



 本文档详细介绍了如何在C++项目中编译和使用kenlm语言模型库,包括依赖库的安装、CMakelists.txt的修改以及解决编译问题。同时,提到了在自己工程中使用kenlm时的CMakeLists.txt编写注意事项。
本文档详细介绍了如何在C++项目中编译和使用kenlm语言模型库,包括依赖库的安装、CMakelists.txt的修改以及解决编译问题。同时,提到了在自己工程中使用kenlm时的CMakeLists.txt编写注意事项。
语言模型kenlm库的编译及C++接口使用
简介
近期需要使用语言模型对句子打分,因此需要用到第三方开源库kenlm,在此记录下使用过程。因为python下使用kenlm比较简单,这里就不做介绍了,本博客主要针对将kenlm编译到自己工程中的方法做一个大致记录。
源码编译
kenlm编译需要依赖几个库,如下:
zlib、bzip2、Boost、xz
具体详见:
https://kheafield.com/code/kenlm/dependencies/
依赖库安装
- boost安装
下载boost_1_62_0.tar.gz并解压
./bootstrap.sh
./b2 install - zlib安装
下载xz-5.2.2.tar.gz并解压
cd xz-5.2.2
./configure
make
make install - zlib安装
下载 zlib-1.2.11.tar.gz并解压
cd zlib-1.2.11
./configure
make
make install - bzip2安装
下载bzip2-1.0.6.tar.gz并解压
cd bzip2-1.0.6/
make
make install
修改CMakelist.txt
kenlm源码默认编译生成静态库文件,如下所示:

为了方便在自己项目中使用,需要修改自带的CMakelist.txt文件,编译成动态库文件
如下所示:

具体步骤如下:
在安装完依赖库后,修改kenlm源码中的CMakelist.txt文件,一共需要修改四个,路径分别为
kenlm/lm/CMakeLists.txt、kenlm/lm/filter/CMakeLists.txt、kenlm/lm/builder/CMakeLists.txt、kenlm/util/CMakeLists.txt
修改add_library()命令,示例如下:
add_library(kenlm_builder ${KENLM_BUILDER_SOURCE}) 改为add_library(kenlm_builder SHARED ${KENLM_BUILDER_SOURCE})
将生成静态库的都改为动态库
注意
编译时可能会报错误:

这是因为编译libbz2.a时没有采用 -fPIC
解决方法:修改 zlib-1.2.11/Makefile文件,将CFLAGS行改为如下:
CFLAGS=-Wall -Winline -O2 -g -fPIC $(BIGFILES)
并重新编译。
最后编译kenlm源码
mkdir build
cd build
cmake ..
make
在build/lib文件夹下生成对应的四个so文件。
自己工程中使用kenlm时cmakelist编写
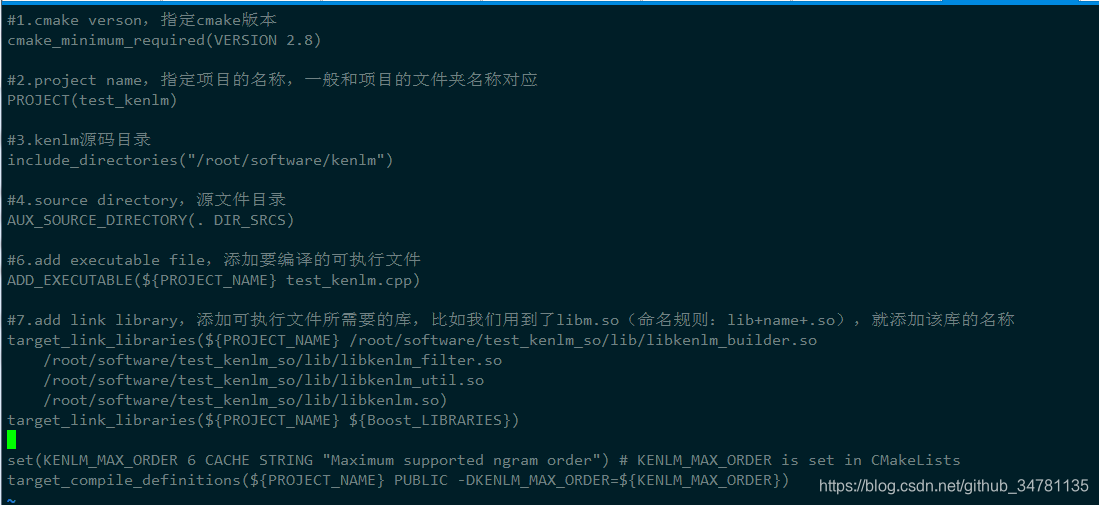
NOTE
最后需要注意的是,CMakeList.txt中最后两行必不可少。如果不加,会在编译中遇到一个问题,即报错KENLM_MAX_ORDER没有定义。实际上该宏需要由Makefile来定义,使用的时候需要定义成跟编译kenlm时设置的一样,默认KENLM_MAX_ORDER为6。
C++接口测试
#include<iostream>
#include <set>
#include "lm/model.hh"
#include "lm/config.hh"
#include "util/tokenize_piece.hh"
#include "util/string_piece.hh"
#include "util/string_stream.hh"
using namespace std;
using namespace lm::ngram;
int main(int argc, char *argv[]) {
char *path = "./model/chinese.bin";
if (argc > 1) {
path = argv[1];
}
Config config;
config.load_method = util::READ;
Model model(path,config);
State state, out_state;
lm::FullScoreReturn ret;
float score;
const Vocabulary &vocab = model.GetVocabulary();
string line;
while (getline(cin, line)) {
state = model.BeginSentenceState();
score = 0;
for (util::TokenIter<util::SingleCharacter, true> it(line, ' '); it; ++it) {
lm::WordIndex vocab = model.GetVocabulary().Index(*it);
ret = model.FullScore(state, vocab, out_state);
score += ret.prob;
state = out_state;
}
ret = model.FullScore(state, model.GetVocabulary().EndSentence(), out_state);
score += ret.prob;
cout<<line.c_str()<<":"<<score<<"\n";
}
return 0;
}
参考资料
https://kheafield.com/code/kenlm/dependencies/
https://blog.youkuaiyun.com/luoyexuge/article/details/82109526
https://blog.youkuaiyun.com/suan2014/article/details/88535776

















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









