都小于64字节4-2)不满足这两个条件则使用skiplist。
压缩链表:就是将元素值按照分值从小到大排列
跳表:除了常规的双向链表,还增加了一个分层数据结构,随机设置跳转层数,主打随意跳转至目前前后。
5)如何用Redis统计亿级网站的UV?
使用HyperLogLog
HyperLogLog 是一种概率数据结构,用于估计集合的基数。每个 HyperLogLog 最多只需要花费 12KB 内存,在标准误差 0.81%的前提下,就可以计算 2 的 64 次方个元素的基数。
HyperLogLog 的优点在于它所需的内存并不会因为集合的大小而改变,无论集合包含的元素有多少个,HyperLogLog 进行计算所需的内存总是固定的,并且是非常少的。
主要特点如下。
- 高效的内存使用:HyperLogLog 的内存消耗是固定的,与集合中的元素数量无关。这使得它特别适用于处理大规模数据集,因为它不需要存储每个不同的元素,只需要存储估计基数所需的信息。
- 概率估计:HyperLogLog 提供的结果是概率性的,而不是精确的基数计数。它通过哈希函数将输入元素映射到位图中的某些位置,并基于位图的统计信息来估计基数。由于这是一种概率性方法,因此可能存在一定的误差,但通常在实际应用中,这个误差是可接受的。
- 高速计算:HyperLogLog 可以在常量时间内计算估计的基数,无论集合的大小如何。这意味着它的性能非常好,不会受到集合大小的影响。
6)zset底层原理
Redis 的 zset 由两种数据结构组合实现:
1)如果有序集合的成员个数小于 128 个,并且每个成员的值小于 64 字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构;
2)如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;6-1)压缩列表(ziplist)(在Redis7.0中,压缩列表数据结构已经废弃,交由listpack数据结构来实现了)
结构:ziplist 是一种紧凑的连续内存块结构,在存储 ZSet 时,元素按照分数从小到大的顺序排列,成员和分数依次交替存储在内存中,每个节点包含前一个节点的长度、当前节点的长度以及具体的数据内容。
优点:在元素数量较少且元素大小较小时,内存使用效率极高,因为它避免了指针带来的额外内存开销,并且是连续存储,缓存命中率高。
缺点:插入和删除操作可能会导致大量的数据移动,时间复杂度为 O (n);查找元素也需要遍历整个列表,效率较低;同时,存在连锁更新问题,即一个节点的长度变化可能引发后续多个节点的更新,影响性能。
6-2)Listpack
结构:Listpack 同样是紧凑的连续内存结构,它改进了 ziplist 的节点布局,去除了记录前一个节点长度的字段,每个节点只包含自身长度和数据内容,使得结构更加紧凑。
优点:解决了 ziplist 的连锁更新问题,在插入和删除操作上性能有所提升;并且内存使用效率进一步提高,能够更有效地存储数据。
缺点:和 ziplist 类似,当元素数量增多时,查找操作仍需要遍历列表,时间复杂度为 O (n),对于大规模数据的操作性能不如 skiplist。
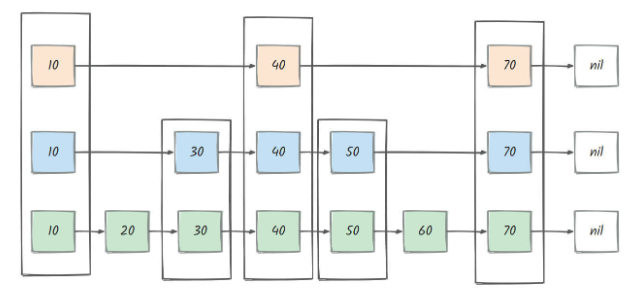
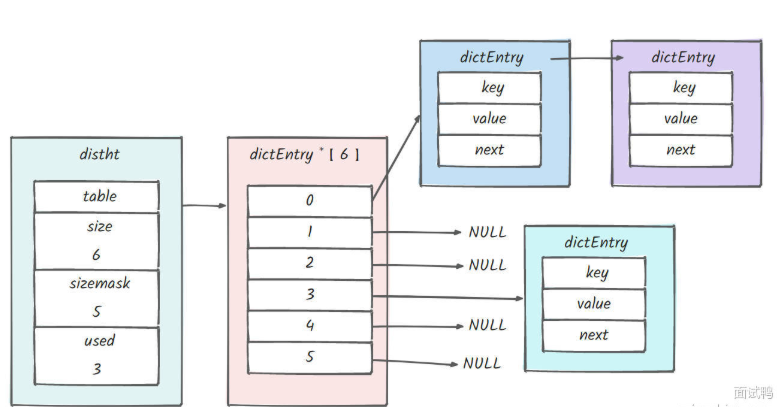
6-3)跳表(skiplist)+ 哈希表(hashtable)
结构:跳表是一种基于链表的有序数据结构,每个节点包含元素的成员、分数以及多层指针,通过这些多层指针可以快速跳过一些节点,从而提高查找效率;同时,搭配一个哈希表,用于存储元素成员和分数的映射关系。
优点:插入、删除和查找操作的平均时间复杂度为 O (log n),能够高效地处理大量数据;支持范围查询,可以快速获取指定分数范围内的元素;并且实现相对简单,易于维护。
缺点:相比于 ziplist 和 Listpack,内存占用较大,因为每个节点需要额外的指针空间;哈希表也需要一定的内存开销;而且在元素数量较少时,其性能优势不明显,会有额外的内存和性能损耗。
跳表:
哈希表:
注意:在Redis7.0中,压缩列表数据结构已经废弃,交由listpack数据结构来实现了。
Redis讲解目录:


















 546
546



 到【灌水乐园】发言
到【灌水乐园】发言










