






 本文探讨了Spark shuffle过程中的性能优化,包括设置`spark.shuffle.consolidateFiles`为true来合并文件,调整`spark.reducer.maxSizeInFlight`、`spark.shuffle.file.buffer`等参数以优化内存和磁盘使用,以及重试策略。通过合理配置,可以有效减少磁盘IO,提升任务执行效率。
本文探讨了Spark shuffle过程中的性能优化,包括设置`spark.shuffle.consolidateFiles`为true来合并文件,调整`spark.reducer.maxSizeInFlight`、`spark.shuffle.file.buffer`等参数以优化内存和磁盘使用,以及重试策略。通过合理配置,可以有效减少磁盘IO,提升任务执行效率。
一、shuffle性能优化,配置项
new SparkConf().set("spark.shuffle.consolidateFiles", "true")
spark.shuffle.consolidateFiles:是否开启shuffle block file的合并,默认为false
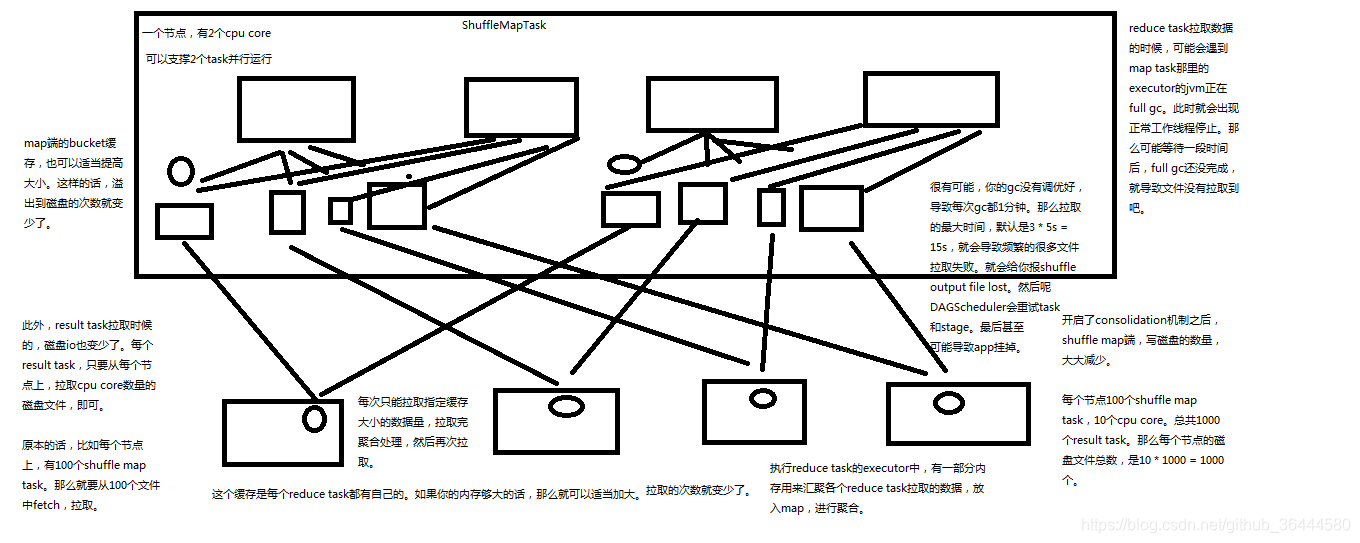
spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m
spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k
spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次
spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s
spark.shuffle.memoryFraction:用于reduce端聚合的内存比例,默认0.2,超过比例就会溢出到磁盘上
注:开启considation对磁盘io的优化
二、流程中调优

















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









