




 本文档详细记录了使用PyTorch构建图片描述生成模型的过程,包括模型结构(ResNet+LSTM)、数据预处理、特征提取和主程序流程。ResNet用于提取图像的2048维特征,LSTM生成图片描述。数据预处理涉及中文分词、词频过滤和长度调整。在`feature_extract`步骤中,利用预训练的resnet50获取图像特征,确保特征与原始图像索引对应。主程序则重点在于训练LSTM并测试生成描述。
本文档详细记录了使用PyTorch构建图片描述生成模型的过程,包括模型结构(ResNet+LSTM)、数据预处理、特征提取和主程序流程。ResNet用于提取图像的2048维特征,LSTM生成图片描述。数据预处理涉及中文分词、词频过滤和长度调整。在`feature_extract`步骤中,利用预训练的resnet50获取图像特征,确保特征与原始图像索引对应。主程序则重点在于训练LSTM并测试生成描述。
Pytorch学习笔记-第十章图像描述
记录一下个人学习和使用Pytorch中的一些问题。强烈推荐 《深度学习框架PyTorch:入门与实战》.写的非常好而且作者也十分用心,大家都可以看一看,本文为学习第十章图像描述的学习笔记。
主要分析实现代码里面main,data,data_preprocess,feature_extract这5个文件完成整个项目模型结构定义,训练及生成,还有输出展示的整个过程。
model
整个工作的模型如下。左边是卷积网络,实现代码里面用的是resnet,用来处理输入图片,获取高层特征;右边是LSTM,用来生成图片的描述(具体过程类似第9章里生成诗歌的过程)。
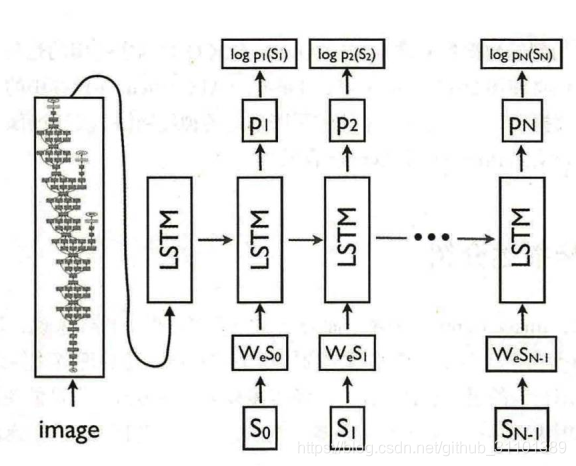
其中图片经过resnet处理之后会变成2048维的一个向量,最后经过一个fc层变成和词向量一样的256维数据作为LSTM的第一个输入去预测图片的描述。
data_preprocess
原始的图片描述数据是JSON结构化文件,为了方便后续使用,该部分代码进行一些预处理,进行中文分词,以及丢弃词频不够的词,丢弃长度过长的词,最后生成编号和词语互相对应以及图片编号和描述编号互相对应的字典。
data
由于不同的描述可能长度不一样,真正使用之前需要补齐成同一长度。
for i, c in enumerate(caps):
end_cap = lengths[i] - 1
if end_cap < batch_length:
cap_tensor[end_cap, i] = eos
cap_tensor[:end_cap, i].copy_(c[:end_cap])
return (imgs, (cap_tensor, lengths), indexs)
然后因为同时需要图像和描述信息,需要把两者放在同一个数据里面,需要借用字典维护对应关系。
feature_extract
处理图像的输入,用pytorch内置的resnet50卷积处理图像,把最后fc分类层之前的2048维向量提取出来保存。需要注意的是这部分处理数据过程需要一个dataloder,注意不要加shuffer,保证提取出的特征和原始图片index的对应关系。
# 模型
resnet50 = tv.models.resnet50(pretrained=True)
del resnet50.fc
#删除最好的fc层,换成一个恒等映射
resnet50.fc = lambda x: x
resnet50.cuda()
main
需要过程大同小异,因为左边卷积网络是预训练好了的,我们也只要训练右边的LSTM,其实也就是第九章诗歌一样的预测分类问题。
for ii, (imgs, (captions, lengths), indexes) in tqdm.tqdm(enumerate(dataloader)):
# 训练
optimizer.zero_grad()
imgs = imgs.to(device)
captions = captions.to(device)
input_captions = captions[:-1]
target_captions = pack_padded_sequence(captions, lengths)[0]
#模型同时需要图片和描述信息
score, _ = model(imgs, input_captions, lengths)
loss = criterion(score, target_captions)
loss.backward()
optimizer.step()
loss_meter.add(loss.item())
测试生成图片描述则是借用了beam search算法以得到更好的描述
(下面函数在model.py文件中,main文件处理了输入后调用它)
def generate(self, img, eos_token='</EOS>',
beam_size=3,
max_caption_length=30,
length_normalization_factor=0.0):
"""
根据图片生成描述,主要是使用beam search算法以得到更好的描述
"""
cap_gen = CaptionGenerator(embedder=self.embedding,
rnn=self.rnn,
classifier=self.classifier,
eos_id=self.word2ix[eos_token],
beam_size=beam_size,
max_caption_length=max_caption_length,
length_normalization_factor=length_normalization_factor)
if next(self.parameters()).is_cuda:
img = img.cuda()
img =img.unsqueeze(0)
img = self.fc(img).unsqueeze(0)
sentences, score = cap_gen.beam_search(img)
sentences = [' '.join([self.ix2word[idx] for idx in sent])
for sent in sentences]
return sentences

















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









