




 论文探讨了多视图学习在计算机视觉中的应用,通过深度嵌入和交互信息提升分类性能。研究了包括拼接、投影变换和监督扩展在内的多种方法,并提出了一种新的深度学习投影变换策略,利用神经网络捕捉视图间的互补和互动信息。通过多视图损失融合优化过程,实现在多个数据集上优于现有方法的实验结果。
论文探讨了多视图学习在计算机视觉中的应用,通过深度嵌入和交互信息提升分类性能。研究了包括拼接、投影变换和监督扩展在内的多种方法,并提出了一种新的深度学习投影变换策略,利用神经网络捕捉视图间的互补和互动信息。通过多视图损失融合优化过程,实现在多个数据集上优于现有方法的实验结果。
论文笔记
最近看到了这篇文章,觉得可以拿来参考,先做个阅读笔记记录一下。
论文阅读
先附上论文地址
内容简介
论文背景介绍,如果是熟悉多视图学习的可以跳过。
多视图学习
多视图学习通过充分利用互补视图来进一步改进各种计算机视觉应用的性能,不同视图之间的深入交互信息以及融合。多视图是指对象的多种不同表示形式,并全面地描述了对象的所有信息。在实际应用中,许多对象具有一组以多种视图形式呈现的不同且互补的表示形式。(简单点比喻,一张RGB图片3个通道都能认为是3个视图。)
拼接
一种比较原始直接的做法就是把多个视图数据拼成一个文件然后计算。这样做有两个缺点:
- 忽略了视图间的相互信息
- 没有体现不同视图不同的重要程度
投影变换
除了上面原始的做法之外,还有人提出了投影变换的方法。对于一对(2个)视图,学习两个投影矩阵使两个视图投影后结果互相关性最大,或者以通过最大化所有成对视图的总相关性来获得多个变换。比起直接拼接该方法利用了视图间的相互信息,然而它是无监督的,可能导致获得的转换不利于分类。
监督扩展
针对上述投影无监督的缺点就有人提出了一个改进方向,就是利用LDA(线性判别,可以当做二分类模型,也可以认为是把数据降维到class_num-1维的降维方法)的方法学习线性变换来找到可区分的公共空间。但是,这些基于LDA的方法在某些具有挑战性的方案中无法捕获某些微妙但重要的结构。
深度学习投影变换
研究表明利用更灵活的深度神经网络来学习非线性表示可以实现更高的性能。用深层的神经网络来学习这个投影变换。有深度LDA的,也有共同训练多个网络以让它们相似的,还有借用VAE架构,让视图之间的重构结果相似,以及利用核方法的。

主要方法和策略
该文章的创新思想为:
- 输入基于多个神经网络,从不同实体视图提取的各种特征。从不同实体视图提取的各种特征。(个人感觉像风格迁移从不同网络提取中间输出当输入一样)
- 考虑了由深度共享的互动子网传递的互动信息,其中互动信息是由不同视图之间的属性互相关而产生的,显式地建模视图之间的关系
- 模型框架为多视点计算多个损失,并以自适应加权方式将其融合,在训练过程中可以学习权重并灵活调整权重
模型结构
先把结构图放出来,按照图分部分说明
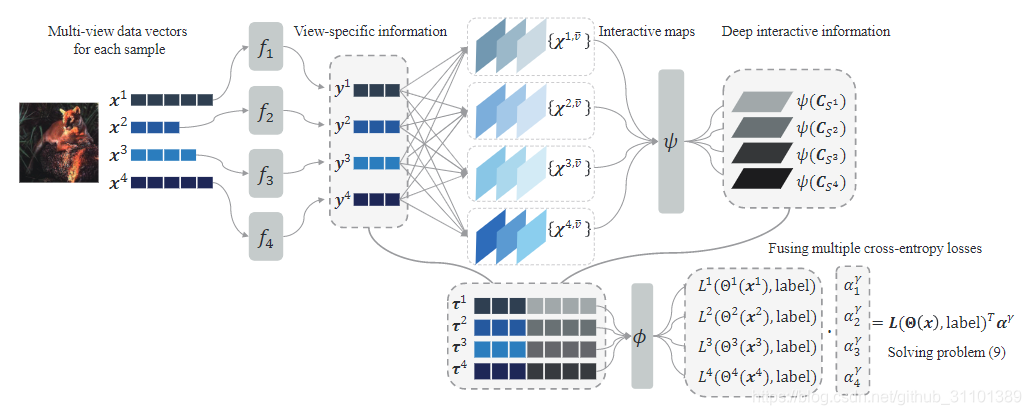
预处理多视图数据

不同视图的原始数据可能不同维度(尺寸),我们用不同的神经网络提取特征的同时可以把他们放到同一维度。也就是模型结构的开头部分。

成对交互信息
经过预处理之后,假设每个视图的数据都变成d维了。对于两个不同的视图 v v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









